- Python Programming
- C Programming
- Numerical Methods
- Dart Language
- Computer Basics
- Deep Learning
- C Programming Examples
- Python Programming Examples

Problem Solving Using Computer (Steps)
Computer based problem solving is a systematic process of designing, implementing and using programming tools during the problem solving stage. This method enables the computer system to be more intuitive with human logic than machine logic. Final outcome of this process is software tools which is dedicated to solve the problem under consideration. Software is just a collection of computer programs and programs are a set of instructions which guides computer’s hardware. These instructions need to be well specified for solving the problem. After its creation, the software should be error free and well documented. Software development is the process of creating such software, which satisfies end user’s requirements and needs.
The following six steps must be followed to solve a problem using computer.
- Problem Analysis
- Program Design - Algorithm, Flowchart and Pseudocode
- Compilation and Execution
- Debugging and Testing
- Program Documentation
Exploring the Problem Solving Cycle in Computer Science – Strategies, Techniques, and Tools
- Post author By bicycle-u
- Post date 08.12.2023
The world of computer science is built on the foundation of problem solving. Whether it’s finding a solution to a complex algorithm or analyzing data to make informed decisions, the problem solving cycle is at the core of every computer science endeavor.
At its essence, problem solving in computer science involves breaking down a complex problem into smaller, more manageable parts. This allows for a systematic approach to finding a solution by analyzing each part individually. The process typically starts with gathering and understanding the data or information related to the problem at hand.
Once the data is collected, computer scientists use various techniques and algorithms to analyze and explore possible solutions. This involves evaluating different approaches and considering factors such as efficiency, accuracy, and scalability. During this analysis phase, it is crucial to think critically and creatively to come up with innovative solutions.
After a thorough analysis, the next step in the problem solving cycle is designing and implementing a solution. This involves creating a detailed plan of action, selecting the appropriate tools and technologies, and writing the necessary code to bring the solution to life. Attention to detail and precision are key in this stage to ensure that the solution functions as intended.
The final step in the problem solving cycle is evaluating the solution and its effectiveness. This includes testing the solution against different scenarios and data sets to ensure its reliability and performance. If any issues or limitations are discovered, adjustments and optimizations are made to improve the solution.
In conclusion, the problem solving cycle is a fundamental process in computer science, involving analysis, data exploration, algorithm development, solution implementation, and evaluation. It is through this cycle that computer scientists are able to tackle complex problems and create innovative solutions that drive progress in the field of computer science.
Understanding the Importance
In computer science, problem solving is a crucial skill that is at the core of the problem solving cycle. The problem solving cycle is a systematic approach to analyzing and solving problems, involving various stages such as problem identification, analysis, algorithm design, implementation, and evaluation. Understanding the importance of this cycle is essential for any computer scientist or programmer.
Data Analysis and Algorithm Design
The first step in the problem solving cycle is problem identification, which involves recognizing and defining the issue at hand. Once the problem is identified, the next crucial step is data analysis. This involves gathering and examining relevant data to gain insights and understand the problem better. Data analysis helps in identifying patterns, trends, and potential solutions.
After data analysis, the next step is algorithm design. An algorithm is a step-by-step procedure or set of rules to solve a problem. Designing an efficient algorithm is crucial as it determines the effectiveness and efficiency of the solution. A well-designed algorithm takes into consideration the constraints, resources, and desired outcomes while implementing the solution.
Implementation and Evaluation
Once the algorithm is designed, the next step in the problem solving cycle is implementation. This involves translating the algorithm into a computer program using a programming language. The implementation phase requires coding skills and expertise in a specific programming language.
After implementation, the solution needs to be evaluated to ensure that it solves the problem effectively. Evaluation involves testing the program and verifying its correctness and efficiency. This step is critical to identify any errors or issues and to make necessary improvements or adjustments.
In conclusion, understanding the importance of the problem solving cycle in computer science is essential for any computer scientist or programmer. It provides a systematic and structured approach to analyze and solve problems, ensuring efficient and effective solutions. By following the problem solving cycle, computer scientists can develop robust algorithms, implement them in efficient programs, and evaluate their solutions to ensure their correctness and efficiency.
