Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- How to Write a Strong Hypothesis | Guide & Examples

How to Write a Strong Hypothesis | Guide & Examples
Published on 6 May 2022 by Shona McCombes .
A hypothesis is a statement that can be tested by scientific research. If you want to test a relationship between two or more variables, you need to write hypotheses before you start your experiment or data collection.
Table of contents
What is a hypothesis, developing a hypothesis (with example), hypothesis examples, frequently asked questions about writing hypotheses.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess – it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations, and statistical analysis of data).
Variables in hypotheses
Hypotheses propose a relationship between two or more variables . An independent variable is something the researcher changes or controls. A dependent variable is something the researcher observes and measures.
In this example, the independent variable is exposure to the sun – the assumed cause . The dependent variable is the level of happiness – the assumed effect .
Prevent plagiarism, run a free check.
Step 1: ask a question.
Writing a hypothesis begins with a research question that you want to answer. The question should be focused, specific, and researchable within the constraints of your project.
Step 2: Do some preliminary research
Your initial answer to the question should be based on what is already known about the topic. Look for theories and previous studies to help you form educated assumptions about what your research will find.
At this stage, you might construct a conceptual framework to identify which variables you will study and what you think the relationships are between them. Sometimes, you’ll have to operationalise more complex constructs.
Step 3: Formulate your hypothesis
Now you should have some idea of what you expect to find. Write your initial answer to the question in a clear, concise sentence.
Step 4: Refine your hypothesis
You need to make sure your hypothesis is specific and testable. There are various ways of phrasing a hypothesis, but all the terms you use should have clear definitions, and the hypothesis should contain:
- The relevant variables
- The specific group being studied
- The predicted outcome of the experiment or analysis
Step 5: Phrase your hypothesis in three ways
To identify the variables, you can write a simple prediction in if … then form. The first part of the sentence states the independent variable and the second part states the dependent variable.
In academic research, hypotheses are more commonly phrased in terms of correlations or effects, where you directly state the predicted relationship between variables.
If you are comparing two groups, the hypothesis can state what difference you expect to find between them.
Step 6. Write a null hypothesis
If your research involves statistical hypothesis testing , you will also have to write a null hypothesis. The null hypothesis is the default position that there is no association between the variables. The null hypothesis is written as H 0 , while the alternative hypothesis is H 1 or H a .
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
A hypothesis is not just a guess. It should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations, and statistical analysis of data).
A research hypothesis is your proposed answer to your research question. The research hypothesis usually includes an explanation (‘ x affects y because …’).
A statistical hypothesis, on the other hand, is a mathematical statement about a population parameter. Statistical hypotheses always come in pairs: the null and alternative hypotheses. In a well-designed study , the statistical hypotheses correspond logically to the research hypothesis.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
McCombes, S. (2022, May 06). How to Write a Strong Hypothesis | Guide & Examples. Scribbr. Retrieved 2 April 2024, from https://www.scribbr.co.uk/research-methods/hypothesis-writing/
Is this article helpful?

Shona McCombes
Other students also liked, operationalisation | a guide with examples, pros & cons, what is a conceptual framework | tips & examples, a quick guide to experimental design | 5 steps & examples.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Genome Biol
The data-hypothesis relationship
Teppo felin.
1 Saïd Business School, University of Oxford, Oxford, UK
Jan Koenderink
2 Department of Physics, Delft University of Technology, Delft, The Netherlands
3 Department of Experimental Psychology, University of Leuven, Leuven, Belgium
Joachim I. Krueger
4 Department of Cognitive, Linguistic and Psychological Sciences, Brown University, Providence, USA
Denis Noble
5 Department of Physiology, Anatomy and Genetics, University of Oxford, Oxford, UK
George F.R. Ellis
6 Department of Mathematics, University of Cape Town, Cape Town, South Africa
Every conscious cognitive process will show itself to be steeped in theories; full of hypotheses. Rupert Riedl [ 1 ]
In a provocative editorial, Yanai and Lercher (henceforth Y&L) claim that “a hypothesis is a liability” [ 2 ]. They contend that having a hypothesis is costly because it causes scientists to miss hidden data and interesting phenomena. Y&L advocate “hypothesis-free” data exploration, which they argue can yield significant scientific discoveries.
We disagree. While we concur that a bad hypothesis is a liability, there is no such thing as hypothesis-free data exploration. Observation and data are always hypothesis- or theory-laden. Data is meaningless without some form of hypothesis or theory. Any exploration of data, however informal, is necessarily guided by some form of expectations. Even informal hunches or conjectures are types of proto-hypothesis. Furthermore, seemingly hypothesis-free statistical tools and computational techniques also contain latent hypotheses and theories about what is important—what might be interesting, worth measuring or paying attention to. Thus, while Y&L argue that a “hypothesis is a liability,” we argue that hypothesis-free observation is not possible (nor desirable) and that hypotheses in fact are the primary engine of scientific creativity and discovery.
The hidden gorilla
To illustrate their point about how a hypothesis is a liability, Y&L present their own version of the famous gorilla experiment [ 3 ]. In their experiment, subjects receive some made-up data featuring three variables: the BMI of individuals, the number of steps taken on a particular day, and their gender. One experimental group received three hypotheses to consider, while the other was “hypothesis-free.” Subjects in this latter group were simply asked to address the question “what do you conclude from the dataset?”
The “catch” of Y&L’s experiment was that a visual plot of the data showed a waving gorilla. And the key finding was that subjects in the hypothesis-free group were five times more likely to see the gorilla, compared with subjects in the hypothesis-focused group. Y&L concluded from this that hypotheses blind us to hidden patterns and insights in the data. Perhaps ironically, Y&L come to this conclusion based on their own hypothesis about the dangers of hypotheses.
But how exactly does missing the gorilla generalize to Y&L’s point about a hypothesis being a liability in scientific discovery? They argue that missing the gorilla is a problem, even though it is hard to see how finding an irrelevant gorilla mimics making a scientific insight. Now, we understand the gorilla is used as a metaphor for missing surprising or hidden things in science. But a meteorologist missing a cloud that looks like a gorilla is roughly equivalent to what Y&L are doing. A gorilla-shaped cloud has no scientific interest to the meteorologist, just as the gorilla-shaped data is irrelevant to Y&L’s context (the health data with three variables: BMI, steps taken and gender). Furthermore, the gorilla example does not generalize to scientific discovery because a gorilla is something that is universally recognized, while scientific discovery is essentially about finding new data, establishing new facts and relationships. New insights and scientific discoveries do not somehow “pop out” like the gorilla does once one plots the raw data. Hypotheses are needed. Thus, there is a mismatch between the experiment and what Y&L are claiming, on a number of levels.
Y&L import some of these problems from the original gorilla study [ 4 ]. The most serious concern is that various versions of the gorilla study can be seen as a form of attentional misdirection, similar to what is practiced by magicians. Experimental tasks are artificially constructed and designed to prove a specific hypothesis: that people are blind and miss large objects in their visual scenes. Experimenters first hide something in the visual scene, then distract their subjects with other tasks (whether counting basketball passes or asking them to analyze specific hypotheses), and then, voilà, reveal to them what they have missed. The problem is that—whether in science or in everyday life—an indefinite number of things remain undetected when we interact with data or visual scenes. It is not obvious what an apple falling means, without the right question, hypothesis, or theory. Visual scenes and data teem with possibilities, uses and meanings. Of course, the excitement generated by these studies comes from the fact that something so large and surprising—like a gorilla—goes undetected, even though it should be plainly obvious.
But there are deeper issues here. Reductionist forms of science assume that cues and data (somehow) jump out and tell us why they are relevant and important, based on the characteristics of the data itself (the physical properties of the world). In vision science, this assumption is based on research in psychophysics (and inverse optics and ideal observer theory) that focuses on salience as a function of cue or stimulus characteristics. From this perspective, cues and stimuli become data, information, and evidence due to their inherent nature [ 5 ].
To illustrate the problem with this, consider two stimulus or cue characteristics that are important to various versions of the gorilla study—and central to psychophysics and the cognitive sciences more generally—namely “size” and “surprisingness” [ 6 ]. The idea in psychophysics is that these characteristics should make cues salient. For example, researchers embedded an image of a gorilla in the CT scan images of patients’ lungs. They then asked expert radiologists to look for nodules as part of lung-cancer screening. Eighty-three percent of the radiologists missed the gorilla embedded in the image, despite the fact that the gorilla was 48 times the size of the nodules they were looking for [ 7 ].
But if radiologists or experimental subjects were asked to, say, “look for something unusual” or to “see if you can find the animal,” they would presumably find the gorilla. Thus, visual awareness or recognition has little to do with size or surprisingness. It has more to do with the question posed by the experimenter or the expectations of experimental subjects. In fact, experimental subjects themselves might suspect that the study actually is not about counting basketball passes or about analyzing health data or finding cancerous nodules in lungs. If subjects think that they are being tricked by experimenters—as is often the case—they might ignore the distracting tasks and priming questions and look for and find the gorilla. Note, again, that the a priori hypothesis of experimenters themselves is that people are blind, and so the experiments themselves are designed to prove this point. Alert subjects might suspect that they are being purposefully distracted and thus try to guess what they are meant to look for and find it.
The key point here is that the “transformation” of raw cues or data to information and evidence is not a straightforward process. It requires some form of hypothesis. Cues and data do not automatically tell us what they mean, whether or why they are relevant, or for which hypothesis they might provide evidence. Size is relevant in some situations, but not in others. Cues and data only become information and evidence in response to the questions and queries that we are asking.
Fishing expeditions require a net
One alternative to having a hypothesis, Y&L argue, is hypothesis- free exploration of data or what they call fishing expeditions. Of course, the idea of engaging in a fishing expedition—as Y&L recognize—has highly negative connotations, suggesting haphazard, unscientific, and perhaps even unethical practices. But they make a valid point: more exploratory and imaginative practices are important in science.
But fishing expeditions are hardly hypothesis-free. That is, fishing expeditions—to extend Y&L’s metaphor—require a net or some type of device for catching fish. Data and insights (just like fish) do not jump out and declare their relevance, meaning, or importance. As put by physical chemist Michael Polanyi, “things are not labelled ‘evidence’ in nature” [ 8 ]. The relevant data needs to be identified and lured in some fashion. Even the most exploratory process in science features choices and assumptions about what will count as data and evidence and what should be measured (and how). Any look at data—however preliminary it might be— necessarily represents some form of proto-hypothesis: a latent expectation, question, or even guess about what might be lurking, about what might potentially be interesting or relevant and how it might be caught.
In short, there’s no systematic way to extract and identify anything hidden without at least some rough idea of what one is looking for. The tools and devices scientists use are the net, sieve, or filter for capturing relevance and meaning. These nets come in vastly different materials and textures, sizes, types of weights, and anchors. Choices also need to be made about where to cast these nets. There are various ways to use and deploy them (trolling, longline, and so forth). Each choice implies a hypothesis. The choice of fishing net implies a hypothesis about what one is looking for and about what one might expect to catch and see as relevant [ 9 ].
Now, it might seem like we are stretching the definition of a hypothesis by including expectations, conjectures, and even the statistical and computational tools that are used to generate insights. But we think it is important to recognize that any tool—whether cognitive, computational, or statistical—functions like a net, as it already embodies implicit hypotheses about what matters and what does not. Perhaps these are not full-fledged, formal hypotheses in the sense that Y&L discuss. But they certainly are proto-hypotheses that direct awareness and attention toward what should be measured and what counts as data and evidence. A hypothesis is some form of expectation or question about what one is looking for and about what one expects to find. The identification and collection of data necessarily is of the same form, as one cannot collect all data about what is going on in the world at a specific time: flu patterns in China, weather patterns in the Pacific, sunspot cycles, the state of the New York stock exchange, earthquakes in Tahiti, and so on. Science is about making decisions about what subset of all this “stuff” should be focused on and included in the analysis.
Y&L specifically emphasize correlations and the generation of various statistical patterns as a way to make hypothesis-free discoveries in data. Correlations are one form of “net” for looking at data. But correlations are ubiquitous and their strength tells us little [ 10 ]. One needs a hypothesis to arbitrate between which correlation might be worth investigating and which not. The genome-wide associational studies have pointed this out. With the exception of the usual outliers (rare genetic diseases), the association levels are relatively small. More data may offer more stable statistical estimates, but it will not achieve the identification of causality required for a physiological explanation. On the contrary, the extremely low association data can be hiding substantial causality or perhaps more complex or interconnected, omnigenic factors are at play in the genome [ 11 ]. A causal hypothesis, tested rigorously with quantitative modeling, can reveal the potential pathways for understanding genetic variation, epigenetic factors, and disease or traits [ 12 ].
Science: bottom-up versus top-down
Y&L argue that scientific discoveries are “undiscoverable without data.” While this is correct in principle, Y&L mis-specify the data-hypothesis relationship by privileging the role the data to the detriment of hypothesis and theory. They ignore the temporal primacy of theory and hypothesis. A hypothesis tells us what data to look for. Data emerges and becomes evidence in response to a hypothesis. In physics, for example, the existence of gravitational waves had long been hypothesized. The hypothesis guided scientists to look for this data. This specifically led to the invention and construction of exquisitely sensitive devices to detect and measure gravitational radiation (e.g., LIGO and VIRGO observations). Eventually, in 2015, gravitational waves were discovered. The data emerged because of the conceptualization, design, and construction of relevant devices for measurement. The data was manifest due to the hypothesis rather than the other way around. And the data analysis itself is theory-based [ 13 ]: it depends on templates of waves expected from the gravitational coalescence of black holes or neutron stars.
Einstein aptly captured the relationship between hypotheses and data when noting that “whether you can observe a thing or not depends on the theory which you use. It is the theory which decides what can be observed.” Einstein’s point might be illustrated by the so-called DIKW hierarchy (Fig. 1 ) [ 14 ]. Currently popular data-first approaches assume that scientific understanding is built from the bottom-up. But to the contrary, many of the greatest insights have come “top-down,” where scientists start with theories and hypotheses that guide them to identify the right data and evidence. One of the most profound ways this happens is when scientists query fundamental assumptions that are taken for granted, such as that species are fixed for all time, or that simultaneity is independent of the state of motion. This questioning of axiomatic assumptions drives the creation of transformational theories (the theory of evolution, special relativity) and the subsequent collection of associated data that tests such profound reshaping of the foundations.

The DIKW “hierarchy” is often seen as “bottom-up.” But, as we argue, top-down mechanisms play a critical role in discovering data, relevance, and meaning
There certainly are significant reciprocal influences between these “levels” of the hierarchy. But Y&L’s central argument that a “hypothesis is a liability” simply does not recognize the profound, top-down influence played by hypotheses and theories in science, and how these enable the identification and generation of data.
Our concern is that starting at the bottom—as suggested by Y&L’s notion of hypothesis-free exploration of data—will inadvertently lead to an overly descriptive science: what Ernest Rutherford called “stamp collecting.” Charles Darwin anticipated this problem when he wrote to a friend:
It made me laugh to read of [Edwin Lankester’s] advice or rather regret that I had not published facts alone . How profoundly ignorant he must be of the very soul of observation. About 30 years ago there was much talk that Geologists ought only to observe and not theorise ; and I well remember someone saying, that at this rate a man might as well go into a gravel-pit and count the pebbles and describe their colours. How odd it is that everyone should not see that all observation must be for or against some view , if it is to be of any service [ 15 ].
Acknowledgements
TF, DN and GFRE gratefully acknowledge University of Oxford's Foundations of Value and Values-initiative for providing a forum to discuss these types of interdisciplinary issues.
Authors’ contributions
TF wrote the initial draft of the manuscript. JK, JIK, DN and GFRE added many ideas, examples and further edits to subsequent iterations of the article. The authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
Hypothesis Testing
- Last updated
- Save as PDF
- Page ID 31289
CO-6: Apply basic concepts of probability, random variation, and commonly used statistical probability distributions.
Learning Objectives
LO 6.26: Outline the logic and process of hypothesis testing.
LO 6.27: Explain what the p-value is and how it is used to draw conclusions.
Video: Hypothesis Testing (8:43)
Introduction
We are in the middle of the part of the course that has to do with inference for one variable.
So far, we talked about point estimation and learned how interval estimation enhances it by quantifying the magnitude of the estimation error (with a certain level of confidence) in the form of the margin of error. The result is the confidence interval — an interval that, with a certain confidence, we believe captures the unknown parameter.
We are now moving to the other kind of inference, hypothesis testing . We say that hypothesis testing is “the other kind” because, unlike the inferential methods we presented so far, where the goal was estimating the unknown parameter, the idea, logic and goal of hypothesis testing are quite different.
In the first two parts of this section we will discuss the idea behind hypothesis testing, explain how it works, and introduce new terminology that emerges in this form of inference. The final two parts will be more specific and will discuss hypothesis testing for the population proportion ( p ) and the population mean ( μ, mu).
If this is your first statistics course, you will need to spend considerable time on this topic as there are many new ideas. Many students find this process and its logic difficult to understand in the beginning.
In this section, we will use the hypothesis test for a population proportion to motivate our understanding of the process. We will conduct these tests manually. For all future hypothesis test procedures, including problems involving means, we will use software to obtain the results and focus on interpreting them in the context of our scenario.
General Idea and Logic of Hypothesis Testing
The purpose of this section is to gradually build your understanding about how statistical hypothesis testing works. We start by explaining the general logic behind the process of hypothesis testing. Once we are confident that you understand this logic, we will add some more details and terminology.
To start our discussion about the idea behind statistical hypothesis testing, consider the following example:
A case of suspected cheating on an exam is brought in front of the disciplinary committee at a certain university.
There are two opposing claims in this case:
- The student’s claim: I did not cheat on the exam.
- The instructor’s claim: The student did cheat on the exam.
Adhering to the principle “innocent until proven guilty,” the committee asks the instructor for evidence to support his claim. The instructor explains that the exam had two versions, and shows the committee members that on three separate exam questions, the student used in his solution numbers that were given in the other version of the exam.
The committee members all agree that it would be extremely unlikely to get evidence like that if the student’s claim of not cheating had been true. In other words, the committee members all agree that the instructor brought forward strong enough evidence to reject the student’s claim, and conclude that the student did cheat on the exam.
What does this example have to do with statistics?
While it is true that this story seems unrelated to statistics, it captures all the elements of hypothesis testing and the logic behind it. Before you read on to understand why, it would be useful to read the example again. Please do so now.
Statistical hypothesis testing is defined as:
- Assessing evidence provided by the data against the null claim (the claim which is to be assumed true unless enough evidence exists to reject it).
Here is how the process of statistical hypothesis testing works:
- We have two claims about what is going on in the population. Let’s call them claim 1 (this will be the null claim or hypothesis) and claim 2 (this will be the alternative) . Much like the story above, where the student’s claim is challenged by the instructor’s claim, the null claim 1 is challenged by the alternative claim 2. (For us, these claims are usually about the value of population parameter(s) or about the existence or nonexistence of a relationship between two variables in the population).
- We choose a sample, collect relevant data and summarize them (this is similar to the instructor collecting evidence from the student’s exam). For statistical tests, this step will also involve checking any conditions or assumptions.
- We figure out how likely it is to observe data like the data we obtained, if claim 1 is true. (Note that the wording “how likely …” implies that this step requires some kind of probability calculation). In the story, the committee members assessed how likely it is to observe evidence such as the instructor provided, had the student’s claim of not cheating been true.
- If, after assuming claim 1 is true, we find that it would be extremely unlikely to observe data as strong as ours or stronger in favor of claim 2, then we have strong evidence against claim 1, and we reject it in favor of claim 2. Later we will see this corresponds to a small p-value.
- If, after assuming claim 1 is true, we find that observing data as strong as ours or stronger in favor of claim 2 is NOT VERY UNLIKELY , then we do not have enough evidence against claim 1, and therefore we cannot reject it in favor of claim 2. Later we will see this corresponds to a p-value which is not small.
In our story, the committee decided that it would be extremely unlikely to find the evidence that the instructor provided had the student’s claim of not cheating been true. In other words, the members felt that it is extremely unlikely that it is just a coincidence (random chance) that the student used the numbers from the other version of the exam on three separate problems. The committee members therefore decided to reject the student’s claim and concluded that the student had, indeed, cheated on the exam. (Wouldn’t you conclude the same?)
Hopefully this example helped you understand the logic behind hypothesis testing.
Interactive Applet: Reasoning of a Statistical Test
To strengthen your understanding of the process of hypothesis testing and the logic behind it, let’s look at three statistical examples.
A recent study estimated that 20% of all college students in the United States smoke. The head of Health Services at Goodheart University (GU) suspects that the proportion of smokers may be lower at GU. In hopes of confirming her claim, the head of Health Services chooses a random sample of 400 Goodheart students, and finds that 70 of them are smokers.
Let’s analyze this example using the 4 steps outlined above:
- claim 1: The proportion of smokers at Goodheart is 0.20.
- claim 2: The proportion of smokers at Goodheart is less than 0.20.
Claim 1 basically says “nothing special goes on at Goodheart University; the proportion of smokers there is no different from the proportion in the entire country.” This claim is challenged by the head of Health Services, who suspects that the proportion of smokers at Goodheart is lower.
- Choosing a sample and collecting data: A sample of n = 400 was chosen, and summarizing the data revealed that the sample proportion of smokers is p -hat = 70/400 = 0.175.While it is true that 0.175 is less than 0.20, it is not clear whether this is strong enough evidence against claim 1. We must account for sampling variation.
- Assessment of evidence: In order to assess whether the data provide strong enough evidence against claim 1, we need to ask ourselves: How surprising is it to get a sample proportion as low as p -hat = 0.175 (or lower), assuming claim 1 is true? In other words, we need to find how likely it is that in a random sample of size n = 400 taken from a population where the proportion of smokers is p = 0.20 we’ll get a sample proportion as low as p -hat = 0.175 (or lower).It turns out that the probability that we’ll get a sample proportion as low as p -hat = 0.175 (or lower) in such a sample is roughly 0.106 (do not worry about how this was calculated at this point – however, if you think about it hopefully you can see that the key is the sampling distribution of p -hat).
- Conclusion: Well, we found that if claim 1 were true there is a probability of 0.106 of observing data like that observed or more extreme. Now you have to decide …Do you think that a probability of 0.106 makes our data rare enough (surprising enough) under claim 1 so that the fact that we did observe it is enough evidence to reject claim 1? Or do you feel that a probability of 0.106 means that data like we observed are not very likely when claim 1 is true, but they are not unlikely enough to conclude that getting such data is sufficient evidence to reject claim 1. Basically, this is your decision. However, it would be nice to have some kind of guideline about what is generally considered surprising enough.
A certain prescription allergy medicine is supposed to contain an average of 245 parts per million (ppm) of a certain chemical. If the concentration is higher than 245 ppm, the drug will likely cause unpleasant side effects, and if the concentration is below 245 ppm, the drug may be ineffective. The manufacturer wants to check whether the mean concentration in a large shipment is the required 245 ppm or not. To this end, a random sample of 64 portions from the large shipment is tested, and it is found that the sample mean concentration is 250 ppm with a sample standard deviation of 12 ppm.
- Claim 1: The mean concentration in the shipment is the required 245 ppm.
- Claim 2: The mean concentration in the shipment is not the required 245 ppm.
Note that again, claim 1 basically says: “There is nothing unusual about this shipment, the mean concentration is the required 245 ppm.” This claim is challenged by the manufacturer, who wants to check whether that is, indeed, the case or not.
- Choosing a sample and collecting data: A sample of n = 64 portions is chosen and after summarizing the data it is found that the sample mean concentration is x-bar = 250 and the sample standard deviation is s = 12.Is the fact that x-bar = 250 is different from 245 strong enough evidence to reject claim 1 and conclude that the mean concentration in the whole shipment is not the required 245? In other words, do the data provide strong enough evidence to reject claim 1?
- Assessing the evidence: In order to assess whether the data provide strong enough evidence against claim 1, we need to ask ourselves the following question: If the mean concentration in the whole shipment were really the required 245 ppm (i.e., if claim 1 were true), how surprising would it be to observe a sample of 64 portions where the sample mean concentration is off by 5 ppm or more (as we did)? It turns out that it would be extremely unlikely to get such a result if the mean concentration were really the required 245. There is only a probability of 0.0007 (i.e., 7 in 10,000) of that happening. (Do not worry about how this was calculated at this point, but again, the key will be the sampling distribution.)
- Making conclusions: Here, it is pretty clear that a sample like the one we observed or more extreme is VERY rare (or extremely unlikely) if the mean concentration in the shipment were really the required 245 ppm. The fact that we did observe such a sample therefore provides strong evidence against claim 1, so we reject it and conclude with very little doubt that the mean concentration in the shipment is not the required 245 ppm.
Do you think that you’re getting it? Let’s make sure, and look at another example.
Is there a relationship between gender and combined scores (Math + Verbal) on the SAT exam?
Following a report on the College Board website, which showed that in 2003, males scored generally higher than females on the SAT exam, an educational researcher wanted to check whether this was also the case in her school district. The researcher chose random samples of 150 males and 150 females from her school district, collected data on their SAT performance and found the following:
Again, let’s see how the process of hypothesis testing works for this example:
- Claim 1: Performance on the SAT is not related to gender (males and females score the same).
- Claim 2: Performance on the SAT is related to gender – males score higher.
Note that again, claim 1 basically says: “There is nothing going on between the variables SAT and gender.” Claim 2 represents what the researcher wants to check, or suspects might actually be the case.
- Choosing a sample and collecting data: Data were collected and summarized as given above. Is the fact that the sample mean score of males (1,025) is higher than the sample mean score of females (1,010) by 15 points strong enough information to reject claim 1 and conclude that in this researcher’s school district, males score higher on the SAT than females?
- Assessment of evidence: In order to assess whether the data provide strong enough evidence against claim 1, we need to ask ourselves: If SAT scores are in fact not related to gender (claim 1 is true), how likely is it to get data like the data we observed, in which the difference between the males’ average and females’ average score is as high as 15 points or higher? It turns out that the probability of observing such a sample result if SAT score is not related to gender is approximately 0.29 (Again, do not worry about how this was calculated at this point).
- Conclusion: Here, we have an example where observing a sample like the one we observed or more extreme is definitely not surprising (roughly 30% chance) if claim 1 were true (i.e., if indeed there is no difference in SAT scores between males and females). We therefore conclude that our data does not provide enough evidence for rejecting claim 1.
- “The data provide enough evidence to reject claim 1 and accept claim 2”; or
- “The data do not provide enough evidence to reject claim 1.”
In particular, note that in the second type of conclusion we did not say: “ I accept claim 1 ,” but only “ I don’t have enough evidence to reject claim 1 .” We will come back to this issue later, but this is a good place to make you aware of this subtle difference.
Hopefully by now, you understand the logic behind the statistical hypothesis testing process. Here is a summary:

Learn by Doing: Logic of Hypothesis Testing
Did I Get This?: Logic of Hypothesis Testing
Steps in Hypothesis Testing
Video: Steps in Hypothesis Testing (16:02)
Now that we understand the general idea of how statistical hypothesis testing works, let’s go back to each of the steps and delve slightly deeper, getting more details and learning some terminology.
Hypothesis Testing Step 1: State the Hypotheses
In all three examples, our aim is to decide between two opposing points of view, Claim 1 and Claim 2. In hypothesis testing, Claim 1 is called the null hypothesis (denoted “ Ho “), and Claim 2 plays the role of the alternative hypothesis (denoted “ Ha “). As we saw in the three examples, the null hypothesis suggests nothing special is going on; in other words, there is no change from the status quo, no difference from the traditional state of affairs, no relationship. In contrast, the alternative hypothesis disagrees with this, stating that something is going on, or there is a change from the status quo, or there is a difference from the traditional state of affairs. The alternative hypothesis, Ha, usually represents what we want to check or what we suspect is really going on.
Let’s go back to our three examples and apply the new notation:
In example 1:
- Ho: The proportion of smokers at GU is 0.20.
- Ha: The proportion of smokers at GU is less than 0.20.
In example 2:
- Ho: The mean concentration in the shipment is the required 245 ppm.
- Ha: The mean concentration in the shipment is not the required 245 ppm.
In example 3:
- Ho: Performance on the SAT is not related to gender (males and females score the same).
- Ha: Performance on the SAT is related to gender – males score higher.
Learn by Doing: State the Hypotheses
Did I Get This?: State the Hypotheses
Hypothesis Testing Step 2: Collect Data, Check Conditions and Summarize Data
This step is pretty obvious. This is what inference is all about. You look at sampled data in order to draw conclusions about the entire population. In the case of hypothesis testing, based on the data, you draw conclusions about whether or not there is enough evidence to reject Ho.
There is, however, one detail that we would like to add here. In this step we collect data and summarize it. Go back and look at the second step in our three examples. Note that in order to summarize the data we used simple sample statistics such as the sample proportion ( p -hat), sample mean (x-bar) and the sample standard deviation (s).
In practice, you go a step further and use these sample statistics to summarize the data with what’s called a test statistic . We are not going to go into any details right now, but we will discuss test statistics when we go through the specific tests.
This step will also involve checking any conditions or assumptions required to use the test.
Hypothesis Testing Step 3: Assess the Evidence
As we saw, this is the step where we calculate how likely is it to get data like that observed (or more extreme) when Ho is true. In a sense, this is the heart of the process, since we draw our conclusions based on this probability.
- If this probability is very small (see example 2), then that means that it would be very surprising to get data like that observed (or more extreme) if Ho were true. The fact that we did observe such data is therefore evidence against Ho, and we should reject it.
- On the other hand, if this probability is not very small (see example 3) this means that observing data like that observed (or more extreme) is not very surprising if Ho were true. The fact that we observed such data does not provide evidence against Ho. This crucial probability, therefore, has a special name. It is called the p-value of the test.
In our three examples, the p-values were given to you (and you were reassured that you didn’t need to worry about how these were derived yet):
- Example 1: p-value = 0.106
- Example 2: p-value = 0.0007
- Example 3: p-value = 0.29
Obviously, the smaller the p-value, the more surprising it is to get data like ours (or more extreme) when Ho is true, and therefore, the stronger the evidence the data provide against Ho.
Looking at the three p-values of our three examples, we see that the data that we observed in example 2 provide the strongest evidence against the null hypothesis, followed by example 1, while the data in example 3 provides the least evidence against Ho.
- Right now we will not go into specific details about p-value calculations, but just mention that since the p-value is the probability of getting data like those observed (or more extreme) when Ho is true, it would make sense that the calculation of the p-value will be based on the data summary, which, as we mentioned, is the test statistic. Indeed, this is the case. In practice, we will mostly use software to provide the p-value for us.
Hypothesis Testing Step 4: Making Conclusions
Since our statistical conclusion is based on how small the p-value is, or in other words, how surprising our data are when Ho is true, it would be nice to have some kind of guideline or cutoff that will help determine how small the p-value must be, or how “rare” (unlikely) our data must be when Ho is true, for us to conclude that we have enough evidence to reject Ho.
This cutoff exists, and because it is so important, it has a special name. It is called the significance level of the test and is usually denoted by the Greek letter α (alpha). The most commonly used significance level is α (alpha) = 0.05 (or 5%). This means that:
- if the p-value < α (alpha) (usually 0.05), then the data we obtained is considered to be “rare (or surprising) enough” under the assumption that Ho is true, and we say that the data provide statistically significant evidence against Ho, so we reject Ho and thus accept Ha.
- if the p-value > α (alpha)(usually 0.05), then our data are not considered to be “surprising enough” under the assumption that Ho is true, and we say that our data do not provide enough evidence to reject Ho (or, equivalently, that the data do not provide enough evidence to accept Ha).
Now that we have a cutoff to use, here are the appropriate conclusions for each of our examples based upon the p-values we were given.
In Example 1:
- Using our cutoff of 0.05, we fail to reject Ho.
- Conclusion : There IS NOT enough evidence that the proportion of smokers at GU is less than 0.20
- Still we should consider: Does the evidence seen in the data provide any practical evidence towards our alternative hypothesis?
In Example 2:
- Using our cutoff of 0.05, we reject Ho.
- Conclusion : There IS enough evidence that the mean concentration in the shipment is not the required 245 ppm.
In Example 3:
- Conclusion : There IS NOT enough evidence that males score higher on average than females on the SAT.
Notice that all of the above conclusions are written in terms of the alternative hypothesis and are given in the context of the situation. In no situation have we claimed the null hypothesis is true. Be very careful of this and other issues discussed in the following comments.
- Although the significance level provides a good guideline for drawing our conclusions, it should not be treated as an incontrovertible truth. There is a lot of room for personal interpretation. What if your p-value is 0.052? You might want to stick to the rules and say “0.052 > 0.05 and therefore I don’t have enough evidence to reject Ho”, but you might decide that 0.052 is small enough for you to believe that Ho should be rejected. It should be noted that scientific journals do consider 0.05 to be the cutoff point for which any p-value below the cutoff indicates enough evidence against Ho, and any p-value above it, or even equal to it , indicates there is not enough evidence against Ho. Although a p-value between 0.05 and 0.10 is often reported as marginally statistically significant.
- It is important to draw your conclusions in context . It is never enough to say: “p-value = …, and therefore I have enough evidence to reject Ho at the 0.05 significance level.” You should always word your conclusion in terms of the data. Although we will use the terminology of “rejecting Ho” or “failing to reject Ho” – this is mostly due to the fact that we are instructing you in these concepts. In practice, this language is rarely used. We also suggest writing your conclusion in terms of the alternative hypothesis.Is there or is there not enough evidence that the alternative hypothesis is true?
- Let’s go back to the issue of the nature of the two types of conclusions that I can make.
- Either I reject Ho (when the p-value is smaller than the significance level)
- or I cannot reject Ho (when the p-value is larger than the significance level).
As we mentioned earlier, note that the second conclusion does not imply that I accept Ho, but just that I don’t have enough evidence to reject it. Saying (by mistake) “I don’t have enough evidence to reject Ho so I accept it” indicates that the data provide evidence that Ho is true, which is not necessarily the case . Consider the following slightly artificial yet effective example:
An employer claims to subscribe to an “equal opportunity” policy, not hiring men any more often than women for managerial positions. Is this credible? You’re not sure, so you want to test the following two hypotheses:
- Ho: The proportion of male managers hired is 0.5
- Ha: The proportion of male managers hired is more than 0.5
Data: You choose at random three of the new managers who were hired in the last 5 years and find that all 3 are men.
Assessing Evidence: If the proportion of male managers hired is really 0.5 (Ho is true), then the probability that the random selection of three managers will yield three males is therefore 0.5 * 0.5 * 0.5 = 0.125. This is the p-value (using the multiplication rule for independent events).
Conclusion: Using 0.05 as the significance level, you conclude that since the p-value = 0.125 > 0.05, the fact that the three randomly selected managers were all males is not enough evidence to reject the employer’s claim of subscribing to an equal opportunity policy (Ho).
However, the data (all three selected are males) definitely does NOT provide evidence to accept the employer’s claim (Ho).
Learn By Doing: Using p-values
Did I Get This?: Using p-values
Comment about wording: Another common wording in scientific journals is:
- “The results are statistically significant” – when the p-value < α (alpha).
- “The results are not statistically significant” – when the p-value > α (alpha).
Often you will see significance levels reported with additional description to indicate the degree of statistical significance. A general guideline (although not required in our course) is:
- If 0.01 ≤ p-value < 0.05, then the results are (statistically) significant .
- If 0.001 ≤ p-value < 0.01, then the results are highly statistically significant .
- If p-value < 0.001, then the results are very highly statistically significant .
- If p-value > 0.05, then the results are not statistically significant (NS).
- If 0.05 ≤ p-value < 0.10, then the results are marginally statistically significant .
Let’s summarize
We learned quite a lot about hypothesis testing. We learned the logic behind it, what the key elements are, and what types of conclusions we can and cannot draw in hypothesis testing. Here is a quick recap:
Video: Hypothesis Testing Overview (2:20)
Here are a few more activities if you need some additional practice.
Did I Get This?: Hypothesis Testing Overview
- Notice that the p-value is an example of a conditional probability . We calculate the probability of obtaining results like those of our data (or more extreme) GIVEN the null hypothesis is true. We could write P(Obtaining results like ours or more extreme | Ho is True).
- We could write P(Obtaining a test statistic as or more extreme than ours | Ho is True).
- In this case we are asking “Assuming the null hypothesis is true, how rare is it to observe something as or more extreme than what I have found in my data?”
- If after assuming the null hypothesis is true, what we have found in our data is extremely rare (small p-value), this provides evidence to reject our assumption that Ho is true in favor of Ha.
- The p-value can also be thought of as the probability, assuming the null hypothesis is true, that the result we have seen is solely due to random error (or random chance). We have already seen that statistics from samples collected from a population vary. There is random error or random chance involved when we sample from populations.
In this setting, if the p-value is very small, this implies, assuming the null hypothesis is true, that it is extremely unlikely that the results we have obtained would have happened due to random error alone, and thus our assumption (Ho) is rejected in favor of the alternative hypothesis (Ha).
- It is EXTREMELY important that you find a definition of the p-value which makes sense to you. New students often need to contemplate this idea repeatedly through a variety of examples and explanations before becoming comfortable with this idea. It is one of the two most important concepts in statistics (the other being confidence intervals).
- We infer that the alternative hypothesis is true ONLY by rejecting the null hypothesis.
- A statistically significant result is one that has a very low probability of occurring if the null hypothesis is true.
- Results which are statistically significant may or may not have practical significance and vice versa.
Error and Power
LO 6.28: Define a Type I and Type II error in general and in the context of specific scenarios.
LO 6.29: Explain the concept of the power of a statistical test including the relationship between power, sample size, and effect size.
Video: Errors and Power (12:03)
Type I and Type II Errors in Hypothesis Tests
We have not yet discussed the fact that we are not guaranteed to make the correct decision by this process of hypothesis testing. Maybe you are beginning to see that there is always some level of uncertainty in statistics.
Let’s think about what we know already and define the possible errors we can make in hypothesis testing. When we conduct a hypothesis test, we choose one of two possible conclusions based upon our data.
If the p-value is smaller than your pre-specified significance level (α, alpha), you reject the null hypothesis and either
- You have made the correct decision since the null hypothesis is false
- You have made an error ( Type I ) and rejected Ho when in fact Ho is true (your data happened to be a RARE EVENT under Ho)
If the p-value is greater than (or equal to) your chosen significance level (α, alpha), you fail to reject the null hypothesis and either
- You have made the correct decision since the null hypothesis is true
- You have made an error ( Type II ) and failed to reject Ho when in fact Ho is false (the alternative hypothesis, Ha, is true)
The following summarizes the four possible results which can be obtained from a hypothesis test. Notice the rows represent the decision made in the hypothesis test and the columns represent the (usually unknown) truth in reality.

Although the truth is unknown in practice – or we would not be conducting the test – we know it must be the case that either the null hypothesis is true or the null hypothesis is false. It is also the case that either decision we make in a hypothesis test can result in an incorrect conclusion!
A TYPE I Error occurs when we Reject Ho when, in fact, Ho is True. In this case, we mistakenly reject a true null hypothesis.
- P(TYPE I Error) = P(Reject Ho | Ho is True) = α = alpha = Significance Level
A TYPE II Error occurs when we fail to Reject Ho when, in fact, Ho is False. In this case we fail to reject a false null hypothesis.
P(TYPE II Error) = P(Fail to Reject Ho | Ho is False) = β = beta
When our significance level is 5%, we are saying that we will allow ourselves to make a Type I error less than 5% of the time. In the long run, if we repeat the process, 5% of the time we will find a p-value < 0.05 when in fact the null hypothesis was true.
In this case, our data represent a rare occurrence which is unlikely to happen but is still possible. For example, suppose we toss a coin 10 times and obtain 10 heads, this is unlikely for a fair coin but not impossible. We might conclude the coin is unfair when in fact we simply saw a very rare event for this fair coin.
Our testing procedure CONTROLS for the Type I error when we set a pre-determined value for the significance level.
Notice that these probabilities are conditional probabilities. This is one more reason why conditional probability is an important concept in statistics.
Unfortunately, calculating the probability of a Type II error requires us to know the truth about the population. In practice we can only calculate this probability using a series of “what if” calculations which depend upon the type of problem.
Comment: As you initially read through the examples below, focus on the broad concepts instead of the small details. It is not important to understand how to calculate these values yourself at this point.
- Try to understand the pictures we present. Which pictures represent an assumed null hypothesis and which represent an alternative?
- It may be useful to come back to this page (and the activities here) after you have reviewed the rest of the section on hypothesis testing and have worked a few problems yourself.
Interactive Applet: Statistical Significance
Here are two examples of using an older version of this applet. It looks slightly different but the same settings and options are available in the version above.
In both cases we will consider IQ scores.
Our null hypothesis is that the true mean is 100. Assume the standard deviation is 16 and we will specify a significance level of 5%.
In this example we will specify that the true mean is indeed 100 so that the null hypothesis is true. Most of the time (95%), when we generate a sample, we should fail to reject the null hypothesis since the null hypothesis is indeed true.
Here is one sample that results in a correct decision:

In the sample above, we obtain an x-bar of 105, which is drawn on the distribution which assumes μ (mu) = 100 (the null hypothesis is true). Notice the sample is shown as blue dots along the x-axis and the shaded region shows for which values of x-bar we would reject the null hypothesis. In other words, we would reject Ho whenever the x-bar falls in the shaded region.
Enter the same values and generate samples until you obtain a Type I error (you falsely reject the null hypothesis). You should see something like this:

If you were to generate 100 samples, you should have around 5% where you rejected Ho. These would be samples which would result in a Type I error.
The previous example illustrates a correct decision and a Type I error when the null hypothesis is true. The next example illustrates a correct decision and Type II error when the null hypothesis is false. In this case, we must specify the true population mean.
Let’s suppose we are sampling from an honors program and that the true mean IQ for this population is 110. We do not know the probability of a Type II error without more detailed calculations.
Let’s start with a sample which results in a correct decision.

In the sample above, we obtain an x-bar of 111, which is drawn on the distribution which assumes μ (mu) = 100 (the null hypothesis is true).
Enter the same values and generate samples until you obtain a Type II error (you fail to reject the null hypothesis). You should see something like this:

You should notice that in this case (when Ho is false), it is easier to obtain an incorrect decision (a Type II error) than it was in the case where Ho is true. If you generate 100 samples, you can approximate the probability of a Type II error.
We can find the probability of a Type II error by visualizing both the assumed distribution and the true distribution together. The image below is adapted from an applet we will use when we discuss the power of a statistical test.

There is a 37.4% chance that, in the long run, we will make a Type II error and fail to reject the null hypothesis when in fact the true mean IQ is 110 in the population from which we sample our 10 individuals.
Can you visualize what will happen if the true population mean is really 115 or 108? When will the Type II error increase? When will it decrease? We will look at this idea again when we discuss the concept of power in hypothesis tests.
- It is important to note that there is a trade-off between the probability of a Type I and a Type II error. If we decrease the probability of one of these errors, the probability of the other will increase! The practical result of this is that if we require stronger evidence to reject the null hypothesis (smaller significance level = probability of a Type I error), we will increase the chance that we will be unable to reject the null hypothesis when in fact Ho is false (increases the probability of a Type II error).
- When α (alpha) = 0.05 we obtained a Type II error probability of 0.374 = β = beta

- When α (alpha) = 0.01 (smaller than before) we obtain a Type II error probability of 0.644 = β = beta (larger than before)

- As the blue line in the picture moves farther right, the significance level (α, alpha) is decreasing and the Type II error probability is increasing.
- As the blue line in the picture moves farther left, the significance level (α, alpha) is increasing and the Type II error probability is decreasing
Let’s return to our very first example and define these two errors in context.
- Ho = The student’s claim: I did not cheat on the exam.
- Ha = The instructor’s claim: The student did cheat on the exam.
Adhering to the principle “innocent until proven guilty,” the committee asks the instructor for evidence to support his claim.
There are four possible outcomes of this process. There are two possible correct decisions:
- The student did cheat on the exam and the instructor brings enough evidence to reject Ho and conclude the student did cheat on the exam. This is a CORRECT decision!
- The student did not cheat on the exam and the instructor fails to provide enough evidence that the student did cheat on the exam. This is a CORRECT decision!
Both the correct decisions and the possible errors are fairly easy to understand but with the errors, you must be careful to identify and define the two types correctly.
TYPE I Error: Reject Ho when Ho is True
- The student did not cheat on the exam but the instructor brings enough evidence to reject Ho and conclude the student cheated on the exam. This is a Type I Error.
TYPE II Error: Fail to Reject Ho when Ho is False
- The student did cheat on the exam but the instructor fails to provide enough evidence that the student cheated on the exam. This is a Type II Error.
In most situations, including this one, it is more “acceptable” to have a Type II error than a Type I error. Although allowing a student who cheats to go unpunished might be considered a very bad problem, punishing a student for something he or she did not do is usually considered to be a more severe error. This is one reason we control for our Type I error in the process of hypothesis testing.
Did I Get This?: Type I and Type II Errors (in context)
- The probabilities of Type I and Type II errors are closely related to the concepts of sensitivity and specificity that we discussed previously. Consider the following hypotheses:
Ho: The individual does not have diabetes (status quo, nothing special happening)
Ha: The individual does have diabetes (something is going on here)
In this setting:
When someone tests positive for diabetes we would reject the null hypothesis and conclude the person has diabetes (we may or may not be correct!).
When someone tests negative for diabetes we would fail to reject the null hypothesis so that we fail to conclude the person has diabetes (we may or may not be correct!)
Let’s take it one step further:
Sensitivity = P(Test + | Have Disease) which in this setting equals P(Reject Ho | Ho is False) = 1 – P(Fail to Reject Ho | Ho is False) = 1 – β = 1 – beta
Specificity = P(Test – | No Disease) which in this setting equals P(Fail to Reject Ho | Ho is True) = 1 – P(Reject Ho | Ho is True) = 1 – α = 1 – alpha
Notice that sensitivity and specificity relate to the probability of making a correct decision whereas α (alpha) and β (beta) relate to the probability of making an incorrect decision.
Usually α (alpha) = 0.05 so that the specificity listed above is 0.95 or 95%.
Next, we will see that the sensitivity listed above is the power of the hypothesis test!
Reasons for a Type I Error in Practice
Assuming that you have obtained a quality sample:
- The reason for a Type I error is random chance.
- When a Type I error occurs, our observed data represented a rare event which indicated evidence in favor of the alternative hypothesis even though the null hypothesis was actually true.
Reasons for a Type II Error in Practice
Again, assuming that you have obtained a quality sample, now we have a few possibilities depending upon the true difference that exists.
- The sample size is too small to detect an important difference. This is the worst case, you should have obtained a larger sample. In this situation, you may notice that the effect seen in the sample seems PRACTICALLY significant and yet the p-value is not small enough to reject the null hypothesis.
- The sample size is reasonable for the important difference but the true difference (which might be somewhat meaningful or interesting) is smaller than your test was capable of detecting. This is tolerable as you were not interested in being able to detect this difference when you began your study. In this situation, you may notice that the effect seen in the sample seems to have some potential for practical significance.
- The sample size is more than adequate, the difference that was not detected is meaningless in practice. This is not a problem at all and is in effect a “correct decision” since the difference you did not detect would have no practical meaning.
- Note: We will discuss the idea of practical significance later in more detail.
Power of a Hypothesis Test
It is often the case that we truly wish to prove the alternative hypothesis. It is reasonable that we would be interested in the probability of correctly rejecting the null hypothesis. In other words, the probability of rejecting the null hypothesis, when in fact the null hypothesis is false. This can also be thought of as the probability of being able to detect a (pre-specified) difference of interest to the researcher.
Let’s begin with a realistic example of how power can be described in a study.
In a clinical trial to study two medications for weight loss, we have an 80% chance to detect a difference in the weight loss between the two medications of 10 pounds. In other words, the power of the hypothesis test we will conduct is 80%.
In other words, if one medication comes from a population with an average weight loss of 25 pounds and the other comes from a population with an average weight loss of 15 pounds, we will have an 80% chance to detect that difference using the sample we have in our trial.
If we were to repeat this trial many times, 80% of the time we will be able to reject the null hypothesis (that there is no difference between the medications) and 20% of the time we will fail to reject the null hypothesis (and make a Type II error!).
The difference of 10 pounds in the previous example, is often called the effect size . The measure of the effect differs depending on the particular test you are conducting but is always some measure related to the true effect in the population. In this example, it is the difference between two population means.
Recall the definition of a Type II error:
Notice that P(Reject Ho | Ho is False) = 1 – P(Fail to Reject Ho | Ho is False) = 1 – β = 1- beta.
The POWER of a hypothesis test is the probability of rejecting the null hypothesis when the null hypothesis is false . This can also be stated as the probability of correctly rejecting the null hypothesis .
POWER = P(Reject Ho | Ho is False) = 1 – β = 1 – beta
Power is the test’s ability to correctly reject the null hypothesis. A test with high power has a good chance of being able to detect the difference of interest to us, if it exists .
As we mentioned on the bottom of the previous page, this can be thought of as the sensitivity of the hypothesis test if you imagine Ho = No disease and Ha = Disease.
Factors Affecting the Power of a Hypothesis Test
The power of a hypothesis test is affected by numerous quantities (similar to the margin of error in a confidence interval).
Assume that the null hypothesis is false for a given hypothesis test. All else being equal, we have the following:
- Larger samples result in a greater chance to reject the null hypothesis which means an increase in the power of the hypothesis test.
- If the effect size is larger, it will become easier for us to detect. This results in a greater chance to reject the null hypothesis which means an increase in the power of the hypothesis test. The effect size varies for each test and is usually closely related to the difference between the hypothesized value and the true value of the parameter under study.
- From the relationship between the probability of a Type I and a Type II error (as α (alpha) decreases, β (beta) increases), we can see that as α (alpha) decreases, Power = 1 – β = 1 – beta also decreases.
- There are other mathematical ways to change the power of a hypothesis test, such as changing the population standard deviation; however, these are not quantities that we can usually control so we will not discuss them here.
In practice, we specify a significance level and a desired power to detect a difference which will have practical meaning to us and this determines the sample size required for the experiment or study.
For most grants involving statistical analysis, power calculations must be completed to illustrate that the study will have a reasonable chance to detect an important effect. Otherwise, the money spent on the study could be wasted. The goal is usually to have a power close to 80%.
For example, if there is only a 5% chance to detect an important difference between two treatments in a clinical trial, this would result in a waste of time, effort, and money on the study since, when the alternative hypothesis is true, the chance a treatment effect can be found is very small.
- In order to calculate the power of a hypothesis test, we must specify the “truth.” As we mentioned previously when discussing Type II errors, in practice we can only calculate this probability using a series of “what if” calculations which depend upon the type of problem.
The following activity involves working with an interactive applet to study power more carefully.
Learn by Doing: Power of Hypothesis Tests
The following reading is an excellent discussion about Type I and Type II errors.
(Optional) Outside Reading: A Good Discussion of Power (≈ 2500 words)
We will not be asking you to perform power calculations manually. You may be asked to use online calculators and applets. Most statistical software packages offer some ability to complete power calculations. There are also many online calculators for power and sample size on the internet, for example, Russ Lenth’s power and sample-size page .
Proportions (Introduction & Step 1)
CO-4: Distinguish among different measurement scales, choose the appropriate descriptive and inferential statistical methods based on these distinctions, and interpret the results.
LO 4.33: In a given context, distinguish between situations involving a population proportion and a population mean and specify the correct null and alternative hypothesis for the scenario.
LO 4.34: Carry out a complete hypothesis test for a population proportion by hand.
Video: Proportions (Introduction & Step 1) (7:18)
Now that we understand the process of hypothesis testing and the logic behind it, we are ready to start learning about specific statistical tests (also known as significance tests).
The first test we are going to learn is the test about the population proportion (p).
This test is widely known as the “z-test for the population proportion (p).”
We will understand later where the “z-test” part is coming from.
This will be the only type of problem you will complete entirely “by-hand” in this course. Our goal is to use this example to give you the tools you need to understand how this process works. After working a few problems, you should review the earlier material again. You will likely need to review the terminology and concepts a few times before you fully understand the process.
In reality, you will often be conducting more complex statistical tests and allowing software to provide the p-value. In these settings it will be important to know what test to apply for a given situation and to be able to explain the results in context.
Review: Types of Variables
When we conduct a test about a population proportion, we are working with a categorical variable. Later in the course, after we have learned a variety of hypothesis tests, we will need to be able to identify which test is appropriate for which situation. Identifying the variable as categorical or quantitative is an important component of choosing an appropriate hypothesis test.
Learn by Doing: Review Types of Variables
One Sample Z-Test for a Population Proportion
In this part of our discussion on hypothesis testing, we will go into details that we did not go into before. More specifically, we will use this test to introduce the idea of a test statistic , and details about how p-values are calculated .
Let’s start by introducing the three examples, which will be the leading examples in our discussion. Each example is followed by a figure illustrating the information provided, as well as the question of interest.
A machine is known to produce 20% defective products, and is therefore sent for repair. After the machine is repaired, 400 products produced by the machine are chosen at random and 64 of them are found to be defective. Do the data provide enough evidence that the proportion of defective products produced by the machine (p) has been reduced as a result of the repair?
The following figure displays the information, as well as the question of interest:
The question of interest helps us formulate the null and alternative hypotheses in terms of p, the proportion of defective products produced by the machine following the repair:
- Ho: p = 0.20 (No change; the repair did not help).
- Ha: p < 0.20 (The repair was effective at reducing the proportion of defective parts).
There are rumors that students at a certain liberal arts college are more inclined to use drugs than U.S. college students in general. Suppose that in a simple random sample of 100 students from the college, 19 admitted to marijuana use. Do the data provide enough evidence to conclude that the proportion of marijuana users among the students in the college (p) is higher than the national proportion, which is 0.157? (This number is reported by the Harvard School of Public Health.)
Again, the following figure displays the information as well as the question of interest:
As before, we can formulate the null and alternative hypotheses in terms of p, the proportion of students in the college who use marijuana:
- Ho: p = 0.157 (same as among all college students in the country).
- Ha: p > 0.157 (higher than the national figure).
Polls on certain topics are conducted routinely in order to monitor changes in the public’s opinions over time. One such topic is the death penalty. In 2003 a poll estimated that 64% of U.S. adults support the death penalty for a person convicted of murder. In a more recent poll, 675 out of 1,000 U.S. adults chosen at random were in favor of the death penalty for convicted murderers. Do the results of this poll provide evidence that the proportion of U.S. adults who support the death penalty for convicted murderers (p) changed between 2003 and the later poll?
Here is a figure that displays the information, as well as the question of interest:
Again, we can formulate the null and alternative hypotheses in term of p, the proportion of U.S. adults who support the death penalty for convicted murderers.
- Ho: p = 0.64 (No change from 2003).
- Ha: p ≠ 0.64 (Some change since 2003).
Learn by Doing: Proportions (Overview)
Did I Get This?: Proportions ( Overview )
Recall that there are basically 4 steps in the process of hypothesis testing:
- STEP 1: State the appropriate null and alternative hypotheses, Ho and Ha.
- STEP 2: Obtain a random sample, collect relevant data, and check whether the data meet the conditions under which the test can be used . If the conditions are met, summarize the data using a test statistic.
- STEP 3: Find the p-value of the test.
- STEP 4: Based on the p-value, decide whether or not the results are statistically significant and draw your conclusions in context.
- Note: In practice, we should always consider the practical significance of the results as well as the statistical significance.
We are now going to go through these steps as they apply to the hypothesis testing for the population proportion p. It should be noted that even though the details will be specific to this particular test, some of the ideas that we will add apply to hypothesis testing in general.
Step 1. Stating the Hypotheses
Here again are the three set of hypotheses that are being tested in each of our three examples:
Has the proportion of defective products been reduced as a result of the repair?
Is the proportion of marijuana users in the college higher than the national figure?
Did the proportion of U.S. adults who support the death penalty change between 2003 and a later poll?
The null hypothesis always takes the form:
- Ho: p = some value
and the alternative hypothesis takes one of the following three forms:
- Ha: p < that value (like in example 1) or
- Ha: p > that value (like in example 2) or
- Ha: p ≠ that value (like in example 3).
Note that it was quite clear from the context which form of the alternative hypothesis would be appropriate. The value that is specified in the null hypothesis is called the null value , and is generally denoted by p 0 . We can say, therefore, that in general the null hypothesis about the population proportion (p) would take the form:
- Ho: p = p 0
We write Ho: p = p 0 to say that we are making the hypothesis that the population proportion has the value of p 0 . In other words, p is the unknown population proportion and p 0 is the number we think p might be for the given situation.
The alternative hypothesis takes one of the following three forms (depending on the context):
Ha: p < p 0 (one-sided)
Ha: p > p 0 (one-sided)
Ha: p ≠ p 0 (two-sided)
The first two possible forms of the alternatives (where the = sign in Ho is challenged by < or >) are called one-sided alternatives , and the third form of alternative (where the = sign in Ho is challenged by ≠) is called a two-sided alternative. To understand the intuition behind these names let’s go back to our examples.
Example 3 (death penalty) is a case where we have a two-sided alternative:
In this case, in order to reject Ho and accept Ha we will need to get a sample proportion of death penalty supporters which is very different from 0.64 in either direction, either much larger or much smaller than 0.64.
In example 2 (marijuana use) we have a one-sided alternative:
Here, in order to reject Ho and accept Ha we will need to get a sample proportion of marijuana users which is much higher than 0.157.
Similarly, in example 1 (defective products), where we are testing:
in order to reject Ho and accept Ha, we will need to get a sample proportion of defective products which is much smaller than 0.20.
Learn by Doing: State Hypotheses (Proportions)
Did I Get This?: State Hypotheses (Proportions)
Proportions (Step 2)
Video: Proportions (Step 2) (12:38)
Step 2. Collect Data, Check Conditions, and Summarize Data
After the hypotheses have been stated, the next step is to obtain a sample (on which the inference will be based), collect relevant data , and summarize them.
It is extremely important that our sample is representative of the population about which we want to draw conclusions. This is ensured when the sample is chosen at random. Beyond the practical issue of ensuring representativeness, choosing a random sample has theoretical importance that we will mention later.
In the case of hypothesis testing for the population proportion (p), we will collect data on the relevant categorical variable from the individuals in the sample and start by calculating the sample proportion p-hat (the natural quantity to calculate when the parameter of interest is p).
Let’s go back to our three examples and add this step to our figures.
As we mentioned earlier without going into details, when we summarize the data in hypothesis testing, we go a step beyond calculating the sample statistic and summarize the data with a test statistic . Every test has a test statistic, which to some degree captures the essence of the test. In fact, the p-value, which so far we have looked upon as “the king” (in the sense that everything is determined by it), is actually determined by (or derived from) the test statistic. We will now introduce the test statistic.
The test statistic is a measure of how far the sample proportion p-hat is from the null value p 0 , the value that the null hypothesis claims is the value of p. In other words, since p-hat is what the data estimates p to be, the test statistic can be viewed as a measure of the “distance” between what the data tells us about p and what the null hypothesis claims p to be.
Let’s use our examples to understand this:
The parameter of interest is p, the proportion of defective products following the repair.
The data estimate p to be p-hat = 0.16
The null hypothesis claims that p = 0.20
The data are therefore 0.04 (or 4 percentage points) below the null hypothesis value.
It is hard to evaluate whether this difference of 4% in defective products is enough evidence to say that the repair was effective at reducing the proportion of defective products, but clearly, the larger the difference, the more evidence it is against the null hypothesis. So if, for example, our sample proportion of defective products had been, say, 0.10 instead of 0.16, then I think you would all agree that cutting the proportion of defective products in half (from 20% to 10%) would be extremely strong evidence that the repair was effective at reducing the proportion of defective products.
The parameter of interest is p, the proportion of students in a college who use marijuana.
The data estimate p to be p-hat = 0.19
The null hypothesis claims that p = 0.157
The data are therefore 0.033 (or 3.3. percentage points) above the null hypothesis value.
The parameter of interest is p, the proportion of U.S. adults who support the death penalty for convicted murderers.
The data estimate p to be p-hat = 0.675
The null hypothesis claims that p = 0.64
There is a difference of 0.035 (or 3.5. percentage points) between the data and the null hypothesis value.
The problem with looking only at the difference between the sample proportion, p-hat, and the null value, p 0 is that we have not taken into account the variability of our estimator p-hat which, as we know from our study of sampling distributions, depends on the sample size.
For this reason, the test statistic cannot simply be the difference between p-hat and p 0 , but must be some form of that formula that accounts for the sample size. In other words, we need to somehow standardize the difference so that comparison between different situations will be possible. We are very close to revealing the test statistic, but before we construct it, let’s be reminded of the following two facts from probability:
Fact 1: When we take a random sample of size n from a population with population proportion p, then

Fact 2: The z-score of any normal value (a value that comes from a normal distribution) is calculated by finding the difference between the value and the mean and then dividing that difference by the standard deviation (of the normal distribution associated with the value). The z-score represents how many standard deviations below or above the mean the value is.
Thus, our test statistic should be a measure of how far the sample proportion p-hat is from the null value p 0 relative to the variation of p-hat (as measured by the standard error of p-hat).
Recall that the standard error is the standard deviation of the sampling distribution for a given statistic. For p-hat, we know the following:

To find the p-value, we will need to determine how surprising our value is assuming the null hypothesis is true. We already have the tools needed for this process from our study of sampling distributions as represented in the table above.
If we assume the null hypothesis is true, we can specify that the center of the distribution of all possible values of p-hat from samples of size 400 would be 0.20 (our null value).
We can calculate the standard error, assuming p = 0.20 as
\(\sqrt{\dfrac{p_{0}\left(1-p_{0}\right)}{n}}=\sqrt{\dfrac{0.2(1-0.2)}{400}}=0.02\)
The following picture represents the sampling distribution of all possible values of p-hat of samples of size 400, assuming the true proportion p is 0.20 and our other requirements for the sampling distribution to be normal are met (we will review these during the next step).
")
In order to calculate probabilities for the picture above, we would need to find the z-score associated with our result.
This z-score is the test statistic ! In this example, the numerator of our z-score is the difference between p-hat (0.16) and null value (0.20) which we found earlier to be -0.04. The denominator of our z-score is the standard error calculated above (0.02) and thus quickly we find the z-score, our test statistic, to be -2.
The sample proportion based upon this data is 2 standard errors below the null value.
Hopefully you now understand more about the reasons we need probability in statistics!!
Now we will formalize the definition and look at our remaining examples before moving on to the next step, which will be to determine if a normal distribution applies and calculate the p-value.
Test Statistic for Hypothesis Tests for One Proportion is:
\(z=\dfrac{\hat{p}-p_{0}}{\sqrt{\dfrac{p_{0}\left(1-p_{0}\right)}{n}}}\)
It represents the difference between the sample proportion and the null value, measured in standard deviations (standard error of p-hat).
The picture above is a representation of the sampling distribution of p-hat assuming p = p 0 . In other words, this is a model of how p-hat behaves if we are drawing random samples from a population for which Ho is true.
Notice the center of the sampling distribution is at p 0 , which is the hypothesized proportion given in the null hypothesis (Ho: p = p 0 .) We could also mark the axis in standard error units,
\(\sqrt{\dfrac{p_{0}\left(1-p_{0}\right)}{n}}\)
For example, if our null hypothesis claims that the proportion of U.S. adults supporting the death penalty is 0.64, then the sampling distribution is drawn as if the null is true. We draw a normal distribution centered at 0.64 (p 0 ) with a standard error dependent on sample size,
\(\sqrt{\dfrac{0.64(1-0.64)}{n}}\).
Important Comment:
- Note that under the assumption that Ho is true (and if the conditions for the sampling distribution to be normal are satisfied) the test statistic follows a N(0,1) (standard normal) distribution. Another way to say the same thing which is quite common is: “The null distribution of the test statistic is N(0,1).”
By “null distribution,” we mean the distribution under the assumption that Ho is true. As we’ll see and stress again later, the null distribution of the test statistic is what the calculation of the p-value is based on.
Let’s go back to our remaining two examples and find the test statistic in each case:
Since the null hypothesis is Ho: p = 0.157, the standardized (z) score of p-hat = 0.19 is
\(z=\dfrac{0.19-0.157}{\sqrt{\dfrac{0.157(1-0.157)}{100}}} \approx 0.91\)
This is the value of the test statistic for this example.
We interpret this to mean that, assuming that Ho is true, the sample proportion p-hat = 0.19 is 0.91 standard errors above the null value (0.157).
Since the null hypothesis is Ho: p = 0.64, the standardized (z) score of p-hat = 0.675 is
\(z=\dfrac{0.675-0.64}{\sqrt{\dfrac{0.64(1-0.64)}{1000}}} \approx 2.31\)
We interpret this to mean that, assuming that Ho is true, the sample proportion p-hat = 0.675 is 2.31 standard errors above the null value (0.64).
Learn by Doing: Proportions (Step 2)
Comments about the Test Statistic:
- We mentioned earlier that to some degree, the test statistic captures the essence of the test. In this case, the test statistic measures the difference between p-hat and p 0 in standard errors. This is exactly what this test is about. Get data, and look at the discrepancy between what the data estimates p to be (represented by p-hat) and what Ho claims about p (represented by p 0 ).
- You can think about this test statistic as a measure of evidence in the data against Ho. The larger the test statistic, the “further the data are from Ho” and therefore the more evidence the data provide against Ho.
Learn by Doing: Proportions (Step 2) Understanding the Test Statistic
Did I Get This?: Proportions (Step 2)
- It should now be clear why this test is commonly known as the z-test for the population proportion . The name comes from the fact that it is based on a test statistic that is a z-score.
- Recall fact 1 that we used for constructing the z-test statistic. Here is part of it again:
When we take a random sample of size n from a population with population proportion p 0 , the possible values of the sample proportion p-hat ( when certain conditions are met ) have approximately a normal distribution with a mean of p 0 … and a standard deviation of

This result provides the theoretical justification for constructing the test statistic the way we did, and therefore the assumptions under which this result holds (in bold, above) are the conditions that our data need to satisfy so that we can use this test. These two conditions are:
i. The sample has to be random.
ii. The conditions under which the sampling distribution of p-hat is normal are met. In other words:

- Here we will pause to say more about condition (i.) above, the need for a random sample. In the Probability Unit we discussed sampling plans based on probability (such as a simple random sample, cluster, or stratified sampling) that produce a non-biased sample, which can be safely used in order to make inferences about a population. We noted in the Probability Unit that, in practice, other (non-random) sampling techniques are sometimes used when random sampling is not feasible. It is important though, when these techniques are used, to be aware of the type of bias that they introduce, and thus the limitations of the conclusions that can be drawn from them. For our purpose here, we will focus on one such practice, the situation in which a sample is not really chosen randomly, but in the context of the categorical variable that is being studied, the sample is regarded as random. For example, say that you are interested in the proportion of students at a certain college who suffer from seasonal allergies. For that purpose, the students in a large engineering class could be considered as a random sample, since there is nothing about being in an engineering class that makes you more or less likely to suffer from seasonal allergies. Technically, the engineering class is a convenience sample, but it is treated as a random sample in the context of this categorical variable. On the other hand, if you are interested in the proportion of students in the college who have math anxiety, then the class of engineering students clearly could not possibly be viewed as a random sample, since engineering students probably have a much lower incidence of math anxiety than the college population overall.
Learn by Doing: Proportions (Step 2) Valid or Invalid Sampling?
Let’s check the conditions in our three examples.
i. The 400 products were chosen at random.
ii. n = 400, p 0 = 0.2 and therefore:
\(n p_{0}=400(0.2)=80 \geq 10\)
\(n\left(1-p_{0}\right)=400(1-0.2)=320 \geq 10\)
i. The 100 students were chosen at random.
ii. n = 100, p 0 = 0.157 and therefore:
\begin{gathered} n p_{0}=100(0.157)=15.7 \geq 10 \\ n\left(1-p_{0}\right)=100(1-0.157)=84.3 \geq 10 \end{gathered}
i. The 1000 adults were chosen at random.
ii. n = 1000, p 0 = 0.64 and therefore:
\begin{gathered} n p_{0}=1000(0.64)=640 \geq 10 \\ n\left(1-p_{0}\right)=1000(1-0.64)=360 \geq 10 \end{gathered}
Learn by Doing: Proportions (Step 2) Verify Conditions
Checking that our data satisfy the conditions under which the test can be reliably used is a very important part of the hypothesis testing process. Be sure to consider this for every hypothesis test you conduct in this course and certainly in practice.
The Four Steps in Hypothesis Testing
With respect to the z-test, the population proportion that we are currently discussing we have:
Step 1: Completed
Step 2: Completed
Step 3: This is what we will work on next.
Proportions (Step 3)
Video: Proportions (Step 3) (14:46)
Calculators and Tables
Step 3. Finding the P-value of the Test
So far we’ve talked about the p-value at the intuitive level: understanding what it is (or what it measures) and how we use it to draw conclusions about the statistical significance of our results. We will now go more deeply into how the p-value is calculated.
It should be mentioned that eventually we will rely on technology to calculate the p-value for us (as well as the test statistic), but in order to make intelligent use of the output, it is important to first understand the details, and only then let the computer do the calculations for us. Again, our goal is to use this simple example to give you the tools you need to understand the process entirely. Let’s start.
Recall that so far we have said that the p-value is the probability of obtaining data like those observed assuming that Ho is true. Like the test statistic, the p-value is, therefore, a measure of the evidence against Ho. In the case of the test statistic, the larger it is in magnitude (positive or negative), the further p-hat is from p 0 , the more evidence we have against Ho. In the case of the p-value , it is the opposite; the smaller it is, the more unlikely it is to get data like those observed when Ho is true, the more evidence it is against Ho . One can actually draw conclusions in hypothesis testing just using the test statistic, and as we’ll see the p-value is, in a sense, just another way of looking at the test statistic. The reason that we actually take the extra step in this course and derive the p-value from the test statistic is that even though in this case (the test about the population proportion) and some other tests, the value of the test statistic has a very clear and intuitive interpretation, there are some tests where its value is not as easy to interpret. On the other hand, the p-value keeps its intuitive appeal across all statistical tests.
How is the p-value calculated?
Intuitively, the p-value is the probability of observing data like those observed assuming that Ho is true. Let’s be a bit more formal:
- Since this is a probability question about the data , it makes sense that the calculation will involve the data summary, the test statistic.
- What do we mean by “like” those observed? By “like” we mean “as extreme or even more extreme.”
Putting it all together, we get that in general:
The p-value is the probability of observing a test statistic as extreme as that observed (or even more extreme) assuming that the null hypothesis is true.
By “extreme” we mean extreme in the direction(s) of the alternative hypothesis.
Specifically , for the z-test for the population proportion:
- If the alternative hypothesis is Ha: p < p 0 (less than) , then “extreme” means small or less than , and the p-value is: The probability of observing a test statistic as small as that observed or smaller if the null hypothesis is true.
- If the alternative hypothesis is Ha: p > p 0 (greater than) , then “extreme” means large or greater than , and the p-value is: The probability of observing a test statistic as large as that observed or larger if the null hypothesis is true.
- If the alternative is Ha: p ≠ p 0 (different from) , then “extreme” means extreme in either direction either small or large (i.e., large in magnitude) or just different from , and the p-value therefore is: The probability of observing a test statistic as large in magnitude as that observed or larger if the null hypothesis is true.(Examples: If z = -2.5: p-value = probability of observing a test statistic as small as -2.5 or smaller or as large as 2.5 or larger. If z = 1.5: p-value = probability of observing a test statistic as large as 1.5 or larger, or as small as -1.5 or smaller.)
OK, hopefully that makes (some) sense. But how do we actually calculate it?
Recall the important comment from our discussion about our test statistic,

which said that when the null hypothesis is true (i.e., when p = p 0 ), the possible values of our test statistic follow a standard normal (N(0,1), denoted by Z) distribution. Therefore, the p-value calculations (which assume that Ho is true) are simply standard normal distribution calculations for the 3 possible alternative hypotheses.
Alternative Hypothesis is “Less Than”
The probability of observing a test statistic as small as that observed or smaller , assuming that the values of the test statistic follow a standard normal distribution. We will now represent this probability in symbols and also using the normal distribution.
Looking at the shaded region, you can see why this is often referred to as a left-tailed test. We shaded to the left of the test statistic, since less than is to the left.
Alternative Hypothesis is “Greater Than”
The probability of observing a test statistic as large as that observed or larger , assuming that the values of the test statistic follow a standard normal distribution. Again, we will represent this probability in symbols and using the normal distribution
Looking at the shaded region, you can see why this is often referred to as a right-tailed test. We shaded to the right of the test statistic, since greater than is to the right.
Alternative Hypothesis is “Not Equal To”
The probability of observing a test statistic which is as large in magnitude as that observed or larger, assuming that the values of the test statistic follow a standard normal distribution.
This is often referred to as a two-tailed test, since we shaded in both directions.
Next, we will apply this to our three examples. But first, work through the following activities, which should help your understanding.
Learn by Doing: Proportions (Step 3)
Did I Get This?: Proportions (Step 3)
The p-value in this case is:
- The probability of observing a test statistic as small as -2 or smaller, assuming that Ho is true.
OR (recalling what the test statistic actually means in this case),
- The probability of observing a sample proportion that is 2 standard deviations or more below the null value (p 0 = 0.20), assuming that p 0 is the true population proportion.
OR, more specifically,
- The probability of observing a sample proportion of 0.16 or lower in a random sample of size 400, when the true population proportion is p 0 =0.20
In either case, the p-value is found as shown in the following figure:
To find P(Z ≤ -2) we can either use the calculator or table we learned to use in the probability unit for normal random variables. Eventually, after we understand the details, we will use software to run the test for us and the output will give us all the information we need. The p-value that the statistical software provides for this specific example is 0.023. The p-value tells us that it is pretty unlikely (probability of 0.023) to get data like those observed (test statistic of -2 or less) assuming that Ho is true.
- The probability of observing a test statistic as large as 0.91 or larger, assuming that Ho is true.
- The probability of observing a sample proportion that is 0.91 standard deviations or more above the null value (p 0 = 0.157), assuming that p 0 is the true population proportion.
- The probability of observing a sample proportion of 0.19 or higher in a random sample of size 100, when the true population proportion is p 0 =0.157
Again, at this point we can either use the calculator or table to find that the p-value is 0.182, this is P(Z ≥ 0.91).
The p-value tells us that it is not very surprising (probability of 0.182) to get data like those observed (which yield a test statistic of 0.91 or higher) assuming that the null hypothesis is true.
- The probability of observing a test statistic as large as 2.31 (or larger) or as small as -2.31 (or smaller), assuming that Ho is true.
- The probability of observing a sample proportion that is 2.31 standard deviations or more away from the null value (p 0 = 0.64), assuming that p 0 is the true population proportion.
- The probability of observing a sample proportion as different as 0.675 is from 0.64, or even more different (i.e. as high as 0.675 or higher or as low as 0.605 or lower) in a random sample of size 1,000, when the true population proportion is p 0 = 0.64
Again, at this point we can either use the calculator or table to find that the p-value is 0.021, this is P(Z ≤ -2.31) + P(Z ≥ 2.31) = 2*P(Z ≥ |2.31|)
The p-value tells us that it is pretty unlikely (probability of 0.021) to get data like those observed (test statistic as high as 2.31 or higher or as low as -2.31 or lower) assuming that Ho is true.
- We’ve just seen that finding p-values involves probability calculations about the value of the test statistic assuming that Ho is true. In this case, when Ho is true, the values of the test statistic follow a standard normal distribution (i.e., the sampling distribution of the test statistic when the null hypothesis is true is N(0,1)). Therefore, p-values correspond to areas (probabilities) under the standard normal curve.
Similarly, in any test , p-values are found using the sampling distribution of the test statistic when the null hypothesis is true (also known as the “null distribution” of the test statistic). In this case, it was relatively easy to argue that the null distribution of our test statistic is N(0,1). As we’ll see, in other tests, other distributions come up (like the t-distribution and the F-distribution), which we will just mention briefly, and rely heavily on the output of our statistical package for obtaining the p-values.
We’ve just completed our discussion about the p-value, and how it is calculated both in general and more specifically for the z-test for the population proportion. Let’s go back to the four-step process of hypothesis testing and see what we’ve covered and what still needs to be discussed.
With respect to the z-test the population proportion:
Step 3: Completed
Step 4. This is what we will work on next.
Learn by Doing: Proportions (Step 3) Understanding P-values
Proportions (Step 4 & Summary)
Video: Proportions (Step 4 & Summary) (4:30)
Step 4. Drawing Conclusions Based on the P-Value
This last part of the four-step process of hypothesis testing is the same across all statistical tests, and actually, we’ve already said basically everything there is to say about it, but it can’t hurt to say it again.
The p-value is a measure of how much evidence the data present against Ho. The smaller the p-value, the more evidence the data present against Ho.
We already mentioned that what determines what constitutes enough evidence against Ho is the significance level (α, alpha), a cutoff point below which the p-value is considered small enough to reject Ho in favor of Ha. The most commonly used significance level is 0.05.
- Conclusion: There IS enough evidence that Ha is True
- Conclusion: There IS NOT enough evidence that Ha is True
Where instead of Ha is True , we write what this means in the words of the problem, in other words, in the context of the current scenario.
It is important to mention again that this step has essentially two sub-steps:
(i) Based on the p-value, determine whether or not the results are statistically significant (i.e., the data present enough evidence to reject Ho).
(ii) State your conclusions in the context of the problem.
Note: We always still must consider whether the results have any practical significance, particularly if they are statistically significant as a statistically significant result which has not practical use is essentially meaningless!
Let’s go back to our three examples and draw conclusions.
We found that the p-value for this test was 0.023.
Since 0.023 is small (in particular, 0.023 < 0.05), the data provide enough evidence to reject Ho.
Conclusion:
- There IS enough evidence that the proportion of defective products is less than 20% after the repair .
The following figure is the complete story of this example, and includes all the steps we went through, starting from stating the hypotheses and ending with our conclusions:
We found that the p-value for this test was 0.182.
Since .182 is not small (in particular, 0.182 > 0.05), the data do not provide enough evidence to reject Ho.
- There IS NOT enough evidence that the proportion of students at the college who use marijuana is higher than the national figure.
Here is the complete story of this example:
Learn by Doing: Learn by Doing – Proportions (Step 4)
We found that the p-value for this test was 0.021.
Since 0.021 is small (in particular, 0.021 < 0.05), the data provide enough evidence to reject Ho
- There IS enough evidence that the proportion of adults who support the death penalty for convicted murderers has changed since 2003.
Did I Get This?: Proportions (Step 4)
Many Students Wonder: Hypothesis Testing for the Population Proportion
Many students wonder why 5% is often selected as the significance level in hypothesis testing, and why 1% is the next most typical level. This is largely due to just convenience and tradition.
When Ronald Fisher (one of the founders of modern statistics) published one of his tables, he used a mathematically convenient scale that included 5% and 1%. Later, these same 5% and 1% levels were used by other people, in part just because Fisher was so highly esteemed. But mostly these are arbitrary levels.
The idea of selecting some sort of relatively small cutoff was historically important in the development of statistics; but it’s important to remember that there is really a continuous range of increasing confidence towards the alternative hypothesis, not a single all-or-nothing value. There isn’t much meaningful difference, for instance, between a p-value of .049 or .051, and it would be foolish to declare one case definitely a “real” effect and to declare the other case definitely a “random” effect. In either case, the study results were roughly 5% likely by chance if there’s no actual effect.
Whether such a p-value is sufficient for us to reject a particular null hypothesis ultimately depends on the risk of making the wrong decision, and the extent to which the hypothesized effect might contradict our prior experience or previous studies.
Let’s Summarize!!
We have now completed going through the four steps of hypothesis testing, and in particular we learned how they are applied to the z-test for the population proportion. Here is a brief summary:
Step 1: State the hypotheses
State the null hypothesis:
State the alternative hypothesis:
where the choice of the appropriate alternative (out of the three) is usually quite clear from the context of the problem. If you feel it is not clear, it is most likely a two-sided problem. Students are usually good at recognizing the “more than” and “less than” terminology but differences can sometimes be more difficult to spot, sometimes this is because you have preconceived ideas of how you think it should be! Use only the information given in the problem.
Step 2: Obtain data, check conditions, and summarize data
Obtain data from a sample and:
(i) Check whether the data satisfy the conditions which allow you to use this test.
random sample (or at least a sample that can be considered random in context)
the conditions under which the sampling distribution of p-hat is normal are met

(ii) Calculate the sample proportion p-hat, and summarize the data using the test statistic:

( Recall: This standardized test statistic represents how many standard deviations above or below p 0 our sample proportion p-hat is.)
Step 3: Find the p-value of the test by using the test statistic as follows
IMPORTANT FACT: In all future tests, we will rely on software to obtain the p-value.
When the alternative hypothesis is “less than” the probability of observing a test statistic as small as that observed or smaller , assuming that the values of the test statistic follow a standard normal distribution. We will now represent this probability in symbols and also using the normal distribution.
When the alternative hypothesis is “greater than” the probability of observing a test statistic as large as that observed or larger , assuming that the values of the test statistic follow a standard normal distribution. Again, we will represent this probability in symbols and using the normal distribution
When the alternative hypothesis is “not equal to” the probability of observing a test statistic which is as large in magnitude as that observed or larger, assuming that the values of the test statistic follow a standard normal distribution.
Step 4: Conclusion
Reach a conclusion first regarding the statistical significance of the results, and then determine what it means in the context of the problem.
If p-value ≤ 0.05 then WE REJECT Ho Conclusion: There IS enough evidence that Ha is True
If p-value > 0.05 then WE FAIL TO REJECT Ho Conclusion: There IS NOT enough evidence that Ha is True
Recall that: If the p-value is small (in particular, smaller than the significance level, which is usually 0.05), the results are statistically significant (in the sense that there is a statistically significant difference between what was observed in the sample and what was claimed in Ho), and so we reject Ho.
If the p-value is not small, we do not have enough statistical evidence to reject Ho, and so we continue to believe that Ho may be true. ( Remember: In hypothesis testing we never “accept” Ho ).
Finally, in practice, we should always consider the practical significance of the results as well as the statistical significance.
Learn by Doing: Z-Test for a Population Proportion
What’s next?
Before we move on to the next test, we are going to use the z-test for proportions to bring up and illustrate a few more very important issues regarding hypothesis testing. This might also be a good time to review the concepts of Type I error, Type II error, and Power before continuing on.
More about Hypothesis Testing
CO-1: Describe the roles biostatistics serves in the discipline of public health.
LO 1.11: Recognize the distinction between statistical significance and practical significance.
LO 6.30: Use a confidence interval to determine the correct conclusion to the associated two-sided hypothesis test.
Video: More about Hypothesis Testing (18:25)
The issues regarding hypothesis testing that we will discuss are:
- The effect of sample size on hypothesis testing.
- Statistical significance vs. practical importance.
- Hypothesis testing and confidence intervals—how are they related?
Let’s begin.
1. The Effect of Sample Size on Hypothesis Testing
We have already seen the effect that the sample size has on inference, when we discussed point and interval estimation for the population mean (μ, mu) and population proportion (p). Intuitively …
Larger sample sizes give us more information to pin down the true nature of the population. We can therefore expect the sample mean and sample proportion obtained from a larger sample to be closer to the population mean and proportion, respectively. As a result, for the same level of confidence, we can report a smaller margin of error, and get a narrower confidence interval. What we’ve seen, then, is that larger sample size gives a boost to how much we trust our sample results.
In hypothesis testing, larger sample sizes have a similar effect. We have also discussed that the power of our test increases when the sample size increases, all else remaining the same. This means, we have a better chance to detect the difference between the true value and the null value for larger samples.
The following two examples will illustrate that a larger sample size provides more convincing evidence (the test has greater power), and how the evidence manifests itself in hypothesis testing. Let’s go back to our example 2 (marijuana use at a certain liberal arts college).
We do not have enough evidence to conclude that the proportion of students at the college who use marijuana is higher than the national figure.
Now, let’s increase the sample size.
There are rumors that students in a certain liberal arts college are more inclined to use drugs than U.S. college students in general. Suppose that in a simple random sample of 400 students from the college, 76 admitted to marijuana use . Do the data provide enough evidence to conclude that the proportion of marijuana users among the students in the college (p) is higher than the national proportion, which is 0.157? (Reported by the Harvard School of Public Health).
Our results here are statistically significant . In other words, in example 2* the data provide enough evidence to reject Ho.
- Conclusion: There is enough evidence that the proportion of marijuana users at the college is higher than among all U.S. students.
What do we learn from this?
We see that sample results that are based on a larger sample carry more weight (have greater power).
In example 2, we saw that a sample proportion of 0.19 based on a sample of size of 100 was not enough evidence that the proportion of marijuana users in the college is higher than 0.157. Recall, from our general overview of hypothesis testing, that this conclusion (not having enough evidence to reject the null hypothesis) doesn’t mean the null hypothesis is necessarily true (so, we never “accept” the null); it only means that the particular study didn’t yield sufficient evidence to reject the null. It might be that the sample size was simply too small to detect a statistically significant difference.
However, in example 2*, we saw that when the sample proportion of 0.19 is obtained from a sample of size 400, it carries much more weight, and in particular, provides enough evidence that the proportion of marijuana users in the college is higher than 0.157 (the national figure). In this case, the sample size of 400 was large enough to detect a statistically significant difference.
The following activity will allow you to practice the ideas and terminology used in hypothesis testing when a result is not statistically significant.
Learn by Doing: Interpreting Non-significant Results
2. Statistical significance vs. practical importance.
Now, we will address the issue of statistical significance versus practical importance (which also involves issues of sample size).
The following activity will let you explore the effect of the sample size on the statistical significance of the results yourself, and more importantly will discuss issue 2: Statistical significance vs. practical importance.
Important Fact: In general, with a sufficiently large sample size you can make any result that has very little practical importance statistically significant! A large sample size alone does NOT make a “good” study!!
This suggests that when interpreting the results of a test, you should always think not only about the statistical significance of the results but also about their practical importance.
Learn by Doing: Statistical vs. Practical Significance
3. Hypothesis Testing and Confidence Intervals
The last topic we want to discuss is the relationship between hypothesis testing and confidence intervals. Even though the flavor of these two forms of inference is different (confidence intervals estimate a parameter, and hypothesis testing assesses the evidence in the data against one claim and in favor of another), there is a strong link between them.
We will explain this link (using the z-test and confidence interval for the population proportion), and then explain how confidence intervals can be used after a test has been carried out.
Recall that a confidence interval gives us a set of plausible values for the unknown population parameter. We may therefore examine a confidence interval to informally decide if a proposed value of population proportion seems plausible.
For example, if a 95% confidence interval for p, the proportion of all U.S. adults already familiar with Viagra in May 1998, was (0.61, 0.67), then it seems clear that we should be able to reject a claim that only 50% of all U.S. adults were familiar with the drug, since based on the confidence interval, 0.50 is not one of the plausible values for p.
In fact, the information provided by a confidence interval can be formally related to the information provided by a hypothesis test. ( Comment: The relationship is more straightforward for two-sided alternatives, and so we will not present results for the one-sided cases.)
Suppose we want to carry out the two-sided test:
- Ha: p ≠ p 0
using a significance level of 0.05.
An alternative way to perform this test is to find a 95% confidence interval for p and check:
- If p 0 falls outside the confidence interval, reject Ho.
- If p 0 falls inside the confidence interval, do not reject Ho.
In other words,
- If p 0 is not one of the plausible values for p, we reject Ho.
- If p 0 is a plausible value for p, we cannot reject Ho.
( Comment: Similarly, the results of a test using a significance level of 0.01 can be related to the 99% confidence interval.)
Let’s look at an example:
Recall example 3, where we wanted to know whether the proportion of U.S. adults who support the death penalty for convicted murderers has changed since 2003, when it was 0.64.
We are testing:
and as the figure reminds us, we took a sample of 1,000 U.S. adults, and the data told us that 675 supported the death penalty for convicted murderers (p-hat = 0.675).
A 95% confidence interval for p, the proportion of all U.S. adults who support the death penalty, is:
\(0.675 \pm 1.96 \sqrt{\dfrac{0.675(1-0.675)}{1000}} \approx 0.675 \pm 0.029=(0.646,0.704)\)
Since the 95% confidence interval for p does not include 0.64 as a plausible value for p, we can reject Ho and conclude (as we did before) that there is enough evidence that the proportion of U.S. adults who support the death penalty for convicted murderers has changed since 2003.
You and your roommate are arguing about whose turn it is to clean the apartment. Your roommate suggests that you settle this by tossing a coin and takes one out of a locked box he has on the shelf. Suspecting that the coin might not be fair, you decide to test it first. You toss the coin 80 times, thinking to yourself that if, indeed, the coin is fair, you should get around 40 heads. Instead you get 48 heads. You are puzzled. You are not sure whether getting 48 heads out of 80 is enough evidence to conclude that the coin is unbalanced, or whether this a result that could have happened just by chance when the coin is fair.
Statistics can help you answer this question.
Let p be the true proportion (probability) of heads. We want to test whether the coin is fair or not.
- Ho: p = 0.5 (the coin is fair).
- Ha: p ≠ 0.5 (the coin is not fair).
The data we have are that out of n = 80 tosses, we got 48 heads, or that the sample proportion of heads is p-hat = 48/80 = 0.6.
A 95% confidence interval for p, the true proportion of heads for this coin, is:
\(0.6 \pm 1.96 \sqrt{\dfrac{0.6(1-0.6)}{80}} \approx 0.6 \pm 0.11=(0.49,0.71)\)
Since in this case 0.5 is one of the plausible values for p, we cannot reject Ho. In other words, the data do not provide enough evidence to conclude that the coin is not fair.
The context of the last example is a good opportunity to bring up an important point that was discussed earlier.
Even though we use 0.05 as a cutoff to guide our decision about whether the results are statistically significant, we should not treat it as inviolable and we should always add our own judgment. Let’s look at the last example again.
It turns out that the p-value of this test is 0.0734. In other words, it is maybe not extremely unlikely, but it is quite unlikely (probability of 0.0734) that when you toss a fair coin 80 times you’ll get a sample proportion of heads of 48/80 = 0.6 (or even more extreme). It is true that using the 0.05 significance level (cutoff), 0.0734 is not considered small enough to conclude that the coin is not fair. However, if you really don’t want to clean the apartment, the p-value might be small enough for you to ask your roommate to use a different coin, or to provide one yourself!
Did I Get This?: Connection between Confidence Intervals and Hypothesis Tests
Did I Get This?: Hypothesis Tests for Proportions (Extra Practice)
Here is our final point on this subject:
When the data provide enough evidence to reject Ho, we can conclude (depending on the alternative hypothesis) that the population proportion is either less than, greater than, or not equal to the null value p 0 . However, we do not get a more informative statement about its actual value. It might be of interest, then, to follow the test with a 95% confidence interval that will give us more insight into the actual value of p.
In our example 3,
we concluded that the proportion of U.S. adults who support the death penalty for convicted murderers has changed since 2003, when it was 0.64. It is probably of interest not only to know that the proportion has changed, but also to estimate what it has changed to. We’ve calculated the 95% confidence interval for p on the previous page and found that it is (0.646, 0.704).
We can combine our conclusions from the test and the confidence interval and say:
Data provide evidence that the proportion of U.S. adults who support the death penalty for convicted murderers has changed since 2003, and we are 95% confident that it is now between 0.646 and 0.704. (i.e. between 64.6% and 70.4%).
Let’s look at our example 1 to see how a confidence interval following a test might be insightful in a different way.
Here is a summary of example 1:
We conclude that as a result of the repair, the proportion of defective products has been reduced to below 0.20 (which was the proportion prior to the repair). It is probably of great interest to the company not only to know that the proportion of defective has been reduced, but also estimate what it has been reduced to, to get a better sense of how effective the repair was. A 95% confidence interval for p in this case is:
\(0.16 \pm 1.96 \sqrt{\dfrac{0.16(1-0.16)}{400}} \approx 0.16 \pm 0.036=(0.124,0.196)\)
We can therefore say that the data provide evidence that the proportion of defective products has been reduced, and we are 95% confident that it has been reduced to somewhere between 12.4% and 19.6%. This is very useful information, since it tells us that even though the results were significant (i.e., the repair reduced the number of defective products), the repair might not have been effective enough, if it managed to reduce the number of defective products only to the range provided by the confidence interval. This, of course, ties back in to the idea of statistical significance vs. practical importance that we discussed earlier. Even though the results are statistically significant (Ho was rejected), practically speaking, the repair might still be considered ineffective.
Learn by Doing: Hypothesis Tests and Confidence Intervals
Even though this portion of the current section is about the z-test for population proportion, it is loaded with very important ideas that apply to hypothesis testing in general. We’ve already summarized the details that are specific to the z-test for proportions, so the purpose of this summary is to highlight the general ideas.
The process of hypothesis testing has four steps :
I. Stating the null and alternative hypotheses (Ho and Ha).
II. Obtaining a random sample (or at least one that can be considered random) and collecting data. Using the data:
Check that the conditions under which the test can be reliably used are met.
Summarize the data using a test statistic.
- The test statistic is a measure of the evidence in the data against Ho. The larger the test statistic is in magnitude, the more evidence the data present against Ho.
III. Finding the p-value of the test. The p-value is the probability of getting data like those observed (or even more extreme) assuming that the null hypothesis is true, and is calculated using the null distribution of the test statistic. The p-value is a measure of the evidence against Ho. The smaller the p-value, the more evidence the data present against Ho.
IV. Making conclusions.
Conclusions about the statistical significance of the results:
If the p-value is small, the data present enough evidence to reject Ho (and accept Ha).
If the p-value is not small, the data do not provide enough evidence to reject Ho.
To help guide our decision, we use the significance level as a cutoff for what is considered a small p-value. The significance cutoff is usually set at 0.05.
Conclusions should then be provided in the context of the problem.
Additional Important Ideas about Hypothesis Testing
- Results that are based on a larger sample carry more weight, and therefore as the sample size increases, results become more statistically significant.
- Even a very small and practically unimportant effect becomes statistically significant with a large enough sample size. The distinction between statistical significance and practical importance should therefore always be considered.
- Confidence intervals can be used in order to carry out two-sided tests (95% confidence for the 0.05 significance level). If the null value is not included in the confidence interval (i.e., is not one of the plausible values for the parameter), we have enough evidence to reject Ho. Otherwise, we cannot reject Ho.
- If the results are statistically significant, it might be of interest to follow up the tests with a confidence interval in order to get insight into the actual value of the parameter of interest.
- It is important to be aware that there are two types of errors in hypothesis testing ( Type I and Type II ) and that the power of a statistical test is an important measure of how likely we are to be able to detect a difference of interest to us in a particular problem.
Means (All Steps)
NOTE: Beginning on this page, the Learn By Doing and Did I Get This activities are presented as interactive PDF files. The interactivity may not work on mobile devices or with certain PDF viewers. Use an official ADOBE product such as ADOBE READER .
If you have any issues with the Learn By Doing or Did I Get This interactive PDF files, you can view all of the questions and answers presented on this page in this document:
- QUESTION/Answer (SPOILER ALERT!)
Tests About μ (mu) When σ (sigma) is Unknown – The t-test for a Population Mean
The t-distribution.
Video: Means (All Steps) (13:11)
So far we have talked about the logic behind hypothesis testing and then illustrated how this process proceeds in practice, using the z-test for the population proportion (p).
We are now moving on to discuss testing for the population mean (μ, mu), which is the parameter of interest when the variable of interest is quantitative.
A few comments about the structure of this section:
- The basic groundwork for carrying out hypothesis tests has already been laid in our general discussion and in our presentation of tests about proportions.
Therefore we can easily modify the four steps to carry out tests about means instead, without going into all of the details again.
We will use this approach for all future tests so be sure to go back to the discussion in general and for proportions to review the concepts in more detail.
- In our discussion about confidence intervals for the population mean, we made the distinction between whether the population standard deviation, σ (sigma) was known or if we needed to estimate this value using the sample standard deviation, s .
In this section, we will only discuss the second case as in most realistic settings we do not know the population standard deviation .
In this case we need to use the t- distribution instead of the standard normal distribution for the probability aspects of confidence intervals (choosing table values) and hypothesis tests (finding p-values).
- Although we will discuss some theoretical or conceptual details for some of the analyses we will learn, from this point on we will rely on software to conduct tests and calculate confidence intervals for us , while we focus on understanding which methods are used for which situations and what the results say in context.
If you are interested in more information about the z-test, where we assume the population standard deviation σ (sigma) is known, you can review the Carnegie Mellon Open Learning Statistics Course (you will need to click “ENTER COURSE”).
Like any other tests, the t- test for the population mean follows the four-step process:
- STEP 1: Stating the hypotheses H o and H a .
- STEP 2: Collecting relevant data, checking that the data satisfy the conditions which allow us to use this test, and summarizing the data using a test statistic.
- STEP 3: Finding the p-value of the test, the probability of obtaining data as extreme as those collected (or even more extreme, in the direction of the alternative hypothesis), assuming that the null hypothesis is true. In other words, how likely is it that the only reason for getting data like those observed is sampling variability (and not because H o is not true)?
- STEP 4: Drawing conclusions, assessing the statistical significance of the results based on the p-value, and stating our conclusions in context. (Do we or don’t we have evidence to reject H o and accept H a ?)
- Note: In practice, we should also always consider the practical significance of the results as well as the statistical significance.
We will now go through the four steps specifically for the t- test for the population mean and apply them to our two examples.
Only in a few cases is it reasonable to assume that the population standard deviation, σ (sigma), is known and so we will not cover hypothesis tests in this case. We discussed both cases for confidence intervals so that we could still calculate some confidence intervals by hand.
For this and all future tests we will rely on software to obtain our summary statistics, test statistics, and p-values for us.
The case where σ (sigma) is unknown is much more common in practice. What can we use to replace σ (sigma)? If you don’t know the population standard deviation, the best you can do is find the sample standard deviation, s, and use it instead of σ (sigma). (Note that this is exactly what we did when we discussed confidence intervals).
Is that it? Can we just use s instead of σ (sigma), and the rest is the same as the previous case? Unfortunately, it’s not that simple, but not very complicated either.
Here, when we use the sample standard deviation, s, as our estimate of σ (sigma) we can no longer use a normal distribution to find the cutoff for confidence intervals or the p-values for hypothesis tests.
Instead we must use the t- distribution (with n-1 degrees of freedom) to obtain the p-value for this test.
We discussed this issue for confidence intervals. We will talk more about the t- distribution after we discuss the details of this test for those who are interested in learning more.
It isn’t really necessary for us to understand this distribution but it is important that we use the correct distributions in practice via our software.
We will wait until UNIT 4B to look at how to accomplish this test in the software. For now focus on understanding the process and drawing the correct conclusions from the p-values given.
Now let’s go through the four steps in conducting the t- test for the population mean.
The null and alternative hypotheses for the t- test for the population mean (μ, mu) have exactly the same structure as the hypotheses for z-test for the population proportion (p):
The null hypothesis has the form:
- Ho: μ = μ 0 (mu = mu_zero)
(where μ 0 (mu_zero) is often called the null value)
- Ha: μ < μ 0 (mu < mu_zero) (one-sided)
- Ha: μ > μ 0 (mu > mu_zero) (one-sided)
- Ha: μ ≠ μ 0 (mu ≠ mu_zero) (two-sided)
where the choice of the appropriate alternative (out of the three) is usually quite clear from the context of the problem.
If you feel it is not clear, it is most likely a two-sided problem. Students are usually good at recognizing the “more than” and “less than” terminology but differences can sometimes be more difficult to spot, sometimes this is because you have preconceived ideas of how you think it should be! You also cannot use the information from the sample to help you determine the hypothesis. We would not know our data when we originally asked the question.
Now try it yourself. Here are a few exercises on stating the hypotheses for tests for a population mean.
Learn by Doing: State the Hypotheses for a test for a population mean
Here are a few more activities for practice.
Did I Get This?: State the Hypotheses for a test for a population mean
When setting up hypotheses, be sure to use only the information in the research question. We cannot use our sample data to help us set up our hypotheses.
For this test, it is still important to correctly choose the alternative hypothesis as “less than”, “greater than”, or “different” although generally in practice two-sample tests are used.
Obtain data from a sample:
- In this step we would obtain data from a sample. This is not something we do much of in courses but it is done very often in practice!
Check the conditions:
- Then we check the conditions under which this test (the t- test for one population mean) can be safely carried out – which are:
- The sample is random (or at least can be considered random in context).
- We are in one of the three situations marked with a green check mark in the following table (which ensure that x-bar is at least approximately normal and the test statistic using the sample standard deviation, s, is therefore a t- distribution with n-1 degrees of freedom – proving this is beyond the scope of this course):
- For large samples, we don’t need to check for normality in the population . We can rely on the sample size as the basis for the validity of using this test.
- For small samples , we need to have data from a normal population in order for the p-values and confidence intervals to be valid.
In practice, for small samples, it can be very difficult to determine if the population is normal. Here is a simulation to give you a better understanding of the difficulties.
Video: Simulations – Are Samples from a Normal Population? (4:58)
Now try it yourself with a few activities.
Learn by Doing: Checking Conditions for Hypothesis Testing for the Population Mean
- It is always a good idea to look at the data and get a sense of their pattern regardless of whether you actually need to do it in order to assess whether the conditions are met.
- This idea of looking at the data is relevant to all tests in general. In the next module—inference for relationships—conducting exploratory data analysis before inference will be an integral part of the process.
Here are a few more problems for extra practice.
Did I Get This?: Checking Conditions for Hypothesis Testing for the Population Mean
When setting up hypotheses, be sure to use only the information in the res
Calculate Test Statistic
Assuming that the conditions are met, we calculate the sample mean x-bar and the sample standard deviation, s (which estimates σ (sigma)), and summarize the data with a test statistic.
The test statistic for the t -test for the population mean is:
\(t=\dfrac{\bar{x} - \mu_0}{s/ \sqrt{n}}\)
Recall that such a standardized test statistic represents how many standard deviations above or below μ 0 (mu_zero) our sample mean x-bar is.
Therefore our test statistic is a measure of how different our data are from what is claimed in the null hypothesis. This is an idea that we mentioned in the previous test as well.
Again we will rely on the p-value to determine how unusual our data would be if the null hypothesis is true.
As we mentioned, the test statistic in the t -test for a population mean does not follow a standard normal distribution. Rather, it follows another bell-shaped distribution called the t- distribution.
We will present the details of this distribution at the end for those interested but for now we will work on the process of the test.
Here are a few important facts.
- In statistical language we say that the null distribution of our test statistic is the t- distribution with (n-1) degrees of freedom. In other words, when Ho is true (i.e., when μ = μ 0 (mu = mu_zero)), our test statistic has a t- distribution with (n-1) d.f., and this is the distribution under which we find p-values.
- For a large sample size (n), the null distribution of the test statistic is approximately Z, so whether we use t (n – 1) or Z to calculate the p-values does not make a big difference. However, software will use the t -distribution regardless of the sample size and so will we.
Although we will not calculate p-values by hand for this test, we can still easily calculate the test statistic.
Try it yourself:
Learn by Doing: Calculate the Test Statistic for a Test for a Population Mean
From this point in this course and certainly in practice we will allow the software to calculate our test statistics and we will use the p-values provided to draw our conclusions.
We will use software to obtain the p-value for this (and all future) tests but here are the images illustrating how the p-value is calculated in each of the three cases corresponding to the three choices for our alternative hypothesis.
Note that due to the symmetry of the t distribution, for a given value of the test statistic t, the p-value for the two-sided test is twice as large as the p-value of either of the one-sided tests. The same thing happens when p-values are calculated under the t distribution as when they are calculated under the Z distribution.
We will show some examples of p-values obtained from software in our examples. For now let’s continue our summary of the steps.
As usual, based on the p-value (and some significance level of choice) we assess the statistical significance of results, and draw our conclusions in context.
To review what we have said before:
If p-value ≤ 0.05 then WE REJECT Ho
If p-value > 0.05 then WE FAIL TO REJECT Ho
This step has essentially two sub-steps:
We are now ready to look at two examples.
A certain prescription medicine is supposed to contain an average of 250 parts per million (ppm) of a certain chemical. If the concentration is higher than this, the drug may cause harmful side effects; if it is lower, the drug may be ineffective.
The manufacturer runs a check to see if the mean concentration in a large shipment conforms to the target level of 250 ppm or not.
A simple random sample of 100 portions is tested, and the sample mean concentration is found to be 247 ppm with a sample standard deviation of 12 ppm.
Here is a figure that represents this example:
.\" Selected from the population is a sample of size n=100, represented by a smaller circle. x-bar for this sample is 247.")
1. The hypotheses being tested are:
- Ha: μ ≠ μ 0 (mu ≠ mu_zero)
- Where μ = population mean part per million of the chemical in the entire shipment
2. The conditions that allow us to use the t-test are met since:
- The sample is random
- The sample size is large enough for the Central Limit Theorem to apply and ensure the normality of x-bar. We do not need normality of the population in order to be able to conduct this test for the population mean. We are in the 2 nd column in the table below.
- The test statistic is:
\(t=\dfrac{\bar{x}-\mu_{0}}{s / \sqrt{n}}=\dfrac{247-250}{12 / \sqrt{100}}=-2.5\)
- The data (represented by the sample mean) are 2.5 standard errors below the null value.
3. Finding the p-value.
- To find the p-value we use statistical software, and we calculate a p-value of 0.014.
4. Conclusions:
- The p-value is small (.014) indicating that at the 5% significance level, the results are significant.
- We reject the null hypothesis.
- There is enough evidence to conclude that the mean concentration in entire shipment is not the required 250 ppm.
- It is difficult to comment on the practical significance of this result without more understanding of the practical considerations of this problem.
Here is a summary:
- The 95% confidence interval for μ (mu) can be used here in the same way as for proportions to conduct the two-sided test (checking whether the null value falls inside or outside the confidence interval) or following a t- test where Ho was rejected to get insight into the value of μ (mu).
- We find the 95% confidence interval to be (244.619, 249.381) . Since 250 is not in the interval we know we would reject our null hypothesis that μ (mu) = 250. The confidence interval gives additional information. By accounting for estimation error, it estimates that the population mean is likely to be between 244.62 and 249.38. This is lower than the target concentration and that information might help determine the seriousness and appropriate course of action in this situation.
In most situations in practice we use TWO-SIDED HYPOTHESIS TESTS, followed by confidence intervals to gain more insight.
For completeness in covering one sample t-tests for a population mean, we still cover all three possible alternative hypotheses here HOWEVER, this will be the last test for which we will do so.
A research study measured the pulse rates of 57 college men and found a mean pulse rate of 70 beats per minute with a standard deviation of 9.85 beats per minute.
Researchers want to know if the mean pulse rate for all college men is different from the current standard of 72 beats per minute.
- The hypotheses being tested are:
- Ho: μ = 72
- Ha: μ ≠ 72
- Where μ = population mean heart rate among college men
- The conditions that allow us to use the t- test are met since:
- The sample is random.
- The sample size is large (n = 57) so we do not need normality of the population in order to be able to conduct this test for the population mean. We are in the 2 nd column in the table below.
\(t=\dfrac{\bar{x}-\mu}{s / \sqrt{n}}=\dfrac{70-72}{9.85 / \sqrt{57}}=-1.53\)
- The data (represented by the sample mean) are 1.53 estimated standard errors below the null value.
- Recall that in general the p-value is calculated under the null distribution of the test statistic, which, in the t- test case, is t (n-1). In our case, in which n = 57, the p-value is calculated under the t (56) distribution. Using statistical software, we find that the p-value is 0.132 .
- Here is how we calculated the p-value. http://homepage.stat.uiowa.edu/~mbognar/applets/t.html .
 curve, for which the horizontal axis has been labeled with t-scores of -2.5 and 2.5 . The area under the curve and to the left of -1.53 and to the right of 1.53 is the p-value.")
4. Making conclusions.
- The p-value (0.132) is not small, indicating that the results are not significant.
- We fail to reject the null hypothesis.
- There is not enough evidence to conclude that the mean pulse rate for all college men is different from the current standard of 72 beats per minute.
- The results from this sample do not appear to have any practical significance either with a mean pulse rate of 70, this is very similar to the hypothesized value, relative to the variation expected in pulse rates.
Now try a few yourself.
Learn by Doing: Hypothesis Testing for the Population Mean
From this point in this course and certainly in practice we will allow the software to calculate our test statistic and p-value and we will use the p-values provided to draw our conclusions.
That concludes our discussion of hypothesis tests in Unit 4A.
In the next unit we will continue to use both confidence intervals and hypothesis test to investigate the relationship between two variables in the cases we covered in Unit 1 on exploratory data analysis – we will look at Case CQ, Case CC, and Case QQ.
Before moving on, we will discuss the details about the t- distribution as a general object.
We have seen that variables can be visually modeled by many different sorts of shapes, and we call these shapes distributions. Several distributions arise so frequently that they have been given special names, and they have been studied mathematically.
So far in the course, the only one we’ve named, for continuous quantitative variables, is the normal distribution, but there are others. One of them is called the t- distribution.
The t- distribution is another bell-shaped (unimodal and symmetric) distribution, like the normal distribution; and the center of the t- distribution is standardized at zero, like the center of the standard normal distribution.
Like all distributions that are used as probability models, the normal and the t- distribution are both scaled, so the total area under each of them is 1.
So how is the t-distribution fundamentally different from the normal distribution?
- The spread .
The following picture illustrates the fundamental difference between the normal distribution and the t-distribution:
Here we have an image which illustrates the fundamental difference between the normal distribution and the t- distribution:
You can see in the picture that the t- distribution has slightly less area near the expected central value than the normal distribution does, and you can see that the t distribution has correspondingly more area in the “tails” than the normal distribution does. (It’s often said that the t- distribution has “fatter tails” or “heavier tails” than the normal distribution.)
This reflects the fact that the t- distribution has a larger spread than the normal distribution. The same total area of 1 is spread out over a slightly wider range on the t- distribution, making it a bit lower near the center compared to the normal distribution, and giving the t- distribution slightly more probability in the ‘tails’ compared to the normal distribution.
Therefore, the t- distribution ends up being the appropriate model in certain cases where there is more variability than would be predicted by the normal distribution. One of these cases is stock values, which have more variability (or “volatility,” to use the economic term) than would be predicted by the normal distribution.
There’s actually an entire family of t- distributions. They all have similar formulas (but the math is beyond the scope of this introductory course in statistics), and they all have slightly “fatter tails” than the normal distribution. But some are closer to normal than others.
The t- distributions that have higher “degrees of freedom” are closer to normal (degrees of freedom is a mathematical concept that we won’t study in this course, beyond merely mentioning it here). So, there’s a t- distribution “with one degree of freedom,” another t- distribution “with 2 degrees of freedom” which is slightly closer to normal, another t- distribution “with 3 degrees of freedom” which is a bit closer to normal than the previous ones, and so on.
The following picture illustrates this idea with just a couple of t- distributions (note that “degrees of freedom” is abbreviated “d.f.” on the picture):
The test statistic for our t-test for one population mean is a t -score which follows a t- distribution with (n – 1) degrees of freedom. Recall that each t- distribution is indexed according to “degrees of freedom.” Notice that, in the context of a test for a mean, the degrees of freedom depend on the sample size in the study.
Remember that we said that higher degrees of freedom indicate that the t- distribution is closer to normal. So in the context of a test for the mean, the larger the sample size , the higher the degrees of freedom, and the closer the t- distribution is to a normal z distribution .
As a result, in the context of a test for a mean, the effect of the t- distribution is most important for a study with a relatively small sample size .
We are now done introducing the t-distribution. What are implications of all of this?
- The null distribution of our t-test statistic is the t-distribution with (n-1) d.f. In other words, when Ho is true (i.e., when μ = μ 0 (mu = mu_zero)), our test statistic has a t-distribution with (n-1) d.f., and this is the distribution under which we find p-values.
- For a large sample size (n), the null distribution of the test statistic is approximately Z, so whether we use t(n – 1) or Z to calculate the p-values does not make a big difference.
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Best Family Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Guided Meditations
- Verywell Mind Insights
- 2023 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
How to Write a Great Hypothesis
Hypothesis Format, Examples, and Tips
Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
:max_bytes(150000):strip_icc():format(webp)/IMG_9791-89504ab694d54b66bbd72cb84ffb860e.jpg "hypothesis with data")
Amy Morin, LCSW, is a psychotherapist and international bestselling author. Her books, including "13 Things Mentally Strong People Don't Do," have been translated into more than 40 languages. Her TEDx talk, "The Secret of Becoming Mentally Strong," is one of the most viewed talks of all time.
:max_bytes(150000):strip_icc():format(webp)/VW-MIND-Amy-2b338105f1ee493f94d7e333e410fa76.jpg "hypothesis with data")
Verywell / Alex Dos Diaz
- The Scientific Method
Hypothesis Format
Falsifiability of a hypothesis, operational definitions, types of hypotheses, hypotheses examples.
- Collecting Data
Frequently Asked Questions
A hypothesis is a tentative statement about the relationship between two or more variables. It is a specific, testable prediction about what you expect to happen in a study.
One hypothesis example would be a study designed to look at the relationship between sleep deprivation and test performance might have a hypothesis that states: "This study is designed to assess the hypothesis that sleep-deprived people will perform worse on a test than individuals who are not sleep-deprived."
This article explores how a hypothesis is used in psychology research, how to write a good hypothesis, and the different types of hypotheses you might use.
The Hypothesis in the Scientific Method
In the scientific method , whether it involves research in psychology, biology, or some other area, a hypothesis represents what the researchers think will happen in an experiment. The scientific method involves the following steps:
- Forming a question
- Performing background research
- Creating a hypothesis
- Designing an experiment
- Collecting data
- Analyzing the results
- Drawing conclusions
- Communicating the results
The hypothesis is a prediction, but it involves more than a guess. Most of the time, the hypothesis begins with a question which is then explored through background research. It is only at this point that researchers begin to develop a testable hypothesis. Unless you are creating an exploratory study, your hypothesis should always explain what you expect to happen.
In a study exploring the effects of a particular drug, the hypothesis might be that researchers expect the drug to have some type of effect on the symptoms of a specific illness. In psychology, the hypothesis might focus on how a certain aspect of the environment might influence a particular behavior.
Remember, a hypothesis does not have to be correct. While the hypothesis predicts what the researchers expect to see, the goal of the research is to determine whether this guess is right or wrong. When conducting an experiment, researchers might explore a number of factors to determine which ones might contribute to the ultimate outcome.
In many cases, researchers may find that the results of an experiment do not support the original hypothesis. When writing up these results, the researchers might suggest other options that should be explored in future studies.
In many cases, researchers might draw a hypothesis from a specific theory or build on previous research. For example, prior research has shown that stress can impact the immune system. So a researcher might hypothesize: "People with high-stress levels will be more likely to contract a common cold after being exposed to the virus than people who have low-stress levels."
In other instances, researchers might look at commonly held beliefs or folk wisdom. "Birds of a feather flock together" is one example of folk wisdom that a psychologist might try to investigate. The researcher might pose a specific hypothesis that "People tend to select romantic partners who are similar to them in interests and educational level."
Elements of a Good Hypothesis
So how do you write a good hypothesis? When trying to come up with a hypothesis for your research or experiments, ask yourself the following questions:
- Is your hypothesis based on your research on a topic?
- Can your hypothesis be tested?
- Does your hypothesis include independent and dependent variables?
Before you come up with a specific hypothesis, spend some time doing background research. Once you have completed a literature review, start thinking about potential questions you still have. Pay attention to the discussion section in the journal articles you read . Many authors will suggest questions that still need to be explored.
To form a hypothesis, you should take these steps:
- Collect as many observations about a topic or problem as you can.
- Evaluate these observations and look for possible causes of the problem.
- Create a list of possible explanations that you might want to explore.
- After you have developed some possible hypotheses, think of ways that you could confirm or disprove each hypothesis through experimentation. This is known as falsifiability.
In the scientific method , falsifiability is an important part of any valid hypothesis. In order to test a claim scientifically, it must be possible that the claim could be proven false.
Students sometimes confuse the idea of falsifiability with the idea that it means that something is false, which is not the case. What falsifiability means is that if something was false, then it is possible to demonstrate that it is false.
One of the hallmarks of pseudoscience is that it makes claims that cannot be refuted or proven false.
A variable is a factor or element that can be changed and manipulated in ways that are observable and measurable. However, the researcher must also define how the variable will be manipulated and measured in the study.
For example, a researcher might operationally define the variable " test anxiety " as the results of a self-report measure of anxiety experienced during an exam. A "study habits" variable might be defined by the amount of studying that actually occurs as measured by time.
These precise descriptions are important because many things can be measured in a number of different ways. One of the basic principles of any type of scientific research is that the results must be replicable. By clearly detailing the specifics of how the variables were measured and manipulated, other researchers can better understand the results and repeat the study if needed.
Some variables are more difficult than others to define. How would you operationally define a variable such as aggression ? For obvious ethical reasons, researchers cannot create a situation in which a person behaves aggressively toward others.
In order to measure this variable, the researcher must devise a measurement that assesses aggressive behavior without harming other people. In this situation, the researcher might utilize a simulated task to measure aggressiveness.
Hypothesis Checklist
- Does your hypothesis focus on something that you can actually test?
- Does your hypothesis include both an independent and dependent variable?
- Can you manipulate the variables?
- Can your hypothesis be tested without violating ethical standards?
The hypothesis you use will depend on what you are investigating and hoping to find. Some of the main types of hypotheses that you might use include:
- Simple hypothesis : This type of hypothesis suggests that there is a relationship between one independent variable and one dependent variable.
- Complex hypothesis : This type of hypothesis suggests a relationship between three or more variables, such as two independent variables and a dependent variable.
- Null hypothesis : This hypothesis suggests no relationship exists between two or more variables.
- Alternative hypothesis : This hypothesis states the opposite of the null hypothesis.
- Statistical hypothesis : This hypothesis uses statistical analysis to evaluate a representative sample of the population and then generalizes the findings to the larger group.
- Logical hypothesis : This hypothesis assumes a relationship between variables without collecting data or evidence.
A hypothesis often follows a basic format of "If {this happens} then {this will happen}." One way to structure your hypothesis is to describe what will happen to the dependent variable if you change the independent variable .
The basic format might be: "If {these changes are made to a certain independent variable}, then we will observe {a change in a specific dependent variable}."
A few examples of simple hypotheses:
- "Students who eat breakfast will perform better on a math exam than students who do not eat breakfast."
- Complex hypothesis: "Students who experience test anxiety before an English exam will get lower scores than students who do not experience test anxiety."
- "Motorists who talk on the phone while driving will be more likely to make errors on a driving course than those who do not talk on the phone."
Examples of a complex hypothesis include:
- "People with high-sugar diets and sedentary activity levels are more likely to develop depression."
- "Younger people who are regularly exposed to green, outdoor areas have better subjective well-being than older adults who have limited exposure to green spaces."
Examples of a null hypothesis include:
- "Children who receive a new reading intervention will have scores different than students who do not receive the intervention."
- "There will be no difference in scores on a memory recall task between children and adults."
Examples of an alternative hypothesis:
- "Children who receive a new reading intervention will perform better than students who did not receive the intervention."
- "Adults will perform better on a memory task than children."
Collecting Data on Your Hypothesis
Once a researcher has formed a testable hypothesis, the next step is to select a research design and start collecting data. The research method depends largely on exactly what they are studying. There are two basic types of research methods: descriptive research and experimental research.
Descriptive Research Methods
Descriptive research such as case studies , naturalistic observations , and surveys are often used when it would be impossible or difficult to conduct an experiment . These methods are best used to describe different aspects of a behavior or psychological phenomenon.
Once a researcher has collected data using descriptive methods, a correlational study can then be used to look at how the variables are related. This type of research method might be used to investigate a hypothesis that is difficult to test experimentally.
Experimental Research Methods
Experimental methods are used to demonstrate causal relationships between variables. In an experiment, the researcher systematically manipulates a variable of interest (known as the independent variable) and measures the effect on another variable (known as the dependent variable).
Unlike correlational studies, which can only be used to determine if there is a relationship between two variables, experimental methods can be used to determine the actual nature of the relationship—whether changes in one variable actually cause another to change.
A Word From Verywell
The hypothesis is a critical part of any scientific exploration. It represents what researchers expect to find in a study or experiment. In situations where the hypothesis is unsupported by the research, the research still has value. Such research helps us better understand how different aspects of the natural world relate to one another. It also helps us develop new hypotheses that can then be tested in the future.
Some examples of how to write a hypothesis include:
- "Staying up late will lead to worse test performance the next day."
- "People who consume one apple each day will visit the doctor fewer times each year."
- "Breaking study sessions up into three 20-minute sessions will lead to better test results than a single 60-minute study session."
The four parts of a hypothesis are:
- The research question
- The independent variable (IV)
- The dependent variable (DV)
- The proposed relationship between the IV and DV
Castillo M. The scientific method: a need for something better? . AJNR Am J Neuroradiol. 2013;34(9):1669-71. doi:10.3174/ajnr.A3401
Nevid J. Psychology: Concepts and Applications. Wadworth, 2013.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
User Preferences
Content preview.
Arcu felis bibendum ut tristique et egestas quis:
- Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris
- Duis aute irure dolor in reprehenderit in voluptate
- Excepteur sint occaecat cupidatat non proident
Keyboard Shortcuts
5.2 - writing hypotheses.
The first step in conducting a hypothesis test is to write the hypothesis statements that are going to be tested. For each test you will have a null hypothesis (\(H_0\)) and an alternative hypothesis (\(H_a\)).
When writing hypotheses there are three things that we need to know: (1) the parameter that we are testing (2) the direction of the test (non-directional, right-tailed or left-tailed), and (3) the value of the hypothesized parameter.
- At this point we can write hypotheses for a single mean (\(\mu\)), paired means(\(\mu_d\)), a single proportion (\(p\)), the difference between two independent means (\(\mu_1-\mu_2\)), the difference between two proportions (\(p_1-p_2\)), a simple linear regression slope (\(\beta\)), and a correlation (\(\rho\)).
- The research question will give us the information necessary to determine if the test is two-tailed (e.g., "different from," "not equal to"), right-tailed (e.g., "greater than," "more than"), or left-tailed (e.g., "less than," "fewer than").
- The research question will also give us the hypothesized parameter value. This is the number that goes in the hypothesis statements (i.e., \(\mu_0\) and \(p_0\)). For the difference between two groups, regression, and correlation, this value is typically 0.
Hypotheses are always written in terms of population parameters (e.g., \(p\) and \(\mu\)). The tables below display all of the possible hypotheses for the parameters that we have learned thus far. Note that the null hypothesis always includes the equality (i.e., =).
- Privacy Policy
Buy Me a Coffee
Home » What is a Hypothesis – Types, Examples and Writing Guide
What is a Hypothesis – Types, Examples and Writing Guide
Table of Contents

Definition:
Hypothesis is an educated guess or proposed explanation for a phenomenon, based on some initial observations or data. It is a tentative statement that can be tested and potentially proven or disproven through further investigation and experimentation.
Hypothesis is often used in scientific research to guide the design of experiments and the collection and analysis of data. It is an essential element of the scientific method, as it allows researchers to make predictions about the outcome of their experiments and to test those predictions to determine their accuracy.
Types of Hypothesis
Types of Hypothesis are as follows:
Research Hypothesis
A research hypothesis is a statement that predicts a relationship between variables. It is usually formulated as a specific statement that can be tested through research, and it is often used in scientific research to guide the design of experiments.
Null Hypothesis
The null hypothesis is a statement that assumes there is no significant difference or relationship between variables. It is often used as a starting point for testing the research hypothesis, and if the results of the study reject the null hypothesis, it suggests that there is a significant difference or relationship between variables.
Alternative Hypothesis
An alternative hypothesis is a statement that assumes there is a significant difference or relationship between variables. It is often used as an alternative to the null hypothesis and is tested against the null hypothesis to determine which statement is more accurate.
Directional Hypothesis
A directional hypothesis is a statement that predicts the direction of the relationship between variables. For example, a researcher might predict that increasing the amount of exercise will result in a decrease in body weight.
Non-directional Hypothesis
A non-directional hypothesis is a statement that predicts the relationship between variables but does not specify the direction. For example, a researcher might predict that there is a relationship between the amount of exercise and body weight, but they do not specify whether increasing or decreasing exercise will affect body weight.
Statistical Hypothesis
A statistical hypothesis is a statement that assumes a particular statistical model or distribution for the data. It is often used in statistical analysis to test the significance of a particular result.
Composite Hypothesis
A composite hypothesis is a statement that assumes more than one condition or outcome. It can be divided into several sub-hypotheses, each of which represents a different possible outcome.
Empirical Hypothesis
An empirical hypothesis is a statement that is based on observed phenomena or data. It is often used in scientific research to develop theories or models that explain the observed phenomena.
Simple Hypothesis
A simple hypothesis is a statement that assumes only one outcome or condition. It is often used in scientific research to test a single variable or factor.
Complex Hypothesis
A complex hypothesis is a statement that assumes multiple outcomes or conditions. It is often used in scientific research to test the effects of multiple variables or factors on a particular outcome.
Applications of Hypothesis
Hypotheses are used in various fields to guide research and make predictions about the outcomes of experiments or observations. Here are some examples of how hypotheses are applied in different fields:
- Science : In scientific research, hypotheses are used to test the validity of theories and models that explain natural phenomena. For example, a hypothesis might be formulated to test the effects of a particular variable on a natural system, such as the effects of climate change on an ecosystem.
- Medicine : In medical research, hypotheses are used to test the effectiveness of treatments and therapies for specific conditions. For example, a hypothesis might be formulated to test the effects of a new drug on a particular disease.
- Psychology : In psychology, hypotheses are used to test theories and models of human behavior and cognition. For example, a hypothesis might be formulated to test the effects of a particular stimulus on the brain or behavior.
- Sociology : In sociology, hypotheses are used to test theories and models of social phenomena, such as the effects of social structures or institutions on human behavior. For example, a hypothesis might be formulated to test the effects of income inequality on crime rates.
- Business : In business research, hypotheses are used to test the validity of theories and models that explain business phenomena, such as consumer behavior or market trends. For example, a hypothesis might be formulated to test the effects of a new marketing campaign on consumer buying behavior.
- Engineering : In engineering, hypotheses are used to test the effectiveness of new technologies or designs. For example, a hypothesis might be formulated to test the efficiency of a new solar panel design.
How to write a Hypothesis
Here are the steps to follow when writing a hypothesis:
Identify the Research Question
The first step is to identify the research question that you want to answer through your study. This question should be clear, specific, and focused. It should be something that can be investigated empirically and that has some relevance or significance in the field.
Conduct a Literature Review
Before writing your hypothesis, it’s essential to conduct a thorough literature review to understand what is already known about the topic. This will help you to identify the research gap and formulate a hypothesis that builds on existing knowledge.
Determine the Variables
The next step is to identify the variables involved in the research question. A variable is any characteristic or factor that can vary or change. There are two types of variables: independent and dependent. The independent variable is the one that is manipulated or changed by the researcher, while the dependent variable is the one that is measured or observed as a result of the independent variable.
Formulate the Hypothesis
Based on the research question and the variables involved, you can now formulate your hypothesis. A hypothesis should be a clear and concise statement that predicts the relationship between the variables. It should be testable through empirical research and based on existing theory or evidence.
Write the Null Hypothesis
The null hypothesis is the opposite of the alternative hypothesis, which is the hypothesis that you are testing. The null hypothesis states that there is no significant difference or relationship between the variables. It is important to write the null hypothesis because it allows you to compare your results with what would be expected by chance.
Refine the Hypothesis
After formulating the hypothesis, it’s important to refine it and make it more precise. This may involve clarifying the variables, specifying the direction of the relationship, or making the hypothesis more testable.
Examples of Hypothesis
Here are a few examples of hypotheses in different fields:
- Psychology : “Increased exposure to violent video games leads to increased aggressive behavior in adolescents.”
- Biology : “Higher levels of carbon dioxide in the atmosphere will lead to increased plant growth.”
- Sociology : “Individuals who grow up in households with higher socioeconomic status will have higher levels of education and income as adults.”
- Education : “Implementing a new teaching method will result in higher student achievement scores.”
- Marketing : “Customers who receive a personalized email will be more likely to make a purchase than those who receive a generic email.”
- Physics : “An increase in temperature will cause an increase in the volume of a gas, assuming all other variables remain constant.”
- Medicine : “Consuming a diet high in saturated fats will increase the risk of developing heart disease.”
Purpose of Hypothesis
The purpose of a hypothesis is to provide a testable explanation for an observed phenomenon or a prediction of a future outcome based on existing knowledge or theories. A hypothesis is an essential part of the scientific method and helps to guide the research process by providing a clear focus for investigation. It enables scientists to design experiments or studies to gather evidence and data that can support or refute the proposed explanation or prediction.
The formulation of a hypothesis is based on existing knowledge, observations, and theories, and it should be specific, testable, and falsifiable. A specific hypothesis helps to define the research question, which is important in the research process as it guides the selection of an appropriate research design and methodology. Testability of the hypothesis means that it can be proven or disproven through empirical data collection and analysis. Falsifiability means that the hypothesis should be formulated in such a way that it can be proven wrong if it is incorrect.
In addition to guiding the research process, the testing of hypotheses can lead to new discoveries and advancements in scientific knowledge. When a hypothesis is supported by the data, it can be used to develop new theories or models to explain the observed phenomenon. When a hypothesis is not supported by the data, it can help to refine existing theories or prompt the development of new hypotheses to explain the phenomenon.
When to use Hypothesis
Here are some common situations in which hypotheses are used:
- In scientific research , hypotheses are used to guide the design of experiments and to help researchers make predictions about the outcomes of those experiments.
- In social science research , hypotheses are used to test theories about human behavior, social relationships, and other phenomena.
- I n business , hypotheses can be used to guide decisions about marketing, product development, and other areas. For example, a hypothesis might be that a new product will sell well in a particular market, and this hypothesis can be tested through market research.
Characteristics of Hypothesis
Here are some common characteristics of a hypothesis:
- Testable : A hypothesis must be able to be tested through observation or experimentation. This means that it must be possible to collect data that will either support or refute the hypothesis.
- Falsifiable : A hypothesis must be able to be proven false if it is not supported by the data. If a hypothesis cannot be falsified, then it is not a scientific hypothesis.
- Clear and concise : A hypothesis should be stated in a clear and concise manner so that it can be easily understood and tested.
- Based on existing knowledge : A hypothesis should be based on existing knowledge and research in the field. It should not be based on personal beliefs or opinions.
- Specific : A hypothesis should be specific in terms of the variables being tested and the predicted outcome. This will help to ensure that the research is focused and well-designed.
- Tentative: A hypothesis is a tentative statement or assumption that requires further testing and evidence to be confirmed or refuted. It is not a final conclusion or assertion.
- Relevant : A hypothesis should be relevant to the research question or problem being studied. It should address a gap in knowledge or provide a new perspective on the issue.
Advantages of Hypothesis
Hypotheses have several advantages in scientific research and experimentation:
- Guides research: A hypothesis provides a clear and specific direction for research. It helps to focus the research question, select appropriate methods and variables, and interpret the results.
- Predictive powe r: A hypothesis makes predictions about the outcome of research, which can be tested through experimentation. This allows researchers to evaluate the validity of the hypothesis and make new discoveries.
- Facilitates communication: A hypothesis provides a common language and framework for scientists to communicate with one another about their research. This helps to facilitate the exchange of ideas and promotes collaboration.
- Efficient use of resources: A hypothesis helps researchers to use their time, resources, and funding efficiently by directing them towards specific research questions and methods that are most likely to yield results.
- Provides a basis for further research: A hypothesis that is supported by data provides a basis for further research and exploration. It can lead to new hypotheses, theories, and discoveries.
- Increases objectivity: A hypothesis can help to increase objectivity in research by providing a clear and specific framework for testing and interpreting results. This can reduce bias and increase the reliability of research findings.
Limitations of Hypothesis
Some Limitations of the Hypothesis are as follows:
- Limited to observable phenomena: Hypotheses are limited to observable phenomena and cannot account for unobservable or intangible factors. This means that some research questions may not be amenable to hypothesis testing.
- May be inaccurate or incomplete: Hypotheses are based on existing knowledge and research, which may be incomplete or inaccurate. This can lead to flawed hypotheses and erroneous conclusions.
- May be biased: Hypotheses may be biased by the researcher’s own beliefs, values, or assumptions. This can lead to selective interpretation of data and a lack of objectivity in research.
- Cannot prove causation: A hypothesis can only show a correlation between variables, but it cannot prove causation. This requires further experimentation and analysis.
- Limited to specific contexts: Hypotheses are limited to specific contexts and may not be generalizable to other situations or populations. This means that results may not be applicable in other contexts or may require further testing.
- May be affected by chance : Hypotheses may be affected by chance or random variation, which can obscure or distort the true relationship between variables.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Data Collection – Methods Types and Examples

Delimitations in Research – Types, Examples and...

Research Process – Steps, Examples and Tips

Research Design – Types, Methods and Examples

Institutional Review Board – Application Sample...

Evaluating Research – Process, Examples and...
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
- Choosing the Right Statistical Test | Types & Examples
Choosing the Right Statistical Test | Types & Examples
Published on January 28, 2020 by Rebecca Bevans . Revised on June 22, 2023.
Statistical tests are used in hypothesis testing . They can be used to:
- determine whether a predictor variable has a statistically significant relationship with an outcome variable.
- estimate the difference between two or more groups.
Statistical tests assume a null hypothesis of no relationship or no difference between groups. Then they determine whether the observed data fall outside of the range of values predicted by the null hypothesis.
If you already know what types of variables you’re dealing with, you can use the flowchart to choose the right statistical test for your data.
Statistical tests flowchart
Table of contents
What does a statistical test do, when to perform a statistical test, choosing a parametric test: regression, comparison, or correlation, choosing a nonparametric test, flowchart: choosing a statistical test, other interesting articles, frequently asked questions about statistical tests.
Statistical tests work by calculating a test statistic – a number that describes how much the relationship between variables in your test differs from the null hypothesis of no relationship.
It then calculates a p value (probability value). The p -value estimates how likely it is that you would see the difference described by the test statistic if the null hypothesis of no relationship were true.
If the value of the test statistic is more extreme than the statistic calculated from the null hypothesis, then you can infer a statistically significant relationship between the predictor and outcome variables.
If the value of the test statistic is less extreme than the one calculated from the null hypothesis, then you can infer no statistically significant relationship between the predictor and outcome variables.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
You can perform statistical tests on data that have been collected in a statistically valid manner – either through an experiment , or through observations made using probability sampling methods .
For a statistical test to be valid , your sample size needs to be large enough to approximate the true distribution of the population being studied.
To determine which statistical test to use, you need to know:
- whether your data meets certain assumptions.
- the types of variables that you’re dealing with.
Statistical assumptions
Statistical tests make some common assumptions about the data they are testing:
- Independence of observations (a.k.a. no autocorrelation): The observations/variables you include in your test are not related (for example, multiple measurements of a single test subject are not independent, while measurements of multiple different test subjects are independent).
- Homogeneity of variance : the variance within each group being compared is similar among all groups. If one group has much more variation than others, it will limit the test’s effectiveness.
- Normality of data : the data follows a normal distribution (a.k.a. a bell curve). This assumption applies only to quantitative data .
If your data do not meet the assumptions of normality or homogeneity of variance, you may be able to perform a nonparametric statistical test , which allows you to make comparisons without any assumptions about the data distribution.
If your data do not meet the assumption of independence of observations, you may be able to use a test that accounts for structure in your data (repeated-measures tests or tests that include blocking variables).
Types of variables
The types of variables you have usually determine what type of statistical test you can use.
Quantitative variables represent amounts of things (e.g. the number of trees in a forest). Types of quantitative variables include:
- Continuous (aka ratio variables): represent measures and can usually be divided into units smaller than one (e.g. 0.75 grams).
- Discrete (aka integer variables): represent counts and usually can’t be divided into units smaller than one (e.g. 1 tree).
Categorical variables represent groupings of things (e.g. the different tree species in a forest). Types of categorical variables include:
- Ordinal : represent data with an order (e.g. rankings).
- Nominal : represent group names (e.g. brands or species names).
- Binary : represent data with a yes/no or 1/0 outcome (e.g. win or lose).
Choose the test that fits the types of predictor and outcome variables you have collected (if you are doing an experiment , these are the independent and dependent variables ). Consult the tables below to see which test best matches your variables.
Parametric tests usually have stricter requirements than nonparametric tests, and are able to make stronger inferences from the data. They can only be conducted with data that adheres to the common assumptions of statistical tests.
The most common types of parametric test include regression tests, comparison tests, and correlation tests.
Regression tests
Regression tests look for cause-and-effect relationships . They can be used to estimate the effect of one or more continuous variables on another variable.
Comparison tests
Comparison tests look for differences among group means . They can be used to test the effect of a categorical variable on the mean value of some other characteristic.
T-tests are used when comparing the means of precisely two groups (e.g., the average heights of men and women). ANOVA and MANOVA tests are used when comparing the means of more than two groups (e.g., the average heights of children, teenagers, and adults).
Correlation tests
Correlation tests check whether variables are related without hypothesizing a cause-and-effect relationship.
These can be used to test whether two variables you want to use in (for example) a multiple regression test are autocorrelated.
Non-parametric tests don’t make as many assumptions about the data, and are useful when one or more of the common statistical assumptions are violated. However, the inferences they make aren’t as strong as with parametric tests.
This flowchart helps you choose among parametric tests. For nonparametric alternatives, check the table above.

If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Normal distribution
- Descriptive statistics
- Measures of central tendency
- Correlation coefficient
- Null hypothesis
Methodology
- Cluster sampling
- Stratified sampling
- Types of interviews
- Cohort study
- Thematic analysis
Research bias
- Implicit bias
- Cognitive bias
- Survivorship bias
- Availability heuristic
- Nonresponse bias
- Regression to the mean
Statistical tests commonly assume that:
- the data are normally distributed
- the groups that are being compared have similar variance
- the data are independent
If your data does not meet these assumptions you might still be able to use a nonparametric statistical test , which have fewer requirements but also make weaker inferences.
A test statistic is a number calculated by a statistical test . It describes how far your observed data is from the null hypothesis of no relationship between variables or no difference among sample groups.
The test statistic tells you how different two or more groups are from the overall population mean , or how different a linear slope is from the slope predicted by a null hypothesis . Different test statistics are used in different statistical tests.
Statistical significance is a term used by researchers to state that it is unlikely their observations could have occurred under the null hypothesis of a statistical test . Significance is usually denoted by a p -value , or probability value.
Statistical significance is arbitrary – it depends on the threshold, or alpha value, chosen by the researcher. The most common threshold is p < 0.05, which means that the data is likely to occur less than 5% of the time under the null hypothesis .
When the p -value falls below the chosen alpha value, then we say the result of the test is statistically significant.
Quantitative variables are any variables where the data represent amounts (e.g. height, weight, or age).
Categorical variables are any variables where the data represent groups. This includes rankings (e.g. finishing places in a race), classifications (e.g. brands of cereal), and binary outcomes (e.g. coin flips).
You need to know what type of variables you are working with to choose the right statistical test for your data and interpret your results .
Discrete and continuous variables are two types of quantitative variables :
- Discrete variables represent counts (e.g. the number of objects in a collection).
- Continuous variables represent measurable amounts (e.g. water volume or weight).
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 22). Choosing the Right Statistical Test | Types & Examples. Scribbr. Retrieved April 4, 2024, from https://www.scribbr.com/statistics/statistical-tests/
Is this article helpful?

Rebecca Bevans
Other students also liked, hypothesis testing | a step-by-step guide with easy examples, test statistics | definition, interpretation, and examples, normal distribution | examples, formulas, & uses, what is your plagiarism score.
Tutorial Playlist
Statistics tutorial, everything you need to know about the probability density function in statistics, the best guide to understand central limit theorem, an in-depth guide to measures of central tendency : mean, median and mode, the ultimate guide to understand conditional probability.
A Comprehensive Look at Percentile in Statistics
The Best Guide to Understand Bayes Theorem
Everything you need to know about the normal distribution, an in-depth explanation of cumulative distribution function, a complete guide to chi-square test, a complete guide on hypothesis testing in statistics, understanding the fundamentals of arithmetic and geometric progression, the definitive guide to understand spearman’s rank correlation, a comprehensive guide to understand mean squared error, all you need to know about the empirical rule in statistics, the complete guide to skewness and kurtosis, a holistic look at bernoulli distribution.
All You Need to Know About Bias in Statistics
A Complete Guide to Get a Grasp of Time Series Analysis
The Key Differences Between Z-Test Vs. T-Test
The Complete Guide to Understand Pearson's Correlation
A complete guide on the types of statistical studies, everything you need to know about poisson distribution, your best guide to understand correlation vs. regression, the most comprehensive guide for beginners on what is correlation, what is hypothesis testing in statistics types and examples.
Lesson 10 of 24 By Avijeet Biswal

Table of Contents
In today’s data-driven world , decisions are based on data all the time. Hypothesis plays a crucial role in that process, whether it may be making business decisions, in the health sector, academia, or in quality improvement. Without hypothesis & hypothesis tests, you risk drawing the wrong conclusions and making bad decisions. In this tutorial, you will look at Hypothesis Testing in Statistics.
What Is Hypothesis Testing in Statistics?
Hypothesis Testing is a type of statistical analysis in which you put your assumptions about a population parameter to the test. It is used to estimate the relationship between 2 statistical variables.
Let's discuss few examples of statistical hypothesis from real-life -
- A teacher assumes that 60% of his college's students come from lower-middle-class families.
- A doctor believes that 3D (Diet, Dose, and Discipline) is 90% effective for diabetic patients.
Now that you know about hypothesis testing, look at the two types of hypothesis testing in statistics.
Hypothesis Testing Formula
Z = ( x̅ – μ0 ) / (σ /√n)
- Here, x̅ is the sample mean,
- μ0 is the population mean,
- σ is the standard deviation,
- n is the sample size.
How Hypothesis Testing Works?
An analyst performs hypothesis testing on a statistical sample to present evidence of the plausibility of the null hypothesis. Measurements and analyses are conducted on a random sample of the population to test a theory. Analysts use a random population sample to test two hypotheses: the null and alternative hypotheses.
The null hypothesis is typically an equality hypothesis between population parameters; for example, a null hypothesis may claim that the population means return equals zero. The alternate hypothesis is essentially the inverse of the null hypothesis (e.g., the population means the return is not equal to zero). As a result, they are mutually exclusive, and only one can be correct. One of the two possibilities, however, will always be correct.
Your Dream Career is Just Around The Corner!
Null Hypothesis and Alternate Hypothesis
The Null Hypothesis is the assumption that the event will not occur. A null hypothesis has no bearing on the study's outcome unless it is rejected.
H0 is the symbol for it, and it is pronounced H-naught.
The Alternate Hypothesis is the logical opposite of the null hypothesis. The acceptance of the alternative hypothesis follows the rejection of the null hypothesis. H1 is the symbol for it.
Let's understand this with an example.
A sanitizer manufacturer claims that its product kills 95 percent of germs on average.
To put this company's claim to the test, create a null and alternate hypothesis.
H0 (Null Hypothesis): Average = 95%.
Alternative Hypothesis (H1): The average is less than 95%.
Another straightforward example to understand this concept is determining whether or not a coin is fair and balanced. The null hypothesis states that the probability of a show of heads is equal to the likelihood of a show of tails. In contrast, the alternate theory states that the probability of a show of heads and tails would be very different.
Become a Data Scientist with Hands-on Training!
Hypothesis Testing Calculation With Examples
Let's consider a hypothesis test for the average height of women in the United States. Suppose our null hypothesis is that the average height is 5'4". We gather a sample of 100 women and determine that their average height is 5'5". The standard deviation of population is 2.
To calculate the z-score, we would use the following formula:
z = ( x̅ – μ0 ) / (σ /√n)
z = (5'5" - 5'4") / (2" / √100)
z = 0.5 / (0.045)
We will reject the null hypothesis as the z-score of 11.11 is very large and conclude that there is evidence to suggest that the average height of women in the US is greater than 5'4".
Steps of Hypothesis Testing
Step 1: specify your null and alternate hypotheses.
It is critical to rephrase your original research hypothesis (the prediction that you wish to study) as a null (Ho) and alternative (Ha) hypothesis so that you can test it quantitatively. Your first hypothesis, which predicts a link between variables, is generally your alternate hypothesis. The null hypothesis predicts no link between the variables of interest.
Step 2: Gather Data
For a statistical test to be legitimate, sampling and data collection must be done in a way that is meant to test your hypothesis. You cannot draw statistical conclusions about the population you are interested in if your data is not representative.
Step 3: Conduct a Statistical Test
Other statistical tests are available, but they all compare within-group variance (how to spread out the data inside a category) against between-group variance (how different the categories are from one another). If the between-group variation is big enough that there is little or no overlap between groups, your statistical test will display a low p-value to represent this. This suggests that the disparities between these groups are unlikely to have occurred by accident. Alternatively, if there is a large within-group variance and a low between-group variance, your statistical test will show a high p-value. Any difference you find across groups is most likely attributable to chance. The variety of variables and the level of measurement of your obtained data will influence your statistical test selection.
Step 4: Determine Rejection Of Your Null Hypothesis
Your statistical test results must determine whether your null hypothesis should be rejected or not. In most circumstances, you will base your judgment on the p-value provided by the statistical test. In most circumstances, your preset level of significance for rejecting the null hypothesis will be 0.05 - that is, when there is less than a 5% likelihood that these data would be seen if the null hypothesis were true. In other circumstances, researchers use a lower level of significance, such as 0.01 (1%). This reduces the possibility of wrongly rejecting the null hypothesis.
Step 5: Present Your Results
The findings of hypothesis testing will be discussed in the results and discussion portions of your research paper, dissertation, or thesis. You should include a concise overview of the data and a summary of the findings of your statistical test in the results section. You can talk about whether your results confirmed your initial hypothesis or not in the conversation. Rejecting or failing to reject the null hypothesis is a formal term used in hypothesis testing. This is likely a must for your statistics assignments.
Types of Hypothesis Testing
To determine whether a discovery or relationship is statistically significant, hypothesis testing uses a z-test. It usually checks to see if two means are the same (the null hypothesis). Only when the population standard deviation is known and the sample size is 30 data points or more, can a z-test be applied.
A statistical test called a t-test is employed to compare the means of two groups. To determine whether two groups differ or if a procedure or treatment affects the population of interest, it is frequently used in hypothesis testing.
Chi-Square
You utilize a Chi-square test for hypothesis testing concerning whether your data is as predicted. To determine if the expected and observed results are well-fitted, the Chi-square test analyzes the differences between categorical variables from a random sample. The test's fundamental premise is that the observed values in your data should be compared to the predicted values that would be present if the null hypothesis were true.
Hypothesis Testing and Confidence Intervals
Both confidence intervals and hypothesis tests are inferential techniques that depend on approximating the sample distribution. Data from a sample is used to estimate a population parameter using confidence intervals. Data from a sample is used in hypothesis testing to examine a given hypothesis. We must have a postulated parameter to conduct hypothesis testing.
Bootstrap distributions and randomization distributions are created using comparable simulation techniques. The observed sample statistic is the focal point of a bootstrap distribution, whereas the null hypothesis value is the focal point of a randomization distribution.
A variety of feasible population parameter estimates are included in confidence ranges. In this lesson, we created just two-tailed confidence intervals. There is a direct connection between these two-tail confidence intervals and these two-tail hypothesis tests. The results of a two-tailed hypothesis test and two-tailed confidence intervals typically provide the same results. In other words, a hypothesis test at the 0.05 level will virtually always fail to reject the null hypothesis if the 95% confidence interval contains the predicted value. A hypothesis test at the 0.05 level will nearly certainly reject the null hypothesis if the 95% confidence interval does not include the hypothesized parameter.
Simple and Composite Hypothesis Testing
Depending on the population distribution, you can classify the statistical hypothesis into two types.
Simple Hypothesis: A simple hypothesis specifies an exact value for the parameter.
Composite Hypothesis: A composite hypothesis specifies a range of values.
A company is claiming that their average sales for this quarter are 1000 units. This is an example of a simple hypothesis.
Suppose the company claims that the sales are in the range of 900 to 1000 units. Then this is a case of a composite hypothesis.
One-Tailed and Two-Tailed Hypothesis Testing
The One-Tailed test, also called a directional test, considers a critical region of data that would result in the null hypothesis being rejected if the test sample falls into it, inevitably meaning the acceptance of the alternate hypothesis.
In a one-tailed test, the critical distribution area is one-sided, meaning the test sample is either greater or lesser than a specific value.
In two tails, the test sample is checked to be greater or less than a range of values in a Two-Tailed test, implying that the critical distribution area is two-sided.
If the sample falls within this range, the alternate hypothesis will be accepted, and the null hypothesis will be rejected.
Become a Data Scientist With Real-World Experience
Right Tailed Hypothesis Testing
If the larger than (>) sign appears in your hypothesis statement, you are using a right-tailed test, also known as an upper test. Or, to put it another way, the disparity is to the right. For instance, you can contrast the battery life before and after a change in production. Your hypothesis statements can be the following if you want to know if the battery life is longer than the original (let's say 90 hours):
- The null hypothesis is (H0 <= 90) or less change.
- A possibility is that battery life has risen (H1) > 90.
The crucial point in this situation is that the alternate hypothesis (H1), not the null hypothesis, decides whether you get a right-tailed test.
Left Tailed Hypothesis Testing
Alternative hypotheses that assert the true value of a parameter is lower than the null hypothesis are tested with a left-tailed test; they are indicated by the asterisk "<".
Suppose H0: mean = 50 and H1: mean not equal to 50
According to the H1, the mean can be greater than or less than 50. This is an example of a Two-tailed test.
In a similar manner, if H0: mean >=50, then H1: mean <50
Here the mean is less than 50. It is called a One-tailed test.
Type 1 and Type 2 Error
A hypothesis test can result in two types of errors.
Type 1 Error: A Type-I error occurs when sample results reject the null hypothesis despite being true.
Type 2 Error: A Type-II error occurs when the null hypothesis is not rejected when it is false, unlike a Type-I error.
Suppose a teacher evaluates the examination paper to decide whether a student passes or fails.
H0: Student has passed
H1: Student has failed
Type I error will be the teacher failing the student [rejects H0] although the student scored the passing marks [H0 was true].
Type II error will be the case where the teacher passes the student [do not reject H0] although the student did not score the passing marks [H1 is true].
Level of Significance
The alpha value is a criterion for determining whether a test statistic is statistically significant. In a statistical test, Alpha represents an acceptable probability of a Type I error. Because alpha is a probability, it can be anywhere between 0 and 1. In practice, the most commonly used alpha values are 0.01, 0.05, and 0.1, which represent a 1%, 5%, and 10% chance of a Type I error, respectively (i.e. rejecting the null hypothesis when it is in fact correct).
Future-Proof Your AI/ML Career: Top Dos and Don'ts
A p-value is a metric that expresses the likelihood that an observed difference could have occurred by chance. As the p-value decreases the statistical significance of the observed difference increases. If the p-value is too low, you reject the null hypothesis.
Here you have taken an example in which you are trying to test whether the new advertising campaign has increased the product's sales. The p-value is the likelihood that the null hypothesis, which states that there is no change in the sales due to the new advertising campaign, is true. If the p-value is .30, then there is a 30% chance that there is no increase or decrease in the product's sales. If the p-value is 0.03, then there is a 3% probability that there is no increase or decrease in the sales value due to the new advertising campaign. As you can see, the lower the p-value, the chances of the alternate hypothesis being true increases, which means that the new advertising campaign causes an increase or decrease in sales.
Why is Hypothesis Testing Important in Research Methodology?
Hypothesis testing is crucial in research methodology for several reasons:
- Provides evidence-based conclusions: It allows researchers to make objective conclusions based on empirical data, providing evidence to support or refute their research hypotheses.
- Supports decision-making: It helps make informed decisions, such as accepting or rejecting a new treatment, implementing policy changes, or adopting new practices.
- Adds rigor and validity: It adds scientific rigor to research using statistical methods to analyze data, ensuring that conclusions are based on sound statistical evidence.
- Contributes to the advancement of knowledge: By testing hypotheses, researchers contribute to the growth of knowledge in their respective fields by confirming existing theories or discovering new patterns and relationships.
Limitations of Hypothesis Testing
Hypothesis testing has some limitations that researchers should be aware of:
- It cannot prove or establish the truth: Hypothesis testing provides evidence to support or reject a hypothesis, but it cannot confirm the absolute truth of the research question.
- Results are sample-specific: Hypothesis testing is based on analyzing a sample from a population, and the conclusions drawn are specific to that particular sample.
- Possible errors: During hypothesis testing, there is a chance of committing type I error (rejecting a true null hypothesis) or type II error (failing to reject a false null hypothesis).
- Assumptions and requirements: Different tests have specific assumptions and requirements that must be met to accurately interpret results.
After reading this tutorial, you would have a much better understanding of hypothesis testing, one of the most important concepts in the field of Data Science . The majority of hypotheses are based on speculation about observed behavior, natural phenomena, or established theories.
If you are interested in statistics of data science and skills needed for such a career, you ought to explore Simplilearn’s Post Graduate Program in Data Science.
If you have any questions regarding this ‘Hypothesis Testing In Statistics’ tutorial, do share them in the comment section. Our subject matter expert will respond to your queries. Happy learning!
1. What is hypothesis testing in statistics with example?
Hypothesis testing is a statistical method used to determine if there is enough evidence in a sample data to draw conclusions about a population. It involves formulating two competing hypotheses, the null hypothesis (H0) and the alternative hypothesis (Ha), and then collecting data to assess the evidence. An example: testing if a new drug improves patient recovery (Ha) compared to the standard treatment (H0) based on collected patient data.
2. What is hypothesis testing and its types?
Hypothesis testing is a statistical method used to make inferences about a population based on sample data. It involves formulating two hypotheses: the null hypothesis (H0), which represents the default assumption, and the alternative hypothesis (Ha), which contradicts H0. The goal is to assess the evidence and determine whether there is enough statistical significance to reject the null hypothesis in favor of the alternative hypothesis.
Types of hypothesis testing:
- One-sample test: Used to compare a sample to a known value or a hypothesized value.
- Two-sample test: Compares two independent samples to assess if there is a significant difference between their means or distributions.
- Paired-sample test: Compares two related samples, such as pre-test and post-test data, to evaluate changes within the same subjects over time or under different conditions.
- Chi-square test: Used to analyze categorical data and determine if there is a significant association between variables.
- ANOVA (Analysis of Variance): Compares means across multiple groups to check if there is a significant difference between them.
3. What are the steps of hypothesis testing?
The steps of hypothesis testing are as follows:
- Formulate the hypotheses: State the null hypothesis (H0) and the alternative hypothesis (Ha) based on the research question.
- Set the significance level: Determine the acceptable level of error (alpha) for making a decision.
- Collect and analyze data: Gather and process the sample data.
- Compute test statistic: Calculate the appropriate statistical test to assess the evidence.
- Make a decision: Compare the test statistic with critical values or p-values and determine whether to reject H0 in favor of Ha or not.
- Draw conclusions: Interpret the results and communicate the findings in the context of the research question.
4. What are the 2 types of hypothesis testing?
- One-tailed (or one-sided) test: Tests for the significance of an effect in only one direction, either positive or negative.
- Two-tailed (or two-sided) test: Tests for the significance of an effect in both directions, allowing for the possibility of a positive or negative effect.
The choice between one-tailed and two-tailed tests depends on the specific research question and the directionality of the expected effect.
5. What are the 3 major types of hypothesis?
The three major types of hypotheses are:
- Null Hypothesis (H0): Represents the default assumption, stating that there is no significant effect or relationship in the data.
- Alternative Hypothesis (Ha): Contradicts the null hypothesis and proposes a specific effect or relationship that researchers want to investigate.
- Nondirectional Hypothesis: An alternative hypothesis that doesn't specify the direction of the effect, leaving it open for both positive and negative possibilities.
Find our Data Analyst Online Bootcamp in top cities:
About the author.
Avijeet is a Senior Research Analyst at Simplilearn. Passionate about Data Analytics, Machine Learning, and Deep Learning, Avijeet is also interested in politics, cricket, and football.
Recommended Resources
Free eBook: Top Programming Languages For A Data Scientist
Normality Test in Minitab: Minitab with Statistics
Machine Learning Career Guide: A Playbook to Becoming a Machine Learning Engineer
- PMP, PMI, PMBOK, CAPM, PgMP, PfMP, ACP, PBA, RMP, SP, and OPM3 are registered marks of the Project Management Institute, Inc.
9.1 Null and Alternative Hypotheses
The actual test begins by considering two hypotheses . They are called the null hypothesis and the alternative hypothesis . These hypotheses contain opposing viewpoints.
H 0 , the — null hypothesis: a statement of no difference between sample means or proportions or no difference between a sample mean or proportion and a population mean or proportion. In other words, the difference equals 0.
H a —, the alternative hypothesis: a claim about the population that is contradictory to H 0 and what we conclude when we reject H 0 .
Since the null and alternative hypotheses are contradictory, you must examine evidence to decide if you have enough evidence to reject the null hypothesis or not. The evidence is in the form of sample data.
After you have determined which hypothesis the sample supports, you make a decision. There are two options for a decision. They are reject H 0 if the sample information favors the alternative hypothesis or do not reject H 0 or decline to reject H 0 if the sample information is insufficient to reject the null hypothesis.
Mathematical Symbols Used in H 0 and H a :
H 0 always has a symbol with an equal in it. H a never has a symbol with an equal in it. The choice of symbol depends on the wording of the hypothesis test. However, be aware that many researchers use = in the null hypothesis, even with > or < as the symbol in the alternative hypothesis. This practice is acceptable because we only make the decision to reject or not reject the null hypothesis.
Example 9.1
H 0 : No more than 30 percent of the registered voters in Santa Clara County voted in the primary election. p ≤ 30 H a : More than 30 percent of the registered voters in Santa Clara County voted in the primary election. p > 30
A medical trial is conducted to test whether or not a new medicine reduces cholesterol by 25 percent. State the null and alternative hypotheses.
Example 9.2
We want to test whether the mean GPA of students in American colleges is different from 2.0 (out of 4.0). The null and alternative hypotheses are the following: H 0 : μ = 2.0 H a : μ ≠ 2.0
We want to test whether the mean height of eighth graders is 66 inches. State the null and alternative hypotheses. Fill in the correct symbol (=, ≠, ≥, <, ≤, >) for the null and alternative hypotheses.
- H 0 : μ __ 66
- H a : μ __ 66
Example 9.3
We want to test if college students take fewer than five years to graduate from college, on the average. The null and alternative hypotheses are the following: H 0 : μ ≥ 5 H a : μ < 5
We want to test if it takes fewer than 45 minutes to teach a lesson plan. State the null and alternative hypotheses. Fill in the correct symbol ( =, ≠, ≥, <, ≤, >) for the null and alternative hypotheses.
- H 0 : μ __ 45
- H a : μ __ 45
Example 9.4
An article on school standards stated that about half of all students in France, Germany, and Israel take advanced placement exams and a third of the students pass. The same article stated that 6.6 percent of U.S. students take advanced placement exams and 4.4 percent pass. Test if the percentage of U.S. students who take advanced placement exams is more than 6.6 percent. State the null and alternative hypotheses. H 0 : p ≤ 0.066 H a : p > 0.066
On a state driver’s test, about 40 percent pass the test on the first try. We want to test if more than 40 percent pass on the first try. Fill in the correct symbol (=, ≠, ≥, <, ≤, >) for the null and alternative hypotheses.
- H 0 : p __ 0.40
- H a : p __ 0.40
Collaborative Exercise
Bring to class a newspaper, some news magazines, and some internet articles. In groups, find articles from which your group can write null and alternative hypotheses. Discuss your hypotheses with the rest of the class.
As an Amazon Associate we earn from qualifying purchases.
This book may not be used in the training of large language models or otherwise be ingested into large language models or generative AI offerings without OpenStax's permission.
Want to cite, share, or modify this book? This book uses the Creative Commons Attribution License and you must attribute Texas Education Agency (TEA). The original material is available at: https://www.texasgateway.org/book/tea-statistics . Changes were made to the original material, including updates to art, structure, and other content updates.
Access for free at https://openstax.org/books/statistics/pages/1-introduction
- Authors: Barbara Illowsky, Susan Dean
- Publisher/website: OpenStax
- Book title: Statistics
- Publication date: Mar 27, 2020
- Location: Houston, Texas
- Book URL: https://openstax.org/books/statistics/pages/1-introduction
- Section URL: https://openstax.org/books/statistics/pages/9-1-null-and-alternative-hypotheses
© Jan 23, 2024 Texas Education Agency (TEA). The OpenStax name, OpenStax logo, OpenStax book covers, OpenStax CNX name, and OpenStax CNX logo are not subject to the Creative Commons license and may not be reproduced without the prior and express written consent of Rice University.
For enquiries call:
+1-469-442-0620

- Data Science
Hypothesis Testing in Data Science [Types, Process, Example]
Home Blog Data Science Hypothesis Testing in Data Science [Types, Process, Example]

In day-to-day life, we come across a lot of data lot of variety of content. Sometimes the information is too much that we get confused about whether the information provided is correct or not. At that moment, we get introduced to a word called “Hypothesis testing” which helps in determining the proofs and pieces of evidence for some belief or information.
What is Hypothesis Testing?
Hypothesis testing is an integral part of statistical inference. It is used to decide whether the given sample data from the population parameter satisfies the given hypothetical condition. So, it will predict and decide using several factors whether the predictions satisfy the conditions or not. In simpler terms, trying to prove whether the facts or statements are true or not.
For example, if you predict that students who sit on the last bench are poorer and weaker than students sitting on 1st bench, then this is a hypothetical statement that needs to be clarified using different experiments. Another example we can see is implementing new business strategies to evaluate whether they will work for the business or not. All these things are very necessary when you work with data as a data scientist. If you are interested in learning about data science, visit this amazing Data Science full course to learn data science.
How is Hypothesis Testing Used in Data Science?
It is important to know how and where we can use hypothesis testing techniques in the field of data science. Data scientists predict a lot of things in their day-to-day work, and to check the probability of whether that finding is certain or not, we use hypothesis testing. The main goal of hypothesis testing is to gauge how well the predictions perform based on the sample data provided by the population. If you are interested to know more about the applications of the data, then refer to this D ata Scien ce course in India which will give you more insights into application-based things. When data scientists work on model building using various machine learning algorithms, they need to have faith in their models and the forecasting of models. They then provide the sample data to the model for training purposes so that it can provide us with the significance of statistical data that will represent the entire population.
Where and When to Use Hypothesis Test?
Hypothesis testing is widely used when we need to compare our results based on predictions. So, it will compare before and after results. For example, someone claimed that students writing exams from blue pen always get above 90%; now this statement proves it correct, and experiments need to be done. So, the data will be collected based on the student's input, and then the test will be done on the final result later after various experiments and observations on students' marks vs pen used, final conclusions will be made which will determine the results. Now hypothesis testing will be done to compare the 1st and the 2nd result, to see the difference and closeness of both outputs. This is how hypothesis testing is done.
How Does Hypothesis Testing Work in Data Science?
In the whole data science life cycle, hypothesis testing is done in various stages, starting from the initial part, the 1st stage where the EDA, data pre-processing, and manipulation are done. In this stage, we will do our initial hypothesis testing to visualize the outcome in later stages. The next test will be done after we have built our model, once the model is ready and hypothesis testing is done, we will compare the results of the initial testing and the 2nd one to compare the results and significance of the results and to confirm the insights generated from the 1st cycle match with the 2nd one or not. This will help us know how the model responds to the sample training data. As we saw above, hypothesis testing is always needed when we are planning to contrast more than 2 groups. While checking on the results, it is important to check on the flexibility of the results for the sample and the population. Later, we can judge on the disagreement of the results are appropriate or vague. This is all we can do using hypothesis testing.
Different Types of Hypothesis Testing
Hypothesis testing can be seen in several types. In total, we have 5 types of hypothesis testing. They are described below:

1. Alternative Hypothesis
The alternative hypothesis explains and defines the relationship between two variables. It simply indicates a positive relationship between two variables which means they do have a statistical bond. It indicates that the sample observed is going to influence or affect the outcome. An alternative hypothesis is described using H a or H 1 . Ha indicates an alternative hypothesis and H 1 explains the possibility of influenced outcome which is 1. For example, children who study from the beginning of the class have fewer chances to fail. An alternate hypothesis will be accepted once the statistical predictions become significant. The alternative hypothesis can be further divided into 3 parts.
- Left-tailed: Left tailed hypothesis can be expected when the sample value is less than the true value.
- Right-tailed: Right-tailed hypothesis can be expected when the true value is greater than the outcome/predicted value.
- Two-tailed: Two-tailed hypothesis is defined when the true value is not equal to the sample value or the output.
2. Null Hypothesis
The null hypothesis simply states that there is no relation between statistical variables. If the facts presented at the start do not match with the outcomes, then we can say, the testing is null hypothesis testing. The null hypothesis is represented as H 0 . For example, children who study from the beginning of the class have no fewer chances to fail. There are types of Null Hypothesis described below:
Simple Hypothesis: It helps in denoting and indicating the distribution of the population.
Composite Hypothesis: It does not denote the population distribution
Exact Hypothesis: In the exact hypothesis, the value of the hypothesis is the same as the sample distribution. Example- μ= 10
Inexact Hypothesis: Here, the hypothesis values are not equal to the sample. It will denote a particular range of values.
3. Non-directional Hypothesis
The non-directional hypothesis is a tow-tailed hypothesis that indicates the true value does not equal the predicted value. In simpler terms, there is no direction between the 2 variables. For an example of a non-directional hypothesis, girls and boys have different methodologies to solve a problem. Here the example explains that the thinking methodologies of a girl and a boy is different, they don’t think alike.
4. Directional Hypothesis
In the Directional hypothesis, there is a direct relationship between two variables. Here any of the variables influence the other.
5. Statistical Hypothesis
Statistical hypothesis helps in understanding the nature and character of the population. It is a great method to decide whether the values and the data we have with us satisfy the given hypothesis or not. It helps us in making different probabilistic and certain statements to predict the outcome of the population... We have several types of tests which are the T-test, Z-test, and Anova tests.
Methods of Hypothesis Testing
1. frequentist hypothesis testing.
Frequentist hypotheses mostly work with the approach of making predictions and assumptions based on the current data which is real-time data. All the facts are based on current data. The most famous kind of frequentist approach is null hypothesis testing.
2. Bayesian Hypothesis Testing
Bayesian testing is a modern and latest way of hypothesis testing. It is known to be the test that works with past data to predict the future possibilities of the hypothesis. In Bayesian, it refers to the prior distribution or prior probability samples for the observed data. In the medical Industry, we observe that Doctors deal with patients’ diseases using past historical records. So, with this kind of record, it is helpful for them to understand and predict the current and upcoming health conditions of the patient.
Importance of Hypothesis Testing in Data Science
Most of the time, people assume that data science is all about applying machine learning algorithms and getting results, that is true but in addition to the fact that to work in the data science field, one needs to be well versed with statistics as most of the background work in Data science is done through statistics. When we deal with data for pre-processing, manipulating, and analyzing, statistics play. Specifically speaking Hypothesis testing helps in making confident decisions, predicting the correct outcomes, and finding insightful conclusions regarding the population. Hypothesis testing helps us resolve tough things easily. To get more familiar with Hypothesis testing and other prediction models attend the superb useful KnowledgeHut Data Science full course which will give you more domain knowledge and will assist you in working with industry-related projects.
Basic Steps in Hypothesis Testing [Workflow]
1. null and alternative hypothesis.
After we have done our initial research about the predictions that we want to find out if true, it is important to mention whether the hypothesis done is a null hypothesis(H0) or an alternative hypothesis (Ha). Once we understand the type of hypothesis, it will be easy for us to do mathematical research on it. A null hypothesis will usually indicate the no-relationship between the variables whereas an alternative hypothesis describes the relationship between 2 variables.
- H0 – Girls, on average, are not strong as boys
- Ha - Girls, on average are stronger than boys
2. Data Collection
To prove our statistical test validity, it is essential and critical to check the data and proceed with sampling them to get the correct hypothesis results. If the target data is not prepared and ready, it will become difficult to make the predictions or the statistical inference on the population that we are planning to make. It is important to prepare efficient data, so that hypothesis findings can be easy to predict.
3. Selection of an appropriate test statistic
To perform various analyses on the data, we need to choose a statistical test. There are various types of statistical tests available. Based on the wide spread of the data that is variance within the group or how different the data category is from one another that is variance without a group, we can proceed with our further research study.
4. Selection of the appropriate significant level
Once we get the result and outcome of the statistical test, we have to then proceed further to decide whether the reject or accept the null hypothesis. The significance level is indicated by alpha (α). It describes the probability of rejecting or accepting the null hypothesis. Example- Suppose the value of the significance level which is alpha is 0.05. Now, this value indicates the difference from the null hypothesis.
5. Calculation of the test statistics and the p-value
P value is simply the probability value and expected determined outcome which is at least as extreme and close as observed results of a hypothetical test. It helps in evaluating and verifying hypotheses against the sample data. This happens while assuming the null hypothesis is true. The lower the value of P, the higher and better will be the results of the significant value which is alpha (α). For example, if the P-value is 0.05 or even less than this, then it will be considered statistically significant. The main thing is these values are predicted based on the calculations done by deviating the values between the observed one and referenced one. The greater the difference between values, the lower the p-value will be.
6. Findings of the test
After knowing the P-value and statistical significance, we can determine our results and take the appropriate decision of whether to accept or reject the null hypothesis based on the facts and statistics presented to us.
How to Calculate Hypothesis Testing?
Hypothesis testing can be done using various statistical tests. One is Z-test. The formula for Z-test is given below:
Z = ( x̅ – μ 0 ) / (σ /√n)
In the above equation, x̅ is the sample mean
- μ0 is the population mean
- σ is the standard deviation
- n is the sample size
Now depending on the Z-test result, the examination will be processed further. The result is either going to be a null hypothesis or it is going to be an alternative hypothesis. That can be measured through below formula-
- H0: μ=μ0
- Ha: μ≠μ0
- Here,
- H0 = null hypothesis
- Ha = alternate hypothesis
In this way, we calculate the hypothesis testing and can apply it to real-world scenarios.
Real-World Examples of Hypothesis Testing
Hypothesis testing has a wide variety of use cases that proves to be beneficial for various industries.
1. Healthcare
In the healthcare industry, all the research and experiments which are done to predict the success of any medicine or drug are done successfully with the help of Hypothesis testing.
2. Education sector
Hypothesis testing assists in experimenting with different teaching techniques to deal with the understanding capability of different students.
3. Mental Health
Hypothesis testing helps in indicating the factors that may cause some serious mental health issues.
4. Manufacturing
Testing whether the new change in the process of manufacturing helped in the improvement of the process as well as in the quantity or not. In the same way, there are many other use cases that we get to see in different sectors for hypothesis testing.
Error Terms in Hypothesis Testing
1. type-i error.
Type I error occurs during the process of hypothesis testing when the null hypothesis is rejected even though it is accurate. This kind of error is also known as False positive because even though the statement is positive or correct but results are given as false. For example, an innocent person still goes to jail because he is considered to be guilty.
2. Type-II error
Type II error occurs during the process of hypothesis testing when the null hypothesis is not rejected even though it is inaccurate. This Kind of error is also called a False-negative which means even though the statements are false and inaccurate, it still says it is correct and doesn’t reject it. For example, a person is guilty, but in court, he has been proven innocent where he is guilty, so this is a Type II error.
3. Level of Significance
The level of significance is majorly used to measure the confidence with which a null hypothesis can be rejected. It is the value with which one can reject the null hypothesis which is H0. The level of significance gauges whether the hypothesis testing is significant or not.
P-value stands for probability value, which tells us the probability or likelihood to find the set of observations when the null hypothesis is true using statistical tests. The main purpose is to check the significance of the statistical statement.
5. High P-Values
A higher P-value indicates that the testing is not statistically significant. For example, a P value greater than 0.05 is considered to be having higher P value. A higher P-value also means that our evidence and proofs are not strong enough to influence the population.
In hypothesis testing, each step is responsible for getting the outcomes and the results, whether it is the selection of statistical tests or working on data, each step contributes towards the better consequences of the hypothesis testing. It is always a recommendable step when planning for predicting the outcomes and trying to experiment with the sample; hypothesis testing is a useful concept to apply.
Frequently Asked Questions (FAQs)
We can test a hypothesis by selecting a correct hypothetical test and, based on those getting results.
Many statistical tests are used for hypothetical testing which includes Z-test, T-test, etc.
Hypothesis helps us in doing various experiments and working on a specific research topic to predict the results.
The null and alternative hypothesis, data collection, selecting a statistical test, selecting significance value, calculating p-value, check your findings.
In simple words, parametric tests are purely based on assumptions whereas non-parametric tests are based on data that is collected and acquired from a sample.

Gauri Guglani
Gauri Guglani works as a Data Analyst at Deloitte Consulting. She has done her major in Information Technology and holds great interest in the field of data science. She owns her technical skills as well as managerial skills and also is great at communicating. Since her undergraduate, Gauri has developed a profound interest in writing content and sharing her knowledge through the manual means of blog/article writing. She loves writing on topics affiliated with Statistics, Python Libraries, Machine Learning, Natural Language processes, and many more.
Avail your free 1:1 mentorship session.
Something went wrong
Upcoming Data Science Batches & Dates
Teach yourself statistics
How to Analyze Survey Data for Hypothesis Tests
Traditionally, researchers analyze survey data to estimate population parameters. But very similar analytical techniques can also be applied to test hypotheses.
In this lesson, we describe how to analyze survey data to test statistical hypotheses.
The Logic of the Analysis
In a big-picture sense, the analysis of survey sampling data is easy. When you use sample data to test a hypothesis, the analysis includes the same seven steps:
- Estimate a population parameter.
- Estimate population variance.
- Compute standard error.
- Set the significance level.
- Find the critical value (often a z-score or a t-score).
- Define the upper limit of the region of acceptance.
- Define the lower limit of the region of acceptance.
It doesn't matter whether the sampling method is simple random sampling, stratified sampling, or cluster sampling. And it doesn't matter whether the parameter of interest is a mean score, a proportion, or a total score. The analysis of survey sampling data always includes the same seven steps.
However, formulas used in the first three steps of the analysis can differ, based on the sampling method and the parameter of interest. In the next section, we'll list the formulas to use for each step. By the end of the lesson, you'll know how to test hypotheses about mean scores, proportions, and total scores using data from simple random samples, stratified samples, and cluster samples.
Data Analysis for Hypothesis Testing
Now, let's look in a little more detail at the seven steps required to conduct a hypothesis test, when you are working with data from a survey sample.
Sample mean = x = Σx / n
where x is a sample estimate of the population mean, Σx is the sum of all the sample observations, and n is the number of sample observations.
Population total = t = N * x
where N is the number of observations in the population, and x is the sample mean.
Or, if we know the sample proportion, we can estimate the population total (t) as:
Population total = t = N * p
where t is an estimate of the number of elements in the population that have a specified attribute, N is the number of observations in the population, and p is the sample proportion.
Sample mean = x = Σ( N h / N ) * x h
where N h is the number of observations in stratum h of the population, N is the number of observations in the population, and x h is the mean score from the sample in stratum h .
Sample proportion = p = Σ( N h / N ) * p h
where N h is the number of observations in stratum h of the population, N is the number of observations in the population, and p h is the sample proportion in stratum h .
Population total = t = ΣN h * x h
where N h is the number of observations in the population from stratum h , and x h is the sample mean from stratum h .
Or if we know the population proportion in each stratum, we can use this formula to estimate a population total:
Population total = t = ΣN h * p h
where t is an estimate of the number of observations in the population that have a specified attribute, N h is the number of observations from stratum h in the population, and p h is the sample proportion from stratum h .
x = ( N / ( n * M ) ] * Σ ( M h * x h )
where N is the number of clusters in the population, n is the number of clusters in the sample, M is the number of observations in the population, M h is the number of observations in cluster h , and x h is the mean score from the sample in cluster h .
p = ( N / ( n * M ) ] * Σ ( M h * p h )
where N is the number of clusters in the population, n is the number of clusters in the sample, M is the number of observations in the population, M h is the number of observations in cluster h , and p h is the proportion from the sample in cluster h .
Population total = t = N/n * ΣM h * x h
where N is the number of clusters in the population, n is the number of clusters in the sample, M h is the number of observations in the population from cluster h , and x h is the sample mean from cluster h .
And, if we know the sample proportion for each cluster, we can estimate a population total:
Population total = t = N/n * ΣM h * p h
where t is an estimate of the number of elements in the population that have a specified attribute, N is the number of clusters in the population, n is the number of clusters in the sample, M h is the number of observations from cluster h in the population, and p h is the sample proportion from cluster h .
s 2 = P * (1 - P)
where s 2 is an estimate of population variance, and P is the value of the proportion in the null hypothesis.
s 2 = Σ ( x i - x ) 2 / ( n - 1 )
where s 2 is a sample estimate of population variance, x is the sample mean, x i is the i th element from the sample, and n is the number of elements in the sample.
s 2 h = Σ ( x i h - x h ) 2 / ( n h - 1 )
where s 2 h is a sample estimate of population variance in stratum h , x i h is the value of the i th element from stratum h, x h is the sample mean from stratum h , and n h is the number of sample observations from stratum h .
s 2 h = Σ ( x i h - x h ) 2 / ( m h - 1 )
where s 2 h is a sample estimate of population variance in cluster h , x i h is the value of the i th element from cluster h, x h is the sample mean from cluster h , and m h is the number of observations sampled from cluster h .
s 2 b = Σ ( t h - t/N ) 2 / ( n - 1 )
where s 2 b is a sample estimate of the variance between sampled clusters, t h is the total from cluster h, t is the sample estimate of the population total, N is the number of clusters in the population, and n is the number of clusters in the sample.
You can estimate the population total (t) from the following formula:
where M h is the number of observations in the population from cluster h , and x h is the sample mean from cluster h .
SE = sqrt [ (1 - n/N) * s 2 / n ]
where n is the sample size, N is the population size, and s is a sample estimate of the population standard deviation.
SE = sqrt [ N 2 * (1 - n/N) * s 2 / n ]
where N is the population size, n is the sample size, and s 2 is a sample estimate of the population variance.
SE = (1 / N) * sqrt { Σ [ N 2 h * ( 1 - n h /N h ) * s 2 h / n h ] }
where n h is the number of sample observations from stratum h, N h is the number of elements from stratum h in the population, N is the number of elements in the population, and s 2 h is a sample estimate of the population variance in stratum h.
SE = sqrt { Σ [ N 2 h * ( 1 - n h /N h ) * s 2 h / n h ] }
where N h is the number of elements from stratum h in the population, n h is the number of sample observations from stratum h, and s 2 h is a sample estimate of the population variance in stratum h.
where M is the number of observations in the population, N is the number of clusters in the population, n is the number of clusters in the sample, M h is the number of elements from cluster h in the population, m h is the number of elements from cluster h in the sample, x h is the sample mean from cluster h, s 2 h is a sample estimate of the population variance in stratum h, and t is a sample estimate of the population total. For the equation above, use the following formula to estimate the population total.
t = N/n * Σ M h x h
With one-stage cluster sampling, the formula for the standard error reduces to:
where M is the number of observations in the population, N is the number of clusters in the population, n is the number of clusters in the sample, M h is the number of elements from cluster h in the population, m h is the number of elements from cluster h in the sample, p h is the value of the proportion from cluster h, and t is a sample estimate of the population total. For the equation above, use the following formula to estimate the population total.
t = N/n * Σ M h p h
where N is the number of clusters in the population, n is the number of clusters in the sample, s 2 b is a sample estimate of the variance between clusters, m h is the number of elements from cluster h in the sample, M h is the number of elements from cluster h in the population, and s 2 h is a sample estimate of the population variance in cluster h.
SE = N * sqrt { [ ( 1 - n/N ) / n ] * s 2 b /n }
- Choose a significance level. The significance level (denoted by α) is the probability of committing a Type I error . Researchers often set the significance level equal to 0.05 or 0.01.
When the null hypothesis is two-tailed, the critical value is the z-score or t-score that has a cumulative probability equal to 1 - α/2. When the null hypothesis is one-tailed, the critical value has a cumulative probability equal to 1 - α.
Researchers use a t-score when sample size is small; a z-score when it is large (at least 30). You can use the Normal Distribution Calculator to find the critical z-score, and the t Distribution Calculator to find the critical t-score.
If you use a t-score, you will have to find the degrees of freedom (df). With simple random samples, df is often equal to the sample size minus one.
Note: The critical value for a one-tailed hypothesis does not equal the critical value for a two-tailed hypothesis. The critical value for a one-tailed hypothesis is smaller.
UL = M + SE * CV
- If the null hypothesis is μ > M: The theoretical upper limit of the region of acceptance is plus infinity, unless the parameter in the null hypothesis is a proportion or a percentage. The upper limit is 1 for a proportion, and 100 for a percentage.
LL = M - SE * CV
- If the null hypothesis is μ < M: The theoretical lower limit of the region of acceptance is minus infinity, unless the test statistic is a proportion or a percentage. The lower limit for a proportion or a percentage is zero.
The region of acceptance is the range of values between LL and UL. If the sample estimate of the population parameter falls outside the region of acceptance, the researcher rejects the null hypothesis. If the sample estimate falls within the region of acceptance, the researcher does not reject the null hypothesis.
By following the steps outlined above, you define the region of acceptance in such a way that the chance of making a Type I error is equal to the significance level .
Test Your Understanding
In this section, two hypothesis testing examples illustrate how to define the region of acceptance. The first problem shows a two-tailed test with a mean score; and the second problem, a one-tailed test with a proportion.
Sample Size Calculator
As you probably noticed, defining the region of acceptance can be complex and time-consuming. Stat Trek's Sample Size Calculator can do the same job quickly, easily, and error-free.The calculator is easy to use, and it is free. You can find the Sample Size Calculator in Stat Trek's main menu under the Stat Tools tab. Or you can tap the button below.
An inventor has developed a new, energy-efficient lawn mower engine. He claims that the engine will run continuously for 5 hours (300 minutes) on a single ounce of regular gasoline. Suppose a random sample of 50 engines is tested. The engines run for an average of 295 minutes, with a standard deviation of 20 minutes.
Consider the null hypothesis that the mean run time is 300 minutes against the alternative hypothesis that the mean run time is not 300 minutes. Use a 0.05 level of significance. Find the region of acceptance. Based on the region of acceptance, would you reject the null hypothesis?
Solution: The analysis of survey data to test a hypothesis takes seven steps. We work through those steps below:
However, if we had to compute the sample mean from raw data, we could do it, using the following formula:
where Σx is the sum of all the sample observations, and n is the number of sample observations.
If we hadn't been given the standard deviation, we could have computed it from the raw sample data, using the following formula:
For this problem, we know that the sample size is 50, and the standard deviation is 20. The population size is not stated explicitly; but, in theory, the manufacturer could produce an infinite number of motors. Therefore, the population size is a very large number. For the purpose of the analysis, we'll assume that the population size is 100,000. Plugging those values into the formula, we find that the standard error is:
SE = sqrt [ (1 - 50/100,000) * 20 2 / 50 ]
SE = sqrt(0.9995 * 8) = 2.828
- Choose a significance level. The significance level (α) is chosen for us in the problem. It is 0.05. (Researchers often set the significance level equal to 0.05 or 0.01.)
When the null hypothesis is two-tailed, the critical value has a cumulative probability equal to 1 - α/2. When the null hypothesis is one-tailed, the critical value has a cumulative probability equal to 1 - α.
For this problem, the null hypothesis and the alternative hypothesis can be expressed as:
Since this problem deals with a two-tailed hypothesis, the critical value will be the z-score that has a cumulative probability equal to 1 - α/2. Here, the significance level (α) is 0.05, so the critical value will be the z-score that has a cumulative probability equal to 0.975.
We use the Normal Distribution Calculator to find that the z-score with a cumulative probability of 0.975 is 1.96. Thus, the critical value is 1.96.
where M is the parameter value in the null hypothesis, SE is the standard error, and CV is the critical value. So, for this problem, we compute the lower limit of the region of acceptance as:
LL = 300 - 2.828 * 1.96
LL = 300 - 5.54
LL = 294.46
LL = 300 + 2.828 * 1.96
LL = 300 + 5.54
LL = 305.54
Thus, given a significance level of 0.05, the region of acceptance is range of values between 294.46 and 305.54. In the tests, the engines ran for an average of 295 minutes. That value is within the region of acceptance, so the inventor cannot reject the null hypothesis that the engines run for 300 minutes on an ounce of fuel.
Problem 2 Suppose the CEO of a large software company claims that at least 80 percent of the company's 1,000,000 customers are very satisfied. A survey of 100 randomly sampled customers finds that 73 percent are very satisfied. To test the CEO's hypothesis, find the region of acceptance. Assume a significance level of 0.05.
However, if we had to compute the sample proportion (p) from raw data, we could do it by using the following formula:
where s 2 is the population variance when the true population proportion is P, and P is the value of the proportion in the null hypothesis.
For the purpose of estimating population variance, we assume the null hypothesis is true. In this problem, the null hypothesis states that the true proportion of satisfied customers is 0.8. Therefore, to estimate population variance, we insert that value in the formula:
s 2 = 0.8 * (1 - 0.8)
s 2 = 0.8 * 0.2 = 0.16
For this problem, we know that the sample size is 100, the variance ( s 2 ) is 0.16, and the population size is 1,000,000. Plugging those values into the formula, we find that the standard error is:
SE = sqrt [ (1 - 100/1,000,000) * 0.16 / 100 ]
SE = sqrt(0.9999 * 0.0016) = 0.04
Since this problem deals with a one-tailed hypothesis, the critical value will be the z-score that has a cumulative probability equal to 1 - α. Here, the significance level (α) is 0.05, so the critical value will be the z-score that has a cumulative probability equal to 0.95.
We use the Normal Distribution Calculator to find that the z-score with a cumulative probability of 0.95 is 1.645. Thus, the critical value is 1.645.
LL = 0.8 - 0.04 * 1.645
LL = 0.8 - 0.0658 = 0.7342
- Find the upper limit of the region of acceptance. For this type of one-tailed hypothesis, the theoretical upper limit of the region of acceptance is 1; since any proportion greater than 0.8 is consistent with the null hypothesis, and 1 is the largest value that a proportion can have.
Thus, given a significance level of 0.05, the region of acceptance is the range of values between 0.7342 and 1.0. In the sample survey, the proportion of satisfied customers was 0.73. That value is outside the region of acceptance, so null hypothesis must be rejected.

Statistics Made Easy
The Complete Guide: Hypothesis Testing in Excel
In statistics, a hypothesis test is used to test some assumption about a population parameter .
There are many different types of hypothesis tests you can perform depending on the type of data you’re working with and the goal of your analysis.
This tutorial explains how to perform the following types of hypothesis tests in Excel:
- One sample t-test
- Two sample t-test
- Paired samples t-test
- One proportion z-test
- Two proportion z-test
Let’s jump in!
Example 1: One Sample t-test in Excel
A one sample t-test is used to test whether or not the mean of a population is equal to some value.
For example, suppose a botanist wants to know if the mean height of a certain species of plant is equal to 15 inches.
To test this, she collects a random sample of 12 plants and records each of their heights in inches.
She would write the hypotheses for this particular one sample t-test as follows:
- H 0 : µ = 15
- H A : µ ≠15
Refer to this tutorial for a step-by-step explanation of how to perform this hypothesis test in Excel.
Example 2: Two Sample t-test in Excel
A two sample t-test is used to test whether or not the means of two populations are equal.
For example, suppose researchers want to know whether or not two different species of plants have the same mean height.
To test this, they collect a random sample of 20 plants from each species and measure their heights.
The researchers would write the hypotheses for this particular two sample t-test as follows:
- H 0 : µ 1 = µ 2
- H A : µ 1 ≠ µ 2
Example 3: Paired Samples t-test in Excel
A paired samples t-test is used to compare the means of two samples when each observation in one sample can be paired with an observation in the other sample.
For example, suppose we want to know whether a certain study program significantly impacts student performance on a particular exam.
To test this, we have 20 students in a class take a pre-test. Then, we have each of the students participate in the study program for two weeks. Then, the students retake a post-test of similar difficulty.
We would write the hypotheses for this particular two sample t-test as follows:
- H 0 : µ pre = µ post
- H A : µ pre ≠ µ post
Example 4: One Proportion z-test in Excel
A one proportion z-test is used to compare an observed proportion to a theoretical one.
For example, suppose a phone company claims that 90% of its customers are satisfied with their service.
To test this claim, an independent researcher gathered a simple random sample of 200 customers and asked them if they are satisfied with their service.
- H 0 : p = 0.90
- H A : p ≠ 0.90
Example 5: Two Proportion z-test in Excel
A two proportion z-test is used to test for a difference between two population proportions.
For example, suppose a s uperintendent of a school district claims that the percentage of students who prefer chocolate milk over regular milk in school cafeterias is the same for school 1 and school 2.
To test this claim, an independent researcher obtains a simple random sample of 100 students from each school and surveys them about their preferences.
- H 0 : p 1 = p 2
- H A : p 1 ≠ p 2

Published by Zach
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
- Machine Learning Tutorial
- Data Analysis Tutorial
- Python - Data visualization tutorial
- Machine Learning Projects
- Machine Learning Interview Questions
- Machine Learning Mathematics
- Deep Learning Tutorial
- Deep Learning Project
- Deep Learning Interview Questions
- Computer Vision Tutorial
- Computer Vision Projects
- NLP Project
- NLP Interview Questions
- Statistics with Python
- 100 Days of Machine Learning
- Data Analysis with Python
Introduction to Data Analysis
- What is Data Analysis?
- Data Analytics and its type
- How to Install Numpy on Windows?
- How to Install Pandas in Python?
- How to Install Matplotlib on python?
- How to Install Python Tensorflow in Windows?
Data Analysis Libraries
- Pandas Tutorial
- NumPy Tutorial - Python Library
- Data Analysis with SciPy
- Introduction to TensorFlow
Data Visulization Libraries
- Matplotlib Tutorial
- Python Seaborn Tutorial
- Plotly tutorial
- Introduction to Bokeh in Python
Exploratory Data Analysis (EDA)
- Univariate, Bivariate and Multivariate data and its analysis
- Measures of Central Tendency in Statistics
- Measures of spread - Range, Variance, and Standard Deviation
- Interquartile Range and Quartile Deviation using NumPy and SciPy
- Anova Formula
- Skewness of Statistical Data
- How to Calculate Skewness and Kurtosis in Python?
- Difference Between Skewness and Kurtosis
- Histogram | Meaning, Example, Types and Steps to Draw
- Interpretations of Histogram
- Quantile Quantile plots
- What is Univariate, Bivariate & Multivariate Analysis in Data Visualisation?
- Using pandas crosstab to create a bar plot
- Exploring Correlation in Python
- Mathematics | Covariance and Correlation
- Introduction to Factor Analysis
- Data Mining - Cluster Analysis
- MANOVA Test in R Programming
- Python - Central Limit Theorem
- Probability Distribution Function
- Probability Density Estimation & Maximum Likelihood Estimation
- Exponential Distribution in R Programming - dexp(), pexp(), qexp(), and rexp() Functions
- Mathematics | Probability Distributions Set 4 (Binomial Distribution)
- Poisson Distribution - Definition, Formula, Table and Examples
- P-Value: Comprehensive Guide to Understand, Apply, and Interpret
- Z-Score in Statistics
- How to Calculate Point Estimates in R?
- Confidence Interval
- Chi-square test in Machine Learning
Understanding Hypothesis Testing
Data preprocessing.
- ML | Data Preprocessing in Python
- ML | Overview of Data Cleaning
- ML | Handling Missing Values
- Detect and Remove the Outliers using Python
Data Transformation
- Data Normalization Machine Learning
- Sampling distribution Using Python
Time Series Data Analysis
- Data Mining - Time-Series, Symbolic and Biological Sequences Data
- Basic DateTime Operations in Python
- Time Series Analysis & Visualization in Python
- How to deal with missing values in a Timeseries in Python?
- How to calculate MOVING AVERAGE in a Pandas DataFrame?
- What is a trend in time series?
- How to Perform an Augmented Dickey-Fuller Test in R
- AutoCorrelation
Case Studies and Projects
- Top 8 Free Dataset Sources to Use for Data Science Projects
- Step by Step Predictive Analysis - Machine Learning
- 6 Tips for Creating Effective Data Visualizations
Hypothesis testing involves formulating assumptions about population parameters based on sample statistics and rigorously evaluating these assumptions against empirical evidence. This article sheds light on the significance of hypothesis testing and the critical steps involved in the process.
What is Hypothesis Testing?
Hypothesis testing is a statistical method that is used to make a statistical decision using experimental data. Hypothesis testing is basically an assumption that we make about a population parameter. It evaluates two mutually exclusive statements about a population to determine which statement is best supported by the sample data.
Example: You say an average height in the class is 30 or a boy is taller than a girl. All of these is an assumption that we are assuming, and we need some statistical way to prove these. We need some mathematical conclusion whatever we are assuming is true.
Defining Hypotheses

Key Terms of Hypothesis Testing

- P-value: The P value , or calculated probability, is the probability of finding the observed/extreme results when the null hypothesis(H0) of a study-given problem is true. If your P-value is less than the chosen significance level then you reject the null hypothesis i.e. accept that your sample claims to support the alternative hypothesis.
- Test Statistic: The test statistic is a numerical value calculated from sample data during a hypothesis test, used to determine whether to reject the null hypothesis. It is compared to a critical value or p-value to make decisions about the statistical significance of the observed results.
- Critical value : The critical value in statistics is a threshold or cutoff point used to determine whether to reject the null hypothesis in a hypothesis test.
- Degrees of freedom: Degrees of freedom are associated with the variability or freedom one has in estimating a parameter. The degrees of freedom are related to the sample size and determine the shape.
Why do we use Hypothesis Testing?
Hypothesis testing is an important procedure in statistics. Hypothesis testing evaluates two mutually exclusive population statements to determine which statement is most supported by sample data. When we say that the findings are statistically significant, thanks to hypothesis testing.
One-Tailed and Two-Tailed Test
One tailed test focuses on one direction, either greater than or less than a specified value. We use a one-tailed test when there is a clear directional expectation based on prior knowledge or theory. The critical region is located on only one side of the distribution curve. If the sample falls into this critical region, the null hypothesis is rejected in favor of the alternative hypothesis.
One-Tailed Test
There are two types of one-tailed test:

Two-Tailed Test
A two-tailed test considers both directions, greater than and less than a specified value.We use a two-tailed test when there is no specific directional expectation, and want to detect any significant difference.

What are Type 1 and Type 2 errors in Hypothesis Testing?
In hypothesis testing, Type I and Type II errors are two possible errors that researchers can make when drawing conclusions about a population based on a sample of data. These errors are associated with the decisions made regarding the null hypothesis and the alternative hypothesis.

How does Hypothesis Testing work?
Step 1: define null and alternative hypothesis.

We first identify the problem about which we want to make an assumption keeping in mind that our assumption should be contradictory to one another, assuming Normally distributed data.
Step 2 – Choose significance level

Step 3 – Collect and Analyze data.
Gather relevant data through observation or experimentation. Analyze the data using appropriate statistical methods to obtain a test statistic.
Step 4-Calculate Test Statistic
The data for the tests are evaluated in this step we look for various scores based on the characteristics of data. The choice of the test statistic depends on the type of hypothesis test being conducted.
There are various hypothesis tests, each appropriate for various goal to calculate our test. This could be a Z-test , Chi-square , T-test , and so on.
- Z-test : If population means and standard deviations are known. Z-statistic is commonly used.
- t-test : If population standard deviations are unknown. and sample size is small than t-test statistic is more appropriate.
- Chi-square test : Chi-square test is used for categorical data or for testing independence in contingency tables
- F-test : F-test is often used in analysis of variance (ANOVA) to compare variances or test the equality of means across multiple groups.
We have a smaller dataset, So, T-test is more appropriate to test our hypothesis.
T-statistic is a measure of the difference between the means of two groups relative to the variability within each group. It is calculated as the difference between the sample means divided by the standard error of the difference. It is also known as the t-value or t-score.
Step 5 – Comparing Test Statistic:
In this stage, we decide where we should accept the null hypothesis or reject the null hypothesis. There are two ways to decide where we should accept or reject the null hypothesis.
Method A: Using Crtical values
Comparing the test statistic and tabulated critical value we have,
- If Test Statistic>Critical Value: Reject the null hypothesis.
- If Test Statistic≤Critical Value: Fail to reject the null hypothesis.
Note: Critical values are predetermined threshold values that are used to make a decision in hypothesis testing. To determine critical values for hypothesis testing, we typically refer to a statistical distribution table , such as the normal distribution or t-distribution tables based on.
Method B: Using P-values
We can also come to an conclusion using the p-value,

Note : The p-value is the probability of obtaining a test statistic as extreme as, or more extreme than, the one observed in the sample, assuming the null hypothesis is true. To determine p-value for hypothesis testing, we typically refer to a statistical distribution table , such as the normal distribution or t-distribution tables based on.
Step 7- Interpret the Results
At last, we can conclude our experiment using method A or B.
Calculating test statistic
To validate our hypothesis about a population parameter we use statistical functions . We use the z-score, p-value, and level of significance(alpha) to make evidence for our hypothesis for normally distributed data .
1. Z-statistics:
When population means and standard deviations are known.

- μ represents the population mean,
- σ is the standard deviation
- and n is the size of the sample.
2. T-Statistics
T test is used when n<30,
t-statistic calculation is given by:

- t = t-score,
- x̄ = sample mean
- μ = population mean,
- s = standard deviation of the sample,
- n = sample size
3. Chi-Square Test
Chi-Square Test for Independence categorical Data (Non-normally distributed) using:

- i,j are the rows and columns index respectively.

Real life Hypothesis Testing example
Let’s examine hypothesis testing using two real life situations,
Case A: D oes a New Drug Affect Blood Pressure?
Imagine a pharmaceutical company has developed a new drug that they believe can effectively lower blood pressure in patients with hypertension. Before bringing the drug to market, they need to conduct a study to assess its impact on blood pressure.
- Before Treatment: 120, 122, 118, 130, 125, 128, 115, 121, 123, 119
- After Treatment: 115, 120, 112, 128, 122, 125, 110, 117, 119, 114
Step 1 : Define the Hypothesis
- Null Hypothesis : (H 0 )The new drug has no effect on blood pressure.
- Alternate Hypothesis : (H 1 )The new drug has an effect on blood pressure.
Step 2: Define the Significance level
Let’s consider the Significance level at 0.05, indicating rejection of the null hypothesis.
If the evidence suggests less than a 5% chance of observing the results due to random variation.
Step 3 : Compute the test statistic
Using paired T-test analyze the data to obtain a test statistic and a p-value.
The test statistic (e.g., T-statistic) is calculated based on the differences between blood pressure measurements before and after treatment.
t = m/(s/√n)
- m = mean of the difference i.e X after, X before
- s = standard deviation of the difference (d) i.e d i = X after, i − X before,
- n = sample size,
then, m= -3.9, s= 1.8 and n= 10
we, calculate the , T-statistic = -9 based on the formula for paired t test
Step 4: Find the p-value
The calculated t-statistic is -9 and degrees of freedom df = 9, you can find the p-value using statistical software or a t-distribution table.
thus, p-value = 8.538051223166285e-06
Step 5: Result
- If the p-value is less than or equal to 0.05, the researchers reject the null hypothesis.
- If the p-value is greater than 0.05, they fail to reject the null hypothesis.
Conclusion: Since the p-value (8.538051223166285e-06) is less than the significance level (0.05), the researchers reject the null hypothesis. There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different.
Python Implementation of Hypothesis Testing
Let’s create hypothesis testing with python, where we are testing whether a new drug affects blood pressure. For this example, we will use a paired T-test. We’ll use the scipy.stats library for the T-test.
Scipy is a mathematical library in Python that is mostly used for mathematical equations and computations.
We will implement our first real life problem via python,
In the above example, given the T-statistic of approximately -9 and an extremely small p-value, the results indicate a strong case to reject the null hypothesis at a significance level of 0.05.
- The results suggest that the new drug, treatment, or intervention has a significant effect on lowering blood pressure.
- The negative T-statistic indicates that the mean blood pressure after treatment is significantly lower than the assumed population mean before treatment.
Case B : Cholesterol level in a population
Data: A sample of 25 individuals is taken, and their cholesterol levels are measured.
Cholesterol Levels (mg/dL): 205, 198, 210, 190, 215, 205, 200, 192, 198, 205, 198, 202, 208, 200, 205, 198, 205, 210, 192, 205, 198, 205, 210, 192, 205.
Populations Mean = 200
Population Standard Deviation (σ): 5 mg/dL(given for this problem)
Step 1: Define the Hypothesis
- Null Hypothesis (H 0 ): The average cholesterol level in a population is 200 mg/dL.
- Alternate Hypothesis (H 1 ): The average cholesterol level in a population is different from 200 mg/dL.
As the direction of deviation is not given , we assume a two-tailed test, and based on a normal distribution table, the critical values for a significance level of 0.05 (two-tailed) can be calculated through the z-table and are approximately -1.96 and 1.96.

Step 4: Result
Since the absolute value of the test statistic (2.04) is greater than the critical value (1.96), we reject the null hypothesis. And conclude that, there is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL
Limitations of Hypothesis Testing
- Although a useful technique, hypothesis testing does not offer a comprehensive grasp of the topic being studied. Without fully reflecting the intricacy or whole context of the phenomena, it concentrates on certain hypotheses and statistical significance.
- The accuracy of hypothesis testing results is contingent on the quality of available data and the appropriateness of statistical methods used. Inaccurate data or poorly formulated hypotheses can lead to incorrect conclusions.
- Relying solely on hypothesis testing may cause analysts to overlook significant patterns or relationships in the data that are not captured by the specific hypotheses being tested. This limitation underscores the importance of complimenting hypothesis testing with other analytical approaches.
Hypothesis testing stands as a cornerstone in statistical analysis, enabling data scientists to navigate uncertainties and draw credible inferences from sample data. By systematically defining null and alternative hypotheses, choosing significance levels, and leveraging statistical tests, researchers can assess the validity of their assumptions. The article also elucidates the critical distinction between Type I and Type II errors, providing a comprehensive understanding of the nuanced decision-making process inherent in hypothesis testing. The real-life example of testing a new drug’s effect on blood pressure using a paired T-test showcases the practical application of these principles, underscoring the importance of statistical rigor in data-driven decision-making.
Frequently Asked Questions (FAQs)
1. what are the 3 types of hypothesis test.
There are three types of hypothesis tests: right-tailed, left-tailed, and two-tailed. Right-tailed tests assess if a parameter is greater, left-tailed if lesser. Two-tailed tests check for non-directional differences, greater or lesser.
2.What are the 4 components of hypothesis testing?
Null Hypothesis ( ): No effect or difference exists. Alternative Hypothesis ( ): An effect or difference exists. Significance Level ( ): Risk of rejecting null hypothesis when it’s true (Type I error). Test Statistic: Numerical value representing observed evidence against null hypothesis.
3.What is hypothesis testing in ML?
Statistical method to evaluate the performance and validity of machine learning models. Tests specific hypotheses about model behavior, like whether features influence predictions or if a model generalizes well to unseen data.
4.What is the difference between Pytest and hypothesis in Python?
Pytest purposes general testing framework for Python code while Hypothesis is a Property-based testing framework for Python, focusing on generating test cases based on specified properties of the code.
Please Login to comment...
Similar reads.
- data-science
- Data Science
- Machine Learning
- 10 Best Todoist Alternatives in 2024 (Free)
- How to Get Spotify Premium Free Forever on iOS/Android
- Yahoo Acquires Instagram Co-Founders' AI News Platform Artifact
- OpenAI Introduces DALL-E Editor Interface
- Top 10 R Project Ideas for Beginners in 2024
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
Science-Based Medicine
Exploring issues and controversies in the relationship between science and medicine

Dr. Marty Makary: “We’ll Have Herd Immunity by April” & “It’s Okay To Have an Incorrect Scientific Hypothesis. But When New Data Proves It Wrong, You Have To Adapt.”
Part 1: Doctors who said the pandemic ended 3-years ago now have the audacity to lament the “damaged public trust in the medical profession.”
Unfortunately, many elected leaders and public health officials have held on far too long to the hypothesis that natural immunity offers unreliable protection against covid-19 — a contention that is being rapidly debunked by science.
On September 15th, 2021, Dr. Marty Makary authored an article titled Natural Immunity to Covid Is Powerful. Policymakers Seem Afraid to Say So . It started by saying:
It’s okay to have an incorrect scientific hypothesis. But when new data proves it wrong, you have to adapt. Unfortunately, many elected leaders and public health officials have held on far too long to the hypothesis that natural immunity offers unreliable protection against covid-19 — a contention that is being rapidly debunked by science.
These three sentences have an interesting relationship, don’t they?
We’ll Have Herd Immunity by April
I’ll return to them in a bit, but first let’s flashback to February 2021. 450,000 Americans died of COVID in in the pandemic’s first year, overwhelming hospitals and morgues. The worst wave, where over 3,000 Americans died per day, was just receding. The virus was just 1 year-old, and it had given us plenty of reasons to respect it so far.
Not everyone felt that way.
On February 18th, Dr. Markary authored an article titled We’ll Have Herd Immunity by April . He was very confident about this new virus. “Experts should level with the public about the good news,” he said. He said:
Some medical experts privately agreed with my prediction that there may be very little Covid-19 by April but suggested that I not to talk publicly about herd immunity because people might become complacent and fail to take precautions or might decline the vaccine. But scientists shouldn’t try to manipulate the public by hiding the truth…Herd immunity is the inevitable result of viral spread and vaccination. When the chain of virus transmission has been broken in multiple places, it’s harder for it to spread—and that includes the new strains.
Then in March, he authored an article titled Herd Immunity Is Near, Despite Fauci’s Denial . He said:
Anthony Fauci has been saying that the country needs to vaccinate 70% to 85% of the population to reach herd immunity from Covid-19. But he inexplicably ignores natural immunity. If you account for previous infections, herd immunity is likely close at hand.
In May, Dr. Makary continued his media blitz to announce big news . He had been right. Herd immunity had arrived, and it was time to “stop living in fear”. In an article titled Don’t Buy The Fearmongering: The COVID-19 Threat Is Waning he said “On a clinical level, we simply have not seen significant re-infections at any concerning rate.” “The public-health threat is now defanged”, he added.
In another article titled Risk Of COVID Is Now Very Low — It’s Time To Stop Living In Fear: Doctor he said:
COVID cases are collapsing in front of our eyes…Yet some people want the pandemic to stretch out longer
During an interview on Fox New that month, he dismissed the concerns about variants and said the main priority was to not “scare people”. “People need something to look forward to,” he said. He also had this exchange :
Question : You talked about this a couple of months ago. You said look, we are two months away from herd immunity. Are we there, are we closer, is it ever going to be full realized in your estimation? Answer : Well unfortunately, we have this perception now that’s being created by some public health leaders that we reach to total eradication. And we’re not going to get to total risk elimination. That is a false goal and quite honestly it’s being used to manipulate the public. We heard today if get to 70% vaccination, then we can see restrictions. That’s dishonest. Most of the country is at herd immunity. Other parts will get there later this month… I call that herd immunity.
I don’t remember anyone serious talking about “total risk elimination” in May 2021, though through this straw man argument, Dr. Makary sought to convince his audience that “public health leaders” were dishonest manipulators out to scare people. In contrast, he was a straight shooter, willing to tell bravely the truth- most of the country is at herd immunity .
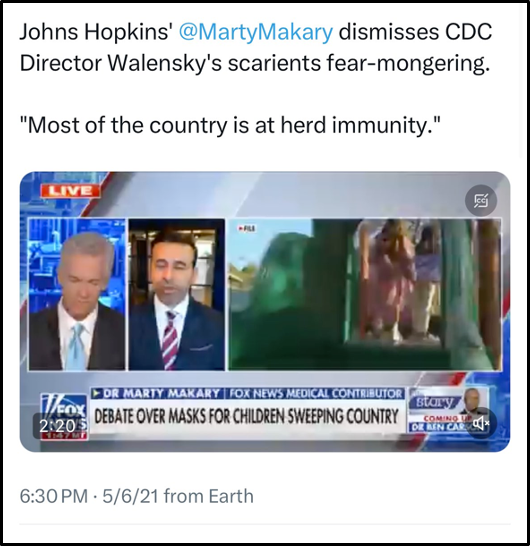
In June, Dr. Makary formalized his thoughts in an article called The Power of Natural Immunity , another article that paid homage to the “power” of being infected with a potentially deadly virus. He said:
The news about the U.S. Covid pandemic is even better than you’ve heard… There’s ample scientific evidence that natural immunity is effective and durable, and public-health leaders should pay it heed.
With more than 8 in 10 adults protected from either contracting or transmitting the virus, it can’t readily propagate by jumping around in the population. In public health, we call that herd immunity, defined broadly on the Johns Hopkins Covid information webpage as “when most of a population is immune.” It’s not eradication, but it’s powerful.
Dr. Makary concluded:
It’s time to stop the fear mongering and level with the public.
So far this year, nearly 2.8 million cases of COVID have been reported in the U.S.
Let’s return to those three sentences from Dr. Makary’s article Natural Immunity to Covid Is Powerful. Policymakers Seem Afraid to Say So :
We all know what happened next.
Since February 2021, when Dr. Makary penned We’ll Have Herd Immunity by April, around 700,000 Americans have died of COVID and millions more have been injured by it. It’s not over yet. Unfortunately, those “elected leaders and public health officials” turned out to be right. Natural immunity offers unreliable protection against COVID, and reinfections are hardly rare events. Despite the abundance and “power” of natural immunity, we still do not have herd immunity.
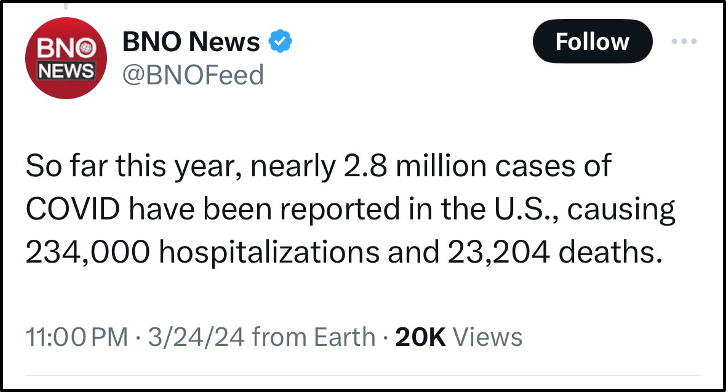
Delta is downgraded to a mild seasonal virus that causes mild common cold-like symptoms.
So, did Dr. Makary adapt when new data proved his scientific hypothesis was incorrect? Not that I’ve seen. I have not seen him acknowledge his bizarre fetishization of the “power of natural immunity” was misplaced. I have not seen him revisit his doomed declarations of herd immunity. I have not seen him retract his unprofessional slurs that “public health leaders” were “dishonest” and trying to “manipulate the public” because they wanted the pandemic to continue.
He’s not alone.
Many doctors sounded exactly like Dr. Makary in 2021. These “free-thinking” doctors also claimed that natural immunity was a “ triumph ,” that vaccines were a panacea for those who needed them, that variants were nothing to “panic” about, and that kid’s didn’t need the COVID vaccine because the pandemic was ending . They too disparaged anyone who disagreed as having an “ addiction to doom and gloom. ”
Yet, when the pandemic failed to end, these doctors just barreled on full-steam ahead as if none of that ever happened. Their confident, optimistic proclamations- most of the country is at herd immunity – were made and then instantly forgotten, without a moment’s recognition of error or the slightest expression of regret to those they smeared as “fear mongers.”
In fact, doctors who said the pandemic was winding down in the first half of 2021, devoted the second half of that year not to pausing their COVID commentary and reflecting on their failed forecasts, but rather by doubling down and minimizing the variants that obliterated their pollyannaish predictions. No matter what was happening on the ground, they just kept robotically repeating the exact same things they’d always said. There was always “ reassuring data “. It was always time to stop “ living in fear “. They were all completely predictable.
- Dr. Jay Bhattacharya, who said in March, “We should not be particularly concerned about the variants,” said in July , “I don’t think the Delta variant changes the calculus or the evidence in any fundamental way.” Then in December, he starred in a podcast titled Why No One Should Panic About the Omicron Variant , in which he said “this is not something to panic about.”
- Dr. Monica Gandhi, who gave an interview titled Pandemic Exit Interviews: Stop Panicking About the COVID-19 Variants, Says UCSF’s Monica Gandhi in February, wrote an article titled The Reassuring Data on the Delta Variant in July. Then in December, she gave an interview titled, The Cautious Case for Omicron Optimism Dr. Monica Gandhi Says There’s Reason to Trust Preliminary Reports of Mild Illness .
- Dr. Zubin Damania, who recorded a podcast with Dr. Gandhi called The End of the Pandemic in February, wrote an article titled The Delta Surge May Collapse Faster Than You Think in August. Then, in January 2022, he said the Omicron variant was “Omi-cold, and we generate immunity from being infected by it”.
- Dr. Lucy McBride, who wrote I’ve Been Yearning For An End To The Pandemic. Now That It’s Here, I’m A Little Afraid in March, wrote an article about the Delta variant titled Fear of COVID-19 in Kids Is Getting Ahead of the Data in August, as if waiting for “data” before reacting to a deadly virus is always wise.
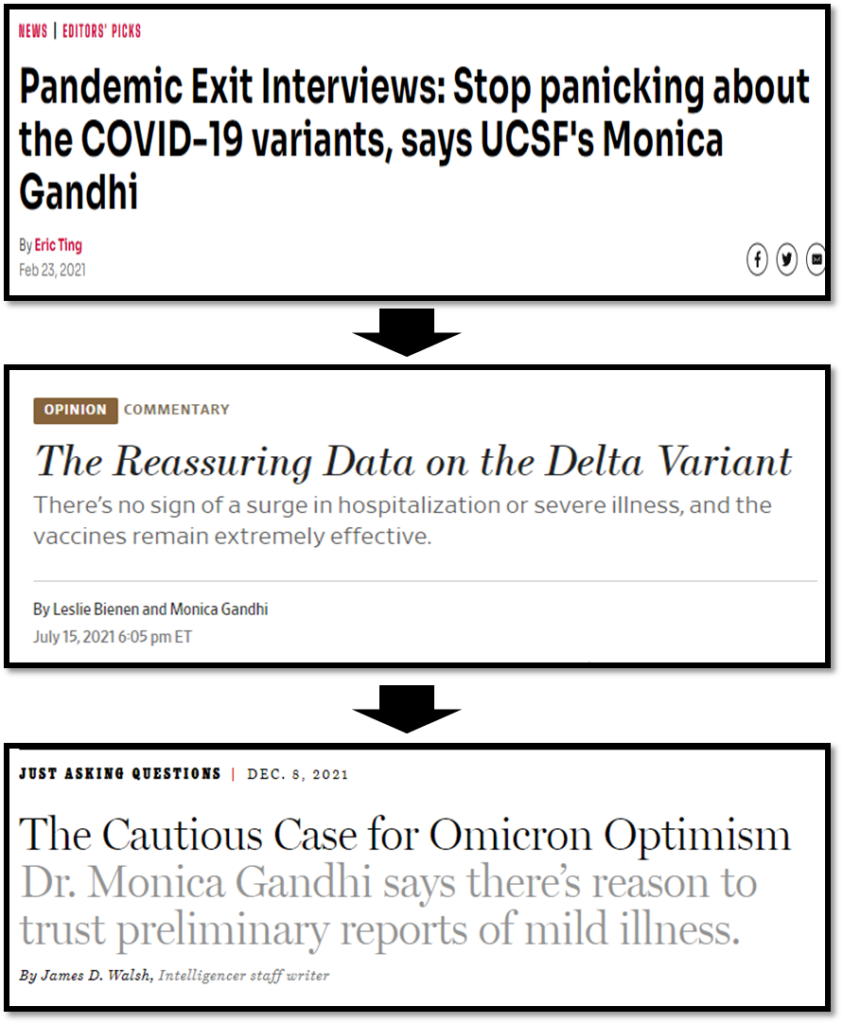
Articles from February, July, and December 2021
Like these doctors, Dr. Makary also failed to adapt to new data when the Delta variant arrived, wrecking his declarations of herd immunity. As it ripped through much the country , he just kept robotically repeating the exact same things he’d always said. He gave in interview in June titled Dr. Marty Makary Pans ‘Fear-Mongering’ Over Delta Variant , and in August he said :
If you’re one of the 99%+ of kids that are unvaccinated…those kids don’t need to worry…For most people right now, Delta is downgraded to a mild seasonal virus that causes mild common cold-like symptoms…The vaccines have been perfectly consistent against all of the variants.
Of course, Dr. Makary and these other doctors were wrong about the Delta variant, which caused “ record deaths ” in many parts of the country and hit children harder than ever before, especially unvaccinated ones .
Predictably, Dr. Makary also failed to adapt to new data when the Omicron variant arrived. As it ripped through much the country , he just kept robotically repeating the exact same things he’d always said. In December, he glorified the Omicron variant as “ nature’s vaccine ” and in an interview on Fox News titled Omicron Fear Fueling a ‘Second Pandemic of Lunacy’ said:
We’re seeing this massive new wave of fear that is fueling our second pandemic after COVID-19, which is a pandemic of lunacy, which is omicron. Now I call it omi-cold… This new scientific data from the lab explains the epidemiological data and the bedside observation of doctors that this is far more mild… and that’s why I call it omi-cold.
Of course, Dr. Makary and these other doctors were wrong about the Omicron variant, as the articles During the Omicron Wave, Death Rates Soared for Older People and Hospitalizations Of Young Children With The Virus Surged During The U.S. Omicron Wave explain.
All that from the doctor who instructed others :
It’s okay to have an incorrect scientific hypothesis. But when new data proves it wrong, you have to adapt.
Public health officials actively propagated misinformation that ruined lives and forever damaged public trust in the medical profession.
Many people adapted to new data and relinquished their optimistic pandemic estimations when immune-evading variants arrived in the summer of 2021. These doctors did not. Minimizing COVID was a pure reflex for them. It was literally all they could do. What more could the virus have done to make them say, “ OOPS! I was wrong to have said the pandemic was over “? The answer, of course, is “nothing.”
To my knowledge, just one of these doctors has ever acknowledged error for prematurely declaring the pandemic over. He’s also stopped doing this. Good for him. However, I can’t recall any doctor who said the pandemic ended in spring 2021 who later had the integrity to honestly reckon with the consequences of blasting out that false message in major media outlets for months on end. Million of Americans trusted these highly-credential doctors who spoke with great confidence when they said what we all wanted to hear.
How are these people doing today? Did all they all turn out OK?
Predictably, instead of showing even a hint of concern about the fate of their audience and introspecting for a nanosecond, these doctors keep robotically repeating the exact same things they’ve always said. Despite his inglorious track record, Dr. Makary still fancies himself a brave truth-teller, entitled to sanctimoniously scold those dastardly “public health officials”. In an article from February 2023, ironically titled 10 Myths Told by COVID Experts — And Now Debunked , Dr. Makary spread blatant anti-vaccine falsities and continued to lavish praise on “natural immunity”. He also said this:
Imagine the utter audacity, shamelessness, and lack of self-awareness it takes for the author of We’ll Have Herd Immunity by April to write that contemptible slur about people who were right about herd immunity 3-years ago. Nonetheless, I won’t disagree with him for saying:
That’s actually a really good idea.
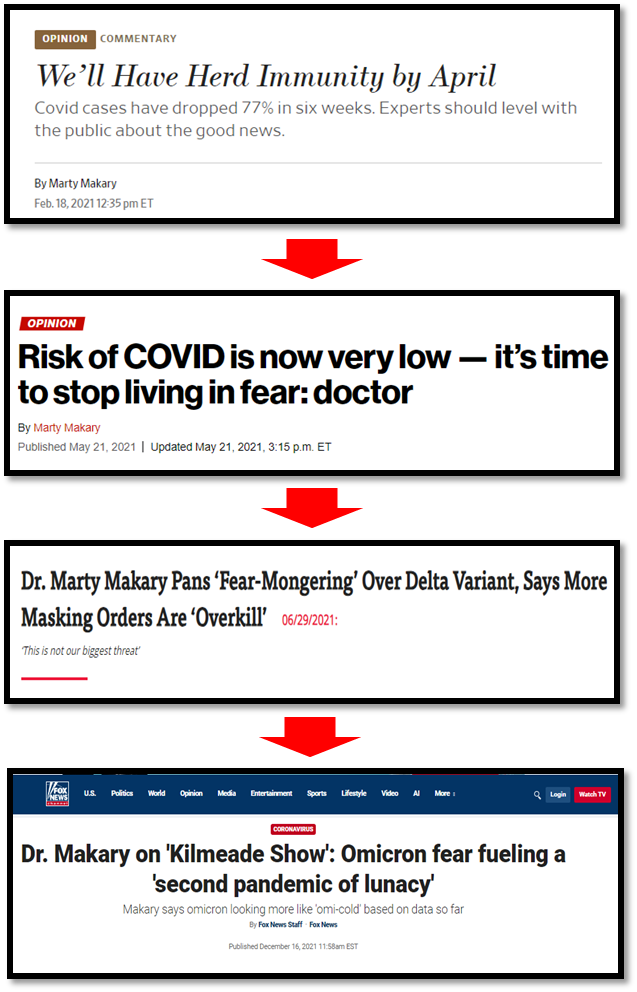
Articles from February, May, June, and December 2021
Dr. Jonathan Howard is a neurologist and psychiatrist who has been interested in vaccines since long before COVID-19. He is the author of "We Want Them Infected: How the failed quest for herd immunity led doctors to embrace the anti-vaccine movement and blinded Americans to the threat of COVID."
View all posts
- Posted in: Science and Medicine
Posted by Jonathan Howard
Help | Advanced Search
Astrophysics > Earth and Planetary Astrophysics
Title: vulcan: retreading a tired hypothesis with the 2024 total solar eclipse.
Abstract: The number of planets in the solar system over the last three centuries has, perhaps surprisingly, been less of a fixed value than one would think it should be. In this paper, we look at the specific case of Vulcan, which was both a planet before Pluto was a planet and discarded from being a planet before Pluto was downgraded. We examine the historical context that led to its discovery in the 19th century, the decades of observations that were taken of it, and its eventual fall from glory. By applying a more modern understanding of astrophysics, we provide multiple mechanisms that may have changed the orbit of Vulcan sufficiently that it would have been outside the footprint of early 20th century searches for it. Finally, we discuss how the April 8, 2024 eclipse provides a renewed opportunity to rediscover this lost planet after more than a century of having been overlooked.
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
1 blog link
Bibtex formatted citation.
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
IMAGES
VIDEO
COMMENTS
There are 5 main steps in hypothesis testing: State your research hypothesis as a null hypothesis and alternate hypothesis (H o) and (H a or H 1 ). Collect data in a way designed to test the hypothesis. Perform an appropriate statistical test. Decide whether to reject or fail to reject your null hypothesis. Present the findings in your results ...
4. Photo by Anna Nekrashevich from Pexels. Hypothesis testing is a common statistical tool used in research and data science to support the certainty of findings. The aim of testing is to answer how probable an apparent effect is detected by chance given a random data sample. This article provides a detailed explanation of the key concepts in ...
Test Statistic: z = ¯ x − μo σ / √n since it is calculated as part of the testing of the hypothesis. Definition 7.1.4. p - value: probability that the test statistic will take on more extreme values than the observed test statistic, given that the null hypothesis is true.
Step 5: Phrase your hypothesis in three ways. To identify the variables, you can write a simple prediction in if … then form. The first part of the sentence states the independent variable and the second part states the dependent variable. If a first-year student starts attending more lectures, then their exam scores will improve.
Y&L advocate "hypothesis-free" data exploration, which they argue can yield significant scientific discoveries. We disagree. While we concur that a bad hypothesis is a liability, there is no such thing as hypothesis-free data exploration. Observation and data are always hypothesis- or theory-laden. Data is meaningless without some form of ...
The Four Steps in Hypothesis Testing. STEP 1: State the appropriate null and alternative hypotheses, Ho and Ha. STEP 2: Obtain a random sample, collect relevant data, and check whether the data meet the conditions under which the test can be used. If the conditions are met, summarize the data using a test statistic.
Hypothesis testing is a crucial procedure to perform when you want to make inferences about a population using a random sample. These inferences include estimating population properties such as the mean, differences between means, proportions, and the relationships between variables. This post provides an overview of statistical hypothesis testing.
Hypothesis testing is a statistical method used to evaluate a claim or hypothesis about a population parameter based on sample data. It involves making decisions about the validity of a statement, often referred to as the null hypothesis, by assessing the likelihood of observing the sample data if the null hypothesis were true.
We start with two hypotheses H₀ and H₁ such that the distribution of the underlying data depends on the hypotheses. The goal is to prove or disprove the null hypothesis H₀ by finding a decision rule that maps the realized value of the observation x to one of the two hypotheses. Finally, we calculate the errors associated with the decision ...
Collecting Data on Your Hypothesis . Once a researcher has formed a testable hypothesis, the next step is to select a research design and start collecting data. The research method depends largely on exactly what they are studying. There are two basic types of research methods: descriptive research and experimental research. ...
The null hypothesis, denoted as H 0, is the hypothesis that the sample data occurs purely from chance. The alternative hypothesis, denoted as H 1 or H a, is the hypothesis that the sample data is influenced by some non-random cause. Hypothesis Tests. A hypothesis test consists of five steps: 1. State the hypotheses. State the null and ...
5.2 - Writing Hypotheses. The first step in conducting a hypothesis test is to write the hypothesis statements that are going to be tested. For each test you will have a null hypothesis ( H 0) and an alternative hypothesis ( H a ). Null Hypothesis. The statement that there is not a difference in the population (s), denoted as H 0.
Definition: Hypothesis is an educated guess or proposed explanation for a phenomenon, based on some initial observations or data. It is a tentative statement that can be tested and potentially proven or disproven through further investigation and experimentation. Hypothesis is often used in scientific research to guide the design of experiments ...
When to perform a statistical test. You can perform statistical tests on data that have been collected in a statistically valid manner - either through an experiment, or through observations made using probability sampling methods.. For a statistical test to be valid, your sample size needs to be large enough to approximate the true distribution of the population being studied.
Alternative hypothesis (H A): Two population means are not equal (µ 1 ≠ µ 2). Again, when the p-value is less than or equal to your significance level, reject the null hypothesis. The difference between the two means is statistically significant. Your sample data support the theory that the two population means are different.
Hypothesis testing is a statistical method used to determine if there is enough evidence in a sample data to draw conclusions about a population. It involves formulating two competing hypotheses, the null hypothesis (H0) and the alternative hypothesis (Ha), and then collecting data to assess the evidence.
The actual test begins by considering two hypotheses.They are called the null hypothesis and the alternative hypothesis.These hypotheses contain opposing viewpoints. H 0, the —null hypothesis: a statement of no difference between sample means or proportions or no difference between a sample mean or proportion and a population mean or proportion. In other words, the difference equals 0.
Composite Hypothesis: It does not denote the population distribution. Exact Hypothesis: In the exact hypothesis, the value of the hypothesis is the same as the sample distribution. Example- μ= 10. Inexact Hypothesis: Here, the hypothesis values are not equal to the sample. It will denote a particular range of values.
Data Analysis for Hypothesis Testing. Now, let's look in a little more detail at the seven steps required to conduct a hypothesis test, when you are working with data from a survey sample. Estimate a population parameter. The first step in the analysis to estimate the value of the population parameter that appears in the null hypothesis.
In statistics, a hypothesis test is used to test some assumption about a population parameter. There are many different types of hypothesis tests you can perform depending on the type of data you're working with and the goal of your analysis. This tutorial explains how to perform the following types of hypothesis tests in Excel: One sample t ...
Explore four types of data analysis with examples. Data analysis is the practice of working with data to glean useful information, which can then be used to make informed decisions. "It is a capital mistake to theorize before one has data. Insensibly, one begins to twist facts to suit theories, instead of theories to suit facts," Sherlock ...
Hypothesis testing is a statistical method that is used to make a statistical decision using experimental data. Hypothesis testing is basically an assumption that we make about a population parameter. It evaluates two mutually exclusive statements about a population to determine which statement is best supported by the sample data.
Hypothesis testing is a cornerstone of data science, allowing you to make inferences about populations from sample data. It involves assuming a null hypothesis and then using statistical analysis ...
It's okay to have an incorrect scientific hypothesis. But when new data proves it wrong, you have to adapt. Unfortunately, many elected leaders and public health officials have held on far too long to the hypothesis that natural immunity offers unreliable protection against covid-19 — a contention that is being rapidly debunked by science.
Vulcan: Retreading a Tired Hypothesis with the 2024 Total Solar Eclipse. The number of planets in the solar system over the last three centuries has, perhaps surprisingly, been less of a fixed value than one would think it should be. In this paper, we look at the specific case of Vulcan, which was both a planet before Pluto was a planet and ...