IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019
Speech2Face: Learning the Face Behind a Voice
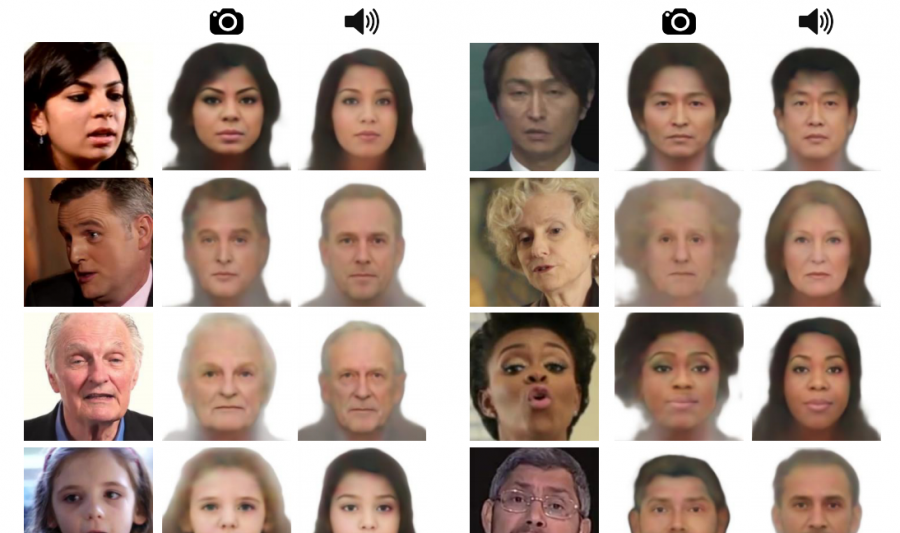
We consider the task of reconstructing an image of a person’s face from a short input audio segment of speech. We show several results of our method on VoxCeleb dataset. Our model takes only an audio waveform as input (the true faces are shown just for reference) . Note that our goal is not to reconstruct an accurate image of the person, but rather to recover characteristic physical features that are correlated with the input speech. *The three authors contributed equally to this work.
How much can we infer about a person's looks from the way they speak? In this paper, we study the task of reconstructing a facial image of a person from a short audio recording of that person speaking. We design and train a deep neural network to perform this task using millions of natural videos of people speaking from Internet/Youtube. During training, our model learns audiovisual, voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity. This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. Our reconstructions, obtained directly from audio, reveal the correlations between faces and voices. We evaluate and numerically quantify how--and in what manner--our Speech2Face reconstructions from audio resemble the true face images of the speakers.
Supplementary Material
Ethical Considerations
Further Reading
Acknowledgment
Google Research Blog

Speech2Face
When we hear a voice on the radio or the phone, we often build a mental model for the way that person looks. Is that sort of intuition something that computers can develop too?
A team led by researchers from MIT’s Computer Science and Artificial Intelligence Lab (CSAIL) have recently shown that it can: they’ve created a new system that can produce a predicted image of someone’s face from hearing them talk for only five seconds.

Trained on millions of YouTube clips featuring over 100,000 different speakers, Speech2Face listens to audio of speech and compares it to other audio it’s heard. It can then create an image based on the facial characteristics most common to similar audio clips. The system was found to predict gender with ___ percent accuracy, age with , ___ percent accuracy, and race with ____ percent accuracy.
On top of that, the researchers even found correlations between speech and jaw shape - suggesting that Speech2Face could help scientists glean insights into the physiological connections between facial structure and speech. The team also combined Speech2Face with Google’s personalized emoji app to create “Speech2Cartoon,” which can turn the predicted face from live-action to cartoon.

Does not support

Speech2Face: Learning the Face Behind a Voice
Reviewed on May 30, 2019 by Antoine Théberge • https://arxiv.org/pdf/1905.09773v1.pdf
Reference : Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Wojciech Matusik. Speech2Face: Learning the Face Behind a Voice. CVPR 2019.
- Successfully recognize general physical traits such as gender, age, and ethnicity from a voice clip
Introduction
“ How much can we infer about a person’s looks from the way they speak? ”. In this paper, the authors reconstruct a “canonical” (front facing, neutral expression, uniformly lit) face from a 6 seconds voice clip using a voice encoder.

The idea is really simple: You take a pre-trained face synthetiser [1] network. You then train a voice encoder to match its last feature vector \(v_s\) with the face synthesiser \(v_f\). If the two encoders project in a similar space, the face decoder should decode similar faces.
A natural choice for a loss would be the \(L_1\) distance between the \(v_s\) and \(v_f\). However, the authors found that the training was slow and unstable. They, therefore, used the following loss:

where \(f_{dec}\) is the first layer of the face decoder and \(f_{VGG}\) the last layer of the face encoder.
The authors used the AVSpeech dataset and extracted 1 frame and a 6 seconds audio clip from each video clip. If the video clip was shorter than six seconds, they looped it. The audio clip was then turned into a spectrogram and fed to the speech encoder.
The authors tested both qualitatively and quantitatively their model on the AVSpeech and VoxCeleb dataset.
Qualitative results are available here
For quantitative results, the authors used Face++ to compare features from the original images and the reconstructed faces. The Face++ classifiers return either “male” or “female” for gender, a continuous number for age, and one of the four values, “Asian”, “black”, “India”, or “white”, for ethnicity. The corresponding confusion matrices are available below

The authors also extracted craniofacial attributes from the reconstructed F2F and S2F images that resulted in a high correlation between the two.

They also performed top-5 recognition to determine how much you could retrieve the true speaker from the reconstructed image.

Supplementary results are aailable here
Conclusions
The authors showed that they can recover physical features from a person’s speech fairly well.
The authors stress throughout the paper, including in an “Ethical Considerations” section that a person’s true identity cannot be recovered from this.
To quote the paper:
More specifically, if a set of speakers might have vocal-visual traits that are relatively uncommon in the data, then the quality of our reconstructions for such cases may degrade. For example, if a certain language does not appear in the training data, our reconstructions will not capture well the facial attributes that may be correlated with that language. Note that some of the features in our predicted faces may not even be physically connected to speech, for example, hair color or style. However, if many speakers in the training set who speak in a similar way (e.g., in the same language) also share some common visual traits (e.g., common hair color or style), then those visual traits may show up in the predictions.
A similar paper has also emerged recently from Carnegie Mellon, but in this case, the authors use GANs to generate the images.
The hacker news thread has some interesting discussions, like different physiological features like overbite, size of vocal tracts, etc. could have been predicted instead. Also, the implications of this paper in the field of sociolinguistics; to understand how the model could predict that a certain speaker has a goatee, for example.
[1]: Synthesizing Normalized Faces from Facial Identity Features , Cole et. al, 2017
Speech2Face: Neural Network Predicts the Face Behind a Voice
- 27 May 2019
In a paper published recently, researchers from MIT’s Computer Science & Artificial Intelligence Laboratory have proposed a method for learning a face from audio recordings of that person speaking.
The goal of the project was to investigate how much information about a person’s looks can be inferred from the way they speak. Researchers proposed a neural network architecture designed specifically to perform the task of facial reconstruction from audio.
They used natural videos of people speaking collected from Youtube and other internet sources. The proposed approach is self-supervised and researchers exploit the natural synchronization of faces and speech in videos to learn the reconstruction of a person’s face from speech segments.

In their architecture, researchers utilize facial recognition pre-trained models as well as a face decoder model which takes as an input a latent vector and outputs an image with a reconstruction.
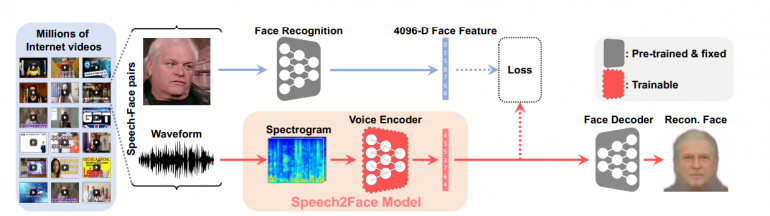
From the videos, they extract speech-face pairs, which are fed into two branches of the architecture. The images are encoded into a latent vector using the pre-trained face recognition model, whilst the waveform is fed into a voice encoder in a form of a spectrogram, in order to utilize the power of convolutional architectures. The encoded vector from the voice encoder is fed into the face decoder to obtain the final face reconstruction.
The evaluations of the method show that it is able to predict plausible faces with consistent facial features with the ones from real images. Researchers created a page with supplementary material where sample outputs of the method can be found. The paper was accepted as a conference paper at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019.

[…] Neurohive discussed their work: “From the videos, they extract speech-face pairs, which are fed into two branches of the architecture. The images are encoded into a latent vector using … Read more »

Speech2Face: Learning the Face Behind a Voice

How much can we infer about a person's looks from the way they speak? In this paper, we study the task of reconstructing a facial image of a person from a short audio recording of that person speaking. We design and train a deep neural network to perform this task using millions of natural Internet/YouTube videos of people speaking. During training, our model learns voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity. This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how–and in what manner–our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.

Tae-Hyun Oh

Changil Kim

Inbar Mosseri

William T. Freeman
Michael Rubinstein
Wojciech Matusik

Related Research
Reconstructing faces from voices, imaginary voice: face-styled diffusion model for text-to-speech, physical attribute prediction using deep residual neural networks, crossmodal voice conversion, apb2face: audio-guided face reenactment with auxiliary pose and blink signals, whose emotion matters speaker detection without prior knowledge, the criminality from face illusion.
Please sign up or login with your details
Generation Overview
AI Generator calls
AI Video Generator calls
AI Chat messages
Genius Mode messages
Genius Mode images
AD-free experience
Private images
- Includes 500 AI Image generations, 1750 AI Chat Messages, 30 AI Video generations, 60 Genius Mode Messages and 60 Genius Mode Images per month. If you go over any of these limits, you will be charged an extra $5 for that group.
- For example: if you go over 500 AI images, but stay within the limits for AI Chat and Genius Mode, you'll be charged $5 per additional 500 AI Image generations.
- Includes 100 AI Image generations and 300 AI Chat Messages. If you go over any of these limits, you will have to pay as you go.
- For example: if you go over 100 AI images, but stay within the limits for AI Chat, you'll have to reload on credits to generate more images. Choose from $5 - $1000. You'll only pay for what you use.
Out of credits
Refill your membership to continue using DeepAI
Share your generations with friends
- Publications
CDFG The Computational Design & Fabrication Group
Speech2face: learning the face behind a voice, publication.
Tae-Hyun Oh*, Tali Dekel*, Changil Kim*, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Wojciech Matusik (* Equally contributed)

Help | Advanced Search
Computer Science > Computer Vision and Pattern Recognition
Title: speech2face: learning the face behind a voice.
Abstract: How much can we infer about a person's looks from the way they speak? In this paper, we study the task of reconstructing a facial image of a person from a short audio recording of that person speaking. We design and train a deep neural network to perform this task using millions of natural Internet/YouTube videos of people speaking. During training, our model learns voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity. This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how--and in what manner--our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.
Submission history
Access paper:.
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
DBLP - CS Bibliography
Bibtex formatted citation.
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
NVIDIA Audio2Face
Instantly create expressive facial animation from just an audio source using generative AI.
System Requirements | Setup Guide
Audio-to-Animation Made Easy With Generative AI
NVIDIA Audio2Face beta is a foundation application for animating 3D characters facial characteristics to match any voice-over track, whether for a game, film, real-time digital assistant, or just for fun. You can use the Universal Scene Description (OpenUSD) -based app for interactive real-time applications or as a traditional facial animation authoring tool. Run the results live or bake them out, it’s up to you.
How It Works
Audio2Face is preloaded with “Digital Mark”— a 3D character model that can be animated with your audio track, so getting started is simple—just select your audio and upload. The audio input is then fed into a pre-trained Deep Neural Network and the output drives the 3D vertices of your character mesh to create the facial animation in real-time. You also have the option to edit various post-processing parameters to edit the performance of your character. The results you see on this page are mostly raw outputs from Audio2Face with little to no post-processing parameters edited.
Audio Input
Use a recording, or animate live.
Simply record a voice audio track, input into the app, and see your 3D face come alive . You can even generate facial animations live using a microphone.
Audio2Face will be able to process any language easily. And we’re continually updating with more and more languages.
Character Transfer
Face-swap in an instant.
Audio2Face lets you retarget to any 3D human or human-esque face, whether realistic or stylized. This makes swapping characters on the fly—whether human or animal—take just a few clicks.
Scale Output
Express yourself—or everyone at once.
It’s easy to run multiple instances of Audio2Face with as many characters in a scene as you like - all animated from the same, or different audio tracks. Breathe life and sound into dialogue between a duo, a sing-off between a trio, an in-sync quartet, and beyond. Plus, you can dial up or down the level of facial expression on each face and batch output multiple animation files from multiple audio sources.
Emotion Control
Bring the drama.
Audio2Face gives you the ability to choose and animate your character’s emotions in the wink of an eye. The AI network automatically manipulates the face, eyes, mouth, tongue, and head motion to match your selected emotional range and customized level of intensity, or, automatically infers emotion directly from the audio clip.
Asset Credit: Blender Studio
Data Conversion
Connect and convert.
The latest update to Audio2Face now enables blendshape conversion and also blendweight export options . Plus, the app now supports export-import with Blendshapes for Blender and Epic Games Unreal Engine to generate motion for characters using their respective Omniverse Connectors.
Get Started with Audio2Face in NVIDIA Avatar Cloud Engine
Download available production microservices today or apply for our early access program to explore models in development. ACE delivers the building blocks to deliver interactive digital humans.
Dive into Step-by-Step Tutorials
Get live help.
Connect with Omniverse experts live to get your questions answered.
- See the weekly livestream calendar
- Attend an upcoming event
- Chat with us on Discord
Explore Resources
Learn at your own pace with free getting started material.
- Check out our documentation
- Watch Omniverse tutorials
- Dive into Q&A forums
Download NVIDIA Audio2Face Authoring Application
Frequently asked questions, what is the status of audio2face today.
A2F has been tuned for emotional responses and features improved audio quality. It can now be run locally on the GPU.
How do I install Audio2Face through NVIDIA Omniverse?
To install Omniverse Audio2Face, follow the steps below:
- Download NVIDIA Omniverse and run the installation
- Once installed, open the Omniverse launcher
- Head to the Omniverse Exchange and find Omniverse Audio2Face in the Apps section
- Click install, then launch
When will Audio2Face be available as a production microservice?
NVIDIA Audioe2Face is available today as a production microservice and can be accessed with the purchase of NVIDIA AI Enterprise for production. For early access or evaluation, please test out the 90 eval or use an API key from ai.nvidia.com
Become Part of Our Community
Access tutorials.
Take advantage of hundreds of free tutorials , sessions , or our beginner’s training to get started with USD .
Become an Omnivore
Join our community! Attend our weekly live streams on Twitch and connect with us on Discord and our forums.
Get Technical Support
Having trouble? Post your questions in the forums for quick guidance from Omniverse experts, or refer to the platform documentation .
Showcase Your Work
Created an Omniverse masterpiece? Submit it to the Omniverse Gallery , where you can get inspired and inspire others.
Connect With Us
Stay up-to-date on the latest nvidia omniverse news..
- DGX Systems
- DGX Station A100
- EGX Platform
- Data Center GPUs
- Virtual GPU
- NVIDIA Drive
- NVIDIA Isaac
- NVIDIA Ampere Architecture
- Tensor Cores
- Multi-Instance GPU (MIG)
- AI Foundation Models
- Content Library
- Customer Stories
- Deep Learning Blogs
- Developer Education
- Documentation
- GTC AI Conference
- Kaggle Grandmasters
- Professional Services
- Startups and VCs
- Technical Blog
- Technical Training
- Training for IT Professionals
- Company Overview
- Venture Capital (NVentures)
- NVIDIA Foundation
- Social Responsibility
- Technologies

- Privacy Policy
- Manage My Privacy
- Do Not Sell or Share My Data
- Terms of Service
- Accessibility
- Corporate Policies
- Product Security
Search code, repositories, users, issues, pull requests...
Provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications
Speech-Conditioned Face Generation with Deep Adversarial Networks
imatge-upc/speech2face
Folders and files, repository files navigation, speech2face, important note.
Notice that this repo is a preliminary work before our Wav2Pix paper in ICASSP 2019. You probably want to check that other repo instead, as it is more mature and stable than this one.
Introduction
Image synthesis has been a trending task for the AI community in recent years. Many works have shown the potential of Generative Adversarial Networks (GANs) to deal with tasks such as text or audio to image synthesis. In particular, recent advances in deep learning using audio have inspired many works involving both visual and auditory information. In this work we propose a face synthesis method which is trained end-to-end using audio and/or language representations as inputs. We used this project as baseline.

Requirements
This implementation currently only support running with GPUs.
`python runtime.py
- type : GAN archiecture to use (gan | wgan | vanilla_gan | vanilla_wgan) . default = gan . Vanilla mean not conditional
- dataset : Dataset to use (birds | flowers) . default = flowers
- split : An integer indicating which split to use (0 : train | 1: valid | 2: test) . default = 0
- lr : The learning rate. default = 0.0002
- diter : Only for WGAN, number of iteration for discriminator for each iteration of the generator. default = 5
- vis_screen : The visdom env name for visualization. default = gan
- save_path : Path for saving the models.
- l1_coef : L1 loss coefficient in the generator loss fucntion for gan and vanilla_gan. default= 50
- l2_coef : Feature matching coefficient in the generator loss fucntion for gan and vanilla_gan. default= 100
- pre_trained_disc : Discriminator pre-tranined model path used for intializing training.
- pre_trained_gen Generator pre-tranined model path used for intializing training.
- batch_size : Batch size. default= 64
- num_workers : Number of dataloader workers used for fetching data. default = 8
- epochs : Number of training epochs. default= 200
- cls : Boolean flag to whether train with cls algorithms or not. default= False
[1] Generative Adversarial Text-to-Image Synthesis https://arxiv.org/abs/1605.05396
[2] Improved Techniques for Training GANs https://arxiv.org/abs/1606.03498
[3] Wasserstein GAN https://arxiv.org/abs/1701.07875
[4] Improved Training of Wasserstein GANs https://arxiv.org/pdf/1704.00028.pdf
- Python 100.0%
espnet / fastspeech2_conformer like 2
Fastspeech2conformer.
FastSpeech2Conformer is a non-autoregressive text-to-speech (TTS) model that combines the strengths of FastSpeech2 and the conformer architecture to generate high-quality speech from text quickly and efficiently.
Model Description
The FastSpeech2Conformer model was proposed with the paper Recent Developments On Espnet Toolkit Boosted By Conformer by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang. It was first released in this repository . The license used is Apache 2.0 .
FastSpeech2 is a non-autoregressive TTS model, which means it can generate speech significantly faster than autoregressive models. It addresses some of the limitations of its predecessor, FastSpeech, by directly training the model with ground-truth targets instead of the simplified output from a teacher model. It also introduces more variation information of speech (e.g., pitch, energy, and more accurate duration) as conditional inputs. Furthermore, the conformer (convolutional transformer) architecture makes use of convolutions inside the transformer blocks to capture local speech patterns, while the attention layer is able to capture relationships in the input that are farther away.
- Developed by: Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
- Shared by: Connor Henderson
- Model type: text-to-speech
- Language(s) (NLP): [More Information Needed]
- License: Apache 2.0
- Finetuned from model [optional]: [More Information Needed]
Model Sources [optional]
- Repository: ESPnet
- Paper [optional]: Recent Developments On Espnet Toolkit Boosted By Conformer
🤗 Transformers Usage
You can run FastSpeech2Conformer locally with the 🤗 Transformers library.
- First install the 🤗 Transformers library , g2p-en:
- Run inference via the Transformers modelling code with the model and hifigan separately
- Run inference via the Transformers modelling code with the model and hifigan combined
- Run inference with a pipeline and specify which vocoder to use
[More Information Needed]
Downstream Use [optional]
Out-of-scope use, bias, risks, and limitations, recommendations.
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
How to Get Started with the Model
Use the code below to get started with the model.
Training Details
Training data, training procedure, preprocessing [optional], training hyperparameters.
- Training regime: [More Information Needed]
Speeds, Sizes, Times [optional]
Testing data, factors & metrics, testing data, model examination [optional], environmental impact.
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019) .
- Hardware Type: [More Information Needed]
- Hours used: [More Information Needed]
- Cloud Provider: [More Information Needed]
- Compute Region: [More Information Needed]
- Carbon Emitted: [More Information Needed]
Technical Specifications [optional]
Model architecture and objective, compute infrastructure, citation [optional], glossary [optional], more information [optional], model card authors [optional].
Connor Henderson (Disclaimer: no ESPnet affiliation)
Model Card Contact
Spaces using espnet/fastspeech2_conformer 2.
- Sign Up (2)
- f2fafrica.com
Uganda: Music band members arrested for complaining about president’s speech length

Authorities in Uganda have arrested and charged eight music band members for insulting the East African nation’s president after they allegedly complained about a speech he was giving at an event on Saturday.
Per BBC , the incident occurred during the 50th wedding anniversary celebrations of former Prime Minister Amama Mbabazi and his wife Jacqueline Mbabazi. President Yoweri Museveni is said to have delivered a speech during the event, but the members of the Crane Performers band were heard registering their displeasure over the length of his speech.
Security sources reportedly claimed that the band members were talking in the local Runyankole dialect at the time. They allegedly said, “Rutabandana Waturusya Rugahamuzindaro” – which means: “over speaker, we are tired, leave the microphone.”
The East African nation’s police as well as the band are yet to respond to the incident. As previously reported by Face2Face Africa , not all leaders in Africa – even those who claim to be practicing democracy – give field days to people who decide to express their freedom of speech, particularly when it involves insulting or criticizing the president.
In Uganda, the law of insulting the president attracts a jail term. A previous case was reported of how police in the central Gomba District arrested a 19-year-old man for allegedly insulting Museveni. According to the authorities , Joseph Kasumba, a resident of Kanoni town, abused the head of State who was on his way back from attending a New Year’s church service.
Besides Uganda, other African countries including Zimbabwe , Rwanda, and Cameroon have laws of such nature. In Zimbabwe, it is more restricting to criticize the president of the country. Although this practice was more predominant under the rule of the former president, Robert Mugabe, the country’s current president, Emmerson Mnangagwa, has not decriminalized this .
Conversations

Help us create more content like this
Subscribe to premium
Already a member? Sign in.

Connect with us
Join our Mailing List to Receive Updates
Telehealth versus face-to-face delivery of speech language pathology services: a systematic review and meta-analysis
- Find this author on Google Scholar
- Find this author on PubMed
- Search for this author on this site
- ORCID record for Anna Mae Scott
- For correspondence: [email protected]
- ORCID record for Justin Clark
- ORCID record for Magnolia Cardona
- ORCID record for Tiffany Atkins
- ORCID record for Ruwani Peiris
- ORCID record for Hannah Greenwood
- ORCID record for Rachel Wenke
- ORCID record for Elizabeth Cardell
- ORCID record for Paul J Glasziou
- Info/History
- Preview PDF
Background There is an increasing demand for the provision of speech language pathology (SLP) services via telehealth. Therefore, we systematically reviewed randomized controlled trials comparing telehealth to face-to-face provision of SLP services. Methods We searched Medline, Embase, and Cochrane, clinical trial registries, and conducted a citation analysis to identify trials. We included randomized trials comparing similar care delivered live via telehealth (phone or video), to face-to-face. Primary outcomes included: % syllables stuttered (%SS) (for individuals who stutter); change in sound pressure levels monologue (for individuals with Parkinson's disease); and key function scores (for other areas). Where data were sufficient, mean differences were calculated. Results Nine randomized controlled trials were included; 8 evaluated video and 1 evaluated phone telehealth. Risk of bias was generally low or unclear, excepting blinding. There were no significant differences at any time-point up to 18 months for %SS (mean difference, MD 0.1, 95% CI -0.4 to 0.6, p=0.70). For people with Parkinson's disease, there was no difference between groups in change in sound pressure levels (monologue) (MD 0.6, 95% CI -1.2 to 2.5, p=0.49). Four trials investigated interventions for speech sound disorder, voice disorder, and post-stroke dysphagia and aphasia; they found no differences between telehealth service delivery and face-to-face delivery. Conclusions Evidence suggests that the telehealth provision of SLP services may be a viable alternative to their provision face-to-face, particularly to people who stutter and people with Parkinson's disease. The key limitation is the small number of randomized controlled trials, as well as evidence on the quality of life, well-being and satisfaction, and economic outcomes.
Competing Interest Statement
The authors have declared no competing interest.
Funding Statement
This systematic review was commissioned by the Department of Health and Aged Care, Canberra, Australia, as part of a series of systematic reviews on the effectiveness of telehealth within primary care in 2020-21 and their update in 2023. The funder was involved in establishing the parameters of the study question (PICO). The funder was not involved in the conduct, analysis, or interpretation of the systematic review, or in the decision to submit the manuscript for publication.
Author Declarations
I confirm all relevant ethical guidelines have been followed, and any necessary IRB and/or ethics committee approvals have been obtained.
I confirm that all necessary patient/participant consent has been obtained and the appropriate institutional forms have been archived, and that any patient/participant/sample identifiers included were not known to anyone (e.g., hospital staff, patients or participants themselves) outside the research group so cannot be used to identify individuals.
I understand that all clinical trials and any other prospective interventional studies must be registered with an ICMJE-approved registry, such as ClinicalTrials.gov. I confirm that any such study reported in the manuscript has been registered and the trial registration ID is provided (note: if posting a prospective study registered retrospectively, please provide a statement in the trial ID field explaining why the study was not registered in advance).
I have followed all appropriate research reporting guidelines, such as any relevant EQUATOR Network research reporting checklist(s) and other pertinent material, if applicable.
Data Availability
All data produced in the present work are contained in the manuscript
View the discussion thread.
Thank you for your interest in spreading the word about medRxiv.
NOTE: Your email address is requested solely to identify you as the sender of this article.

Citation Manager Formats
- EndNote (tagged)
- EndNote 8 (xml)
- RefWorks Tagged
- Ref Manager
- Tweet Widget
- Facebook Like
- Google Plus One
- Addiction Medicine (316)
- Allergy and Immunology (620)
- Anesthesia (160)
- Cardiovascular Medicine (2284)
- Dentistry and Oral Medicine (280)
- Dermatology (201)
- Emergency Medicine (370)
- Endocrinology (including Diabetes Mellitus and Metabolic Disease) (805)
- Epidemiology (11593)
- Forensic Medicine (10)
- Gastroenterology (681)
- Genetic and Genomic Medicine (3600)
- Geriatric Medicine (337)
- Health Economics (618)
- Health Informatics (2311)
- Health Policy (916)
- Health Systems and Quality Improvement (865)
- Hematology (335)
- HIV/AIDS (753)
- Infectious Diseases (except HIV/AIDS) (13170)
- Intensive Care and Critical Care Medicine (758)
- Medical Education (360)
- Medical Ethics (100)
- Nephrology (391)
- Neurology (3369)
- Nursing (191)
- Nutrition (508)
- Obstetrics and Gynecology (652)
- Occupational and Environmental Health (647)
- Oncology (1764)
- Ophthalmology (526)
- Orthopedics (210)
- Otolaryngology (284)
- Pain Medicine (223)
- Palliative Medicine (66)
- Pathology (441)
- Pediatrics (1008)
- Pharmacology and Therapeutics (422)
- Primary Care Research (407)
- Psychiatry and Clinical Psychology (3077)
- Public and Global Health (6005)
- Radiology and Imaging (1227)
- Rehabilitation Medicine and Physical Therapy (715)
- Respiratory Medicine (811)
- Rheumatology (367)
- Sexual and Reproductive Health (356)
- Sports Medicine (318)
- Surgery (390)
- Toxicology (50)
- Transplantation (171)
- Urology (142)
- FanNation FanNation FanNation
- Swimsuit SI Swimsuit SI Swimsuit
- Sportsbook SI Sportsbook SI Sportsbook
- Tickets SI Tickets SI Tickets
- Shop SI Shop SI Shop
- What's on TV
- NCAAB NCAAB NCAAB
- Home Home Home
- Scores Scores Scores
- Schedule Schedule Schedule
- Men's Bracket Men's Bracket Men's Bracket
- Women's Bracket Women's Bracket Women's Bracket
- Rankings Rankings Rankings
- Standings Standings Standings
- Stats Stats Statistics
- Teams Teams Teams

Dawn Staley Had Beautiful Message for Caitlin Clark During NCAA Championship Trophy Ceremony
- Author: Andy Nesbitt
In this story:
South Carolina was able to race past Iowa in Sunday's national championship game in Cleveland and win their second title in three years with an 87-75 victory over Caitlin Clark and the Iowa Hawkeyes .
Gamecocks coach Dawn Staley was emotional immediately following the win during her postgame interview with ESPN's Holly Rowe. Then during the trophy presentation, Staley took a minute to shout out Clark and all that she's done for women's basketball during her legendary career, which came to an end Sunday.
“I want to personally thank Caitlin Clark for lifting up our sport,” Staley said. “She carried a heavy load for our sport and it’s not going to stop here on the collegiate tour. When she’s the No. 1 pick in the WNBA draft she’s going to lift that league up as well. So Caitlin Clark, if you’re out there, you are one of the GOATs of our game and we appreciate you.”
Here' s that moment:
Dawn Staley with a tribute to Caitlin Clark and what she's done for the game: "You are one of the GOATs of our game and we appreciate you" pic.twitter.com/Rg4okSZlFE — CJ Fogler account may or may not be notable (@cjzero) April 7, 2024
Latest NCAAB News

Former Kentucky Wildcats are favorites or near the top for every important NBA Award

Minnesota to face No. 1 Indiana State in NIT second round

Louisville Men's Basketball Head Coach Hot Board 2.0

The Auburn Tigers need to watch out for these two Yale stars

2024 NCAA Tournament: How to watch Gonzaga Bulldogs vs. McNeese State Cowboys, live stream, TV channel for first round matchup

Reunion Part 2
The reunion continues as Gizelle becomes emotional reflecting on her relationship with her late father. Robyn reveals the reason her friendship with Candiace came to a seeming end. The husbands join the stage to reflect upon the season. Wendy and Nneka face off to clear up all the rumors, but things go south when a bombshell receipt is put on the table.
Season 8 - Episodes

Projections and Deflections

Home Sweet Drama

Heaven Is a Place in Potomac

In a Pickle

Pie in the Austin Sky

Tequila, Tears, Texas

Don't Rock the Boat

Painting Austin Red

Hard Conversations

Friendship Is a Mother

First Come, First Served

Blazed and Confused

Sharing Is Caring

Sun’s Out Buns Out

Fool’s Gold

Boiling Point

Fashion Show-Down

An Iconic Ending

Reunion Part 1

Related Videos

Is Gizelle Bryant Dating an Athlete?

Start Watching Part 2 of the RHOP Season 8 Reunion

Chris Bassett Addresses Allegations: "I've Never Met This Person"
Latest episodes on bravo.

Point Break

Watch What Happens Live 4/10

The Wright Way

Capri Chaos

May the Best Woman Win

Watch What Happens Live 4/9

Watch What Happens Live 4/8

Grenadian Nightmare

Never Before Scene 1109

Dishonorable Guests

Watch What Happens Live 4/7

Loverboy to Flower Boy

Watch What Happens Live 4/4

Watch What Happens Live 4/3

Take it Cheesy

Doubting Doute

Line in the Sand
Smile 2 CinemaCon Footage Just Revealed A Lot Of New Details About The Exciting Horror Sequel, And I Am Stoked
Smile 2 arrives in theaters everywhere on October 18.

Back in fall 2022, the movie world was blissfully surprised by the arrival of Parker Finn's Smile . While it was originally planned to be a streaming release exclusive for Paramount+, the film's distribution plans were pivoted, and the studio decided to drop it in theaters just in time for spooky season. It turned out to be a massive hit, wowing movie-goers and ultimately earning over $200 million worldwide.
Naturally, it didn't take long at all for Paramount to announce plans for a Smile 2 , with Parker Finn back writing and directing, and while the project has been ensconced in secrecy since that announcement, we learned a whole lot more about the film today thanks to footage that premiered at CinemaCon 2024.
Paramount held its presentation this morning at the annual convention for exhibitors in Las Vegas, and in addition to announcing news about some major upcoming projects (including a GI Joe/Transformers crossover and a new Avatar: The Last Airbender movie ), the studio provided the audience in the The Colosseum Theater at Caesars Palace with an exciting first look at Smile 2 . In addition to featuring some serious scares, the footage also revealed some key details about the plot.
It was previously announced that Aladdin 's Naomi Scott is playing the lead of Smile 2 , and today we learned that she will be portraying a popular singer who ends up being targeted by the grinning entity that plagued Sosie Bacon's Rose Cotter in the previous film. The story will find the protagonist on tour performing lavish and colorful concerts reminiscent of a Lady Gaga show when she finds herself facing the growing movie series' signature horror.
In one scene, she is in her dressing room alone when a knock at the door breaks the silence. She inquisitively says, "Hello?" and approaches the door, but before she can reach it, the thing swings open and a character played by Lukas Gage comes storming in, scaring her. He is clearly distressed and seemingly choking, and when he falls to the floor, the pop star tries to help him. It's too late though – and the nightmare then begins. The mystery man seems to pass away, but a second after his eyes go blank, they seem to come awake again... and then a creepy smile stretches across his face.
From there, there were a number of freaky images that quickly splashed across the screen, including Naomi Scott on a stage walking around a bunch of figures cloaked in white sheets and smacking her face and leaving a bloody handprint. My favorite bit, however, was a quick shot of a narrow, mirrored hallway that was filled with grinning people getting closer and closer to the camera.
The Smile 2 CinemaCon footage concluded with Naomi Scott's character being approached by a little girl. Thinking that the child is a fan, she compliments her shirt and asks if she wants her to sign it, but the kid doesn't say a word; she just stands there. Scott leans down with a Sharpie and applies her signature, but the girl doesn't move and just smiles at her.
CINEMABLEND NEWSLETTER
Your Daily Blend of Entertainment News
The first look at Smile 2 was definitely more about aesthetic than story – as its not clear yet how the sequel will build on what happened in the first movie and how the journey of the new protagonist will differ from what Rose Cotter experienced. That being said, one can definitely see how the pop star angle will be exciting, as celebrities have people staring and smiling at them all the time... but in this case, it won't just be folks who are star-struck and left mute in front of an artist they love. I'm keeping my fingers crossed that there will at some point be a concert sequence where Naomi Scott's character looks out into a crowded arena and just sees hundreds of people creepily grinning at her.
With Smile 2 set to arrive in theaters this fall (just in time for Halloween 2024!), it hopefully won't be too long before the first trailer for the film arrives online and in theaters – but fans for now will have to show some patience for footage. Based on this early look, however, it appears that few will be left disappointed by what Parker Finn has in store with his follow-up feature.
Also starring Rosemarie DeWitt and Smile star Kyle Galler in addition to the aforementioned Naomi Scott and Lukas Gage, Smile 2 is presently scheduled to arrive in theaters everywhere on October 18. Be on the lookout for more updates about the project in the coming months here on CinemaBlend, and to learn about all of the scary features set to be released in the coming months, check out our Upcoming Horror Movies guide .

Eric Eisenberg is the Assistant Managing Editor at CinemaBlend. After graduating Boston University and earning a bachelor’s degree in journalism, he took a part-time job as a staff writer for CinemaBlend, and after six months was offered the opportunity to move to Los Angeles and take on a newly created West Coast Editor position. Over a decade later, he's continuing to advance his interests and expertise. In addition to conducting filmmaker interviews and contributing to the news and feature content of the site, Eric also oversees the Movie Reviews section, writes the the weekend box office report (published Sundays), and is the site's resident Stephen King expert. He has two King-related columns.
Ninja Turtles Is Following Mutant Mayhem Up With An R-Rated Live-Action Movie, And I Have Conflicted Feelings
Avatar: The Last Airbender Is Getting Animated Movies, And The Marvel Vet They Cast As The Villain Is Perfect
Johnny Knoxville Wants A Wrestlemania Rematch, And As A Fan I’m So In
Most Popular
By Mack Rawden April 10, 2024
By Corey Chichizola April 10, 2024
By Jason Wiese April 10, 2024
By Philip Sledge April 10, 2024
By Eric Eisenberg April 10, 2024
By Hugh Scott April 09, 2024
By Dirk Libbey April 09, 2024
By Philip Sledge April 09, 2024
By Jerrica Tisdale April 09, 2024
By Laura Hurley April 09, 2024
By Alexandra Ramos April 09, 2024
- 2 Avatar: The Last Airbender Is Getting Animated Movies, And The Marvel Vet They Cast As The Villain Is Perfect
- 3 Someone Threw Flowers At Olivia Rodrigo At Her Concert, And Fans Are Praising How She Handled It
- 4 Transformers And G.I. Joe Are Officially Having A Crossover Movie Following Rise Of The Beasts Cliffhanger
- 5 Travis Kelce's Viral Siblings Day TikTok For Jason Kelce Had Fans Calling Them 'The World's Favorite Brothers,' And I Couldn't Agree More
IMAGES
VIDEO
COMMENTS
Face reconstructed from speech. We consider the task of reconstructing an image of a person's face from a short input audio segment of speech. We show several results of our method on VoxCeleb dataset. Our model takes only an audio waveform as input (the true faces are shown just for reference). Note that our goal is not to reconstruct an ...
Implementation of the CVPR 2019 Paper - Speech2Face: Learning the Face Behind a Voice by MIT CSAIL Topics. deep-learning speech-recognition face cvpr2019 Resources. Readme License. MIT license Activity. Stars. 155 stars Watchers. 11 watching Forks. 34 forks Report repository Releases No releases published.
A team led by researchers from MIT's Computer Science and Artificial Intelligence Lab (CSAIL) have recently shown that it can: they've created a new system that can produce a predicted image of someone's face from hearing them talk for only five seconds. Trained on millions of YouTube clips featuring over 100,000 different speakers ...
Voice encoder network. Our voice encoder module is a convolutional neural network that turns the spectrogram of a short input speech into a pseudo face feature, which is sub-sequently fed into the face decoder to reconstruct the face image (Fig. 2). The architecture of the voice encoder is sum-marized in Table 1.
The idea is really simple: You take a pre-trained face synthetiser [1] network. You then train a voice encoder to match its last feature vector \(v_s\) with the face synthesiser \(v_f\). If the two encoders project in a similar space, the face decoder should decode similar faces.
Speech-face association learning. The associations be-tween faces and voices have been studied extensively in many scientific disciplines. In the domain of computer vi- ... [36, 3]; or to learn the correlation between speech and emotion [2]. Our goal is to learn the correlations be-tween facial traits and speech, by directly reconstructing a
From the videos, they extract speech-face pairs, which are fed into two branches of the architecture. The images are encoded into a latent vector using the pre-trained face recognition model, whilst the waveform is fed into a voice encoder in a form of a spectrogram, in order to utilize the power of convolutional architectures.
This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how-and in what manner-our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.
Publications Speech2Face: Learning the Face Behind a Voice Publication. CVPR 2019 Authors. Tae-Hyun Oh*, Tali Dekel*, Changil Kim*, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Wojciech Matusik (* Equally contributed)
Speech2Face: Learning the Face Behind a Voice (Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Wojciech Matusik) CVPR 2019 ... speech recognition based on facial images. The project consists of 2 major models: Sound to FaceVector: converts soundwave into a facial recognition vector;
Speech2Face is an advanced neural network developed by MIT scientists and trained to recognize certain facial features and reconstruct people's faces just by listening to the sound of their voices.
Duarte et al. [31] proposed an end-to-end speech-to-face GAN model called Wav2Pix, which has the ability to synthesize diverse and promising face pictures according to a raw speech signal. Oh et ...
Matt AI is a project to drive the digital human Matt with speech only in real-time.
The team explains in their preprint paper how they trained a deep neural network — a type of multilayered artificial neural network that mimics the non-linear architecture of the human brain — using millions of Internet videos featuring over 100,000 talking heads. It is from these videos that the team's Speech2Face AI is able to "learn ...
This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how--and in what manner--our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.
During training, our model learns voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity. This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes ...
Audio-to-Animation Made Easy With Generative AI. NVIDIA Audio2Face beta is a foundation application for animating 3D characters facial characteristics to match any voice-over track, whether for a game, film, real-time digital assistant, or just for fun. You can use the Universal Scene Description (OpenUSD) -based app for interactive real-time ...
As input, it takes a speech sample computed into a spectrogram - a visual representation of sound waves. Then the system encodes it into a vector with determined facial features. A face decoder. It takes the encoded vector and reconstructs the portrait from it. The image of the face is generated in standard form (front side and neutral by ...
Introduction. Image synthesis has been a trending task for the AI community in recent years. Many works have shown the potential of Generative Adversarial Networks (GANs) to deal with tasks such as text or audio to image synthesis. In particular, recent advances in deep learning using audio have inspired many works involving both visual and ...
This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how--and in what manner--our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.
It was first released in this repository. The license used is Apache 2.0. FastSpeech2 is a non-autoregressive TTS model, which means it can generate speech significantly faster than autoregressive models. It addresses some of the limitations of its predecessor, FastSpeech, by directly training the model with ground-truth targets instead of the ...
Authorities in Uganda have arrested and charged eight music band members for insulting the East African nation's president after they allegedly complained about a speech he was giving at an ...
Background There is an increasing demand for the provision of speech language pathology (SLP) services via telehealth. Therefore, we systematically reviewed randomized controlled trials comparing telehealth to face-to-face provision of SLP services. Methods We searched Medline, Embase, and Cochrane, clinical trial registries, and conducted a citation analysis to identify trials. We included ...
Minnesota to face No. 1 Indiana State in NIT second round Louisville Men's Basketball Head Coach Hot Board 2.0 The Auburn Tigers need to watch out for these two Yale stars
The following is the transcript of a speech delivered by UN Climate Change Executive Secretary Simon Stiell on 10 April 2024 at Chatham House in London, England. The speech can also be watched on YouTube. ... In the face of crop-destroying droughts, much bolder climate action to curb emissions and help farmers adapt will increase food security ...
Reunion Part 2. The reunion continues as Gizelle becomes emotional reflecting on her relationship with her late father. Robyn reveals the reason her friendship with Candiace came to a seeming end ...
Welcome to coverage of the second Premier League investigation into Everton for breaches of its Profit and Sustainability regulations, this one covering the three seasons up to and including 2022 ...
The Smile 2 CinemaCon footage concluded with Naomi Scott's character being approached by a little girl. Thinking that the child is a fan, she compliments her shirt and asks if she wants her to ...