Identifying the Problem
In the problem solving cycle in computer science, the first step is to identify the problem that needs to be solved. This step is crucial because without a clear understanding of the problem, it is impossible to find a solution.
Identification of the problem involves a thorough analysis of the given data and understanding the goals of the task at hand. It requires careful examination of the problem statement and any constraints or limitations that may affect the solution.
During the identification phase, the problem is broken down into smaller, more manageable parts. This can involve breaking the problem down into sub-problems or identifying the different aspects or components that need to be addressed.
Identifying the problem also involves considering the resources and tools available for solving it. This may include considering the specific tools and programming languages that are best suited for the problem at hand.
By properly identifying the problem, computer scientists can ensure that they are focused on the right goals and are better equipped to find an effective and efficient solution. It sets the stage for the rest of the problem solving cycle, including the analysis, design, implementation, and evaluation phases.
Gathering the Necessary Data
Before finding a solution to a computer science problem, it is essential to gather the necessary data. Whether it’s writing a program or developing an algorithm, data serves as the backbone of any solution. Without proper data collection and analysis, the problem-solving process can become inefficient and ineffective.
The Importance of Data
In computer science, data is crucial for a variety of reasons. First and foremost, it provides the information needed to understand and define the problem at hand. By analyzing the available data, developers and programmers can gain insights into the nature of the problem and determine the most efficient approach for solving it.
Additionally, data allows for the evaluation of potential solutions. By collecting and organizing relevant data, it becomes possible to compare different algorithms or strategies and select the most suitable one. Data also helps in tracking progress and measuring the effectiveness of the chosen solution.
Data Gathering Process
The process of gathering data involves several steps. Firstly, it is necessary to identify the type of data needed for the particular problem. This may include numerical values, textual information, or other types of data. It is important to determine the sources of data and assess their reliability.
Once the required data has been identified, it needs to be collected. This can be done through various methods, such as surveys, experiments, observations, or by accessing existing data sets. The collected data should be properly organized, ensuring its accuracy and validity.
Data cleaning and preprocessing are vital steps in the data gathering process. This involves removing any irrelevant or erroneous data and transforming it into a suitable format for analysis. Properly cleaned and preprocessed data will help in generating reliable and meaningful insights.
Data Analysis and Interpretation
After gathering and preprocessing the data, the next step is data analysis and interpretation. This involves applying various statistical and analytical methods to uncover patterns, trends, and relationships within the data. By analyzing the data, programmers can gain valuable insights that can inform the development of an effective solution.
During the data analysis process, it is crucial to remain objective and unbiased. The analysis should be based on sound reasoning and logical thinking. It is also important to communicate the findings effectively, using visualizations or summaries to convey the information to stakeholders or fellow developers.
In conclusion, gathering the necessary data is a fundamental step in solving computer science problems. It provides the foundation for understanding the problem, evaluating potential solutions, and tracking progress. By following a systematic and rigorous approach to data gathering and analysis, developers can ensure that their solutions are efficient, effective, and well-informed.
Analyzing the Data
Once you have collected the necessary data, the next step in the problem-solving cycle is to analyze it. Data analysis is a crucial component of computer science, as it helps us understand the problem at hand and develop effective solutions.
To analyze the data, you need to break it down into manageable pieces and examine each piece closely. This process involves identifying patterns, trends, and outliers that may be present in the data. By doing so, you can gain insights into the problem and make informed decisions about the best course of action.
There are several techniques and tools available for data analysis in computer science. Some common methods include statistical analysis, data visualization, and machine learning algorithms. Each approach has its own strengths and limitations, so it’s essential to choose the most appropriate method for the problem you are solving.
Statistical Analysis
Statistical analysis involves using mathematical models and techniques to analyze data. It helps in identifying correlations, distributions, and other statistical properties of the data. By applying statistical tests, you can determine the significance and validity of your findings.
Data Visualization
Data visualization is the process of presenting data in a visual format, such as charts, graphs, or maps. It allows for a better understanding of complex data sets and facilitates the communication of findings. Through data visualization, patterns and trends can become more apparent, making it easier to derive meaningful insights.
Machine Learning Algorithms
Machine learning algorithms are powerful tools for analyzing large and complex data sets. These algorithms can automatically detect patterns and relationships in the data, leading to the development of predictive models and solutions. By training the algorithm on a labeled dataset, it can learn from the data and make accurate predictions or classifications.
In conclusion, analyzing the data is a critical step in the problem-solving cycle in computer science. It helps us gain a deeper understanding of the problem and develop effective solutions. Whether through statistical analysis, data visualization, or machine learning algorithms, data analysis plays a vital role in transforming raw data into actionable insights.
Exploring Possible Solutions
Once you have gathered data and completed the analysis, the next step in the problem-solving cycle is to explore possible solutions. This is where the true power of computer science comes into play. With the use of algorithms and the application of scientific principles, computer scientists can develop innovative solutions to complex problems.
During this stage, it is important to consider a variety of potential solutions. This involves brainstorming different ideas and considering their feasibility and potential effectiveness. It may be helpful to consult with colleagues or experts in the field to gather additional insights and perspectives.
Developing an Algorithm
One key aspect of exploring possible solutions is the development of an algorithm. An algorithm is a step-by-step set of instructions that outlines a specific process or procedure. In the context of problem solving in computer science, an algorithm provides a clear roadmap for implementing a solution.
The development of an algorithm requires careful thought and consideration. It is important to break down the problem into smaller, manageable steps and clearly define the inputs and outputs of each step. This allows for the creation of a logical and efficient solution.
Evaluating the Solutions
Once you have developed potential solutions and corresponding algorithms, the next step is to evaluate them. This involves analyzing each solution to determine its strengths, weaknesses, and potential impact. Consider factors such as efficiency, scalability, and resource requirements.
It may be helpful to conduct experiments or simulations to further assess the effectiveness of each solution. This can provide valuable insights and data to support the decision-making process.
Ultimately, the goal of exploring possible solutions is to find the most effective and efficient solution to the problem at hand. By leveraging the power of data, analysis, algorithms, and scientific principles, computer scientists can develop innovative solutions that drive progress and solve complex problems in the world of technology.
Evaluating the Options
Once you have identified potential solutions and algorithms for a problem, the next step in the problem-solving cycle in computer science is to evaluate the options. This evaluation process involves analyzing the potential solutions and algorithms based on various criteria to determine the best course of action.
Consider the Problem
Before evaluating the options, it is important to take a step back and consider the problem at hand. Understand the requirements, constraints, and desired outcomes of the problem. This analysis will help guide the evaluation process.
Analyze the Options
Next, it is crucial to analyze each solution or algorithm option individually. Look at factors such as efficiency, accuracy, ease of implementation, and scalability. Consider whether the solution or algorithm meets the specific requirements of the problem, and if it can be applied to related problems in the future.
Additionally, evaluate the potential risks and drawbacks associated with each option. Consider factors such as cost, time, and resources required for implementation. Assess any potential limitations or trade-offs that may impact the overall effectiveness of the solution or algorithm.
Select the Best Option
Based on the analysis, select the best option that aligns with the specific problem-solving goals. This may involve prioritizing certain criteria or making compromises based on the limitations identified during the evaluation process.
Remember that the best option may not always be the most technically complex or advanced solution. Consider the practicality and feasibility of implementation, as well as the potential impact on the overall system or project.
In conclusion, evaluating the options is a critical step in the problem-solving cycle in computer science. By carefully analyzing the potential solutions and algorithms, considering the problem requirements, and considering the limitations and trade-offs, you can select the best option to solve the problem at hand.
Making a Decision
Decision-making is a critical component in the problem-solving process in computer science. Once you have analyzed the problem, identified the relevant data, and generated a potential solution, it is important to evaluate your options and choose the best course of action.
Consider All Factors
When making a decision, it is important to consider all relevant factors. This includes evaluating the potential benefits and drawbacks of each option, as well as understanding any constraints or limitations that may impact your choice.
In computer science, this may involve analyzing the efficiency of different algorithms or considering the scalability of a proposed solution. It is important to take into account both the short-term and long-term impacts of your decision.
Weigh the Options
Once you have considered all the factors, it is important to weigh the options and determine the best approach. This may involve assigning weights or priorities to different factors based on their importance.
Using techniques such as decision matrices or cost-benefit analysis can help you systematically compare and evaluate different options. By quantifying and assessing the potential risks and rewards, you can make a more informed decision.
Remember: Decision-making in computer science is not purely subjective or based on personal preference. It is crucial to use analytical and logical thinking to select the most optimal solution.
In conclusion, making a decision is a crucial step in the problem-solving process in computer science. By considering all relevant factors and weighing the options using logical analysis, you can choose the best possible solution to a given problem.
Implementing the Solution
Once the problem has been analyzed and a solution has been proposed, the next step in the problem-solving cycle in computer science is implementing the solution. This involves turning the proposed solution into an actual computer program or algorithm that can solve the problem.
In order to implement the solution, computer science professionals need to have a strong understanding of various programming languages and data structures. They need to be able to write code that can manipulate and process data in order to solve the problem at hand.
During the implementation phase, the proposed solution is translated into a series of steps or instructions that a computer can understand and execute. This involves breaking down the problem into smaller sub-problems and designing algorithms to solve each sub-problem.
Computer scientists also need to consider the efficiency of their solution during the implementation phase. They need to ensure that the algorithm they design is able to handle large amounts of data and solve the problem in a reasonable amount of time. This often requires optimization techniques and careful consideration of the data structures used.
Once the code has been written and the algorithm has been implemented, it is important to test and debug the solution. This involves running test cases and checking the output to ensure that the program is working correctly. If any errors or bugs are found, they need to be fixed before the solution can be considered complete.
In conclusion, implementing the solution is a crucial step in the problem-solving cycle in computer science. It requires strong programming skills and a deep understanding of algorithms and data structures. By carefully designing and implementing the solution, computer scientists can solve problems efficiently and effectively.
Testing and Debugging
In computer science, testing and debugging are critical steps in the problem-solving cycle. Testing helps ensure that a program or algorithm is functioning correctly, while debugging analyzes and resolves any issues or bugs that may arise.
Testing involves running a program with specific input data to evaluate its output. This process helps verify that the program produces the expected results and handles different scenarios correctly. It is important to test both the normal and edge cases to ensure the program’s reliability.
Debugging is the process of identifying and fixing errors or bugs in a program. When a program does not produce the expected results or crashes, it is necessary to go through the code to find and fix the problem. This can involve analyzing the program’s logic, checking for syntax errors, and using debugging tools to trace the flow of data and identify the source of the issue.
Data analysis plays a crucial role in both testing and debugging. It helps to identify patterns, anomalies, or inconsistencies in the program’s behavior. By analyzing the data, developers can gain insights into potential issues and make informed decisions on how to improve the program’s performance.
In conclusion, testing and debugging are integral parts of the problem-solving cycle in computer science. Through testing and data analysis, developers can verify the correctness of their programs and identify and resolve any issues that may arise. This ensures that the algorithms and programs developed in computer science are robust, reliable, and efficient.
Iterating for Improvement
In computer science, problem solving often involves iterating through multiple cycles of analysis, solution development, and evaluation. This iterative process allows for continuous improvement in finding the most effective solution to a given problem.
The problem solving cycle starts with problem analysis, where the specific problem is identified and its requirements are understood. This step involves examining the problem from various angles and gathering all relevant information.
Once the problem is properly understood, the next step is to develop an algorithm or a step-by-step plan to solve the problem. This algorithm is a set of instructions that, when followed correctly, will lead to the solution.
After the algorithm is developed, it is implemented in a computer program. This step involves translating the algorithm into a programming language that a computer can understand and execute.
Once the program is implemented, it is then tested and evaluated to ensure that it produces the correct solution. This evaluation step is crucial in identifying any errors or inefficiencies in the program and allows for further improvement.
If any issues or problems are found during testing, the cycle iterates, starting from problem analysis again. This iterative process allows for refinement and improvement of the solution until the desired results are achieved.
Iterating for improvement is a fundamental concept in computer science problem solving. By continually analyzing, developing, and evaluating solutions, computer scientists are able to find the most optimal and efficient approaches to solving problems.
Documenting the Process
Documenting the problem-solving process in computer science is an essential step to ensure that the cycle is repeated successfully. The process involves gathering information, analyzing the problem, and designing a solution.
During the analysis phase, it is crucial to identify the specific problem at hand and break it down into smaller components. This allows for a more targeted approach to finding the solution. Additionally, analyzing the data involved in the problem can provide valuable insights and help in designing an effective solution.
Once the analysis is complete, it is important to document the findings. This documentation can take various forms, such as written reports, diagrams, or even code comments. The goal is to create a record that captures the problem, the analysis, and the proposed solution.
Documenting the process serves several purposes. Firstly, it allows for easy communication and collaboration between team members or future developers. By documenting the problem, analysis, and solution, others can easily understand the thought process behind the solution and potentially build upon it.
Secondly, documenting the process provides an opportunity for reflection and improvement. By reviewing the documentation, developers can identify areas where the problem-solving cycle can be strengthened or optimized. This continuous improvement is crucial in the field of computer science, as new challenges and technologies emerge rapidly.
In conclusion, documenting the problem-solving process is an integral part of the computer science cycle. It allows for effective communication, collaboration, and reflection on the solutions devised. By taking the time to document the process, developers can ensure a more efficient and successful problem-solving experience.
Communicating the Solution
Once the problem solving cycle is complete, it is important to effectively communicate the solution. This involves explaining the analysis, data, and steps taken to arrive at the solution.
Analyzing the Problem
During the problem solving cycle, a thorough analysis of the problem is conducted. This includes understanding the problem statement, gathering relevant data, and identifying any constraints or limitations. It is important to clearly communicate this analysis to ensure that others understand the problem at hand.
Presenting the Solution
The next step in communicating the solution is presenting the actual solution. This should include a detailed explanation of the steps taken to solve the problem, as well as any algorithms or data structures used. It is important to provide clear and concise descriptions of the solution, so that others can understand and reproduce the results.
Overall, effective communication of the solution in computer science is essential to ensure that others can understand and replicate the problem solving process. By clearly explaining the analysis, data, and steps taken, the solution can be communicated in a way that promotes understanding and collaboration within the field of computer science.
Reflecting and Learning
Reflecting and learning are crucial steps in the problem solving cycle in computer science. Once a problem has been solved, it is essential to reflect on the entire process and learn from the experience. This allows for continuous improvement and growth in the field of computer science.
During the reflecting phase, one must analyze and evaluate the problem solving process. This involves reviewing the initial problem statement, understanding the constraints and requirements, and assessing the effectiveness of the chosen algorithm and solution. It is important to consider the efficiency and accuracy of the solution, as well as any potential limitations or areas for optimization.
By reflecting on the problem solving cycle, computer scientists can gain valuable insights into their own strengths and weaknesses. They can identify areas where they excelled and areas where improvement is needed. This self-analysis helps in honing problem solving skills and becoming a better problem solver.
Learning from Mistakes
Mistakes are an integral part of the problem solving cycle, and they provide valuable learning opportunities. When a problem is not successfully solved, it is essential to analyze the reasons behind the failure and learn from them. This involves identifying errors in the algorithm or solution, understanding the underlying concepts or principles that were misunderstood, and finding alternative approaches or strategies.
Failure should not be seen as a setback, but rather as an opportunity for growth. By learning from mistakes, computer scientists can improve their problem solving abilities and expand their knowledge and understanding of computer science. It is through these failures and the subsequent learning process that new ideas and innovations are often born.
Continuous Improvement
Reflecting and learning should not be limited to individual problem solving experiences, but should be an ongoing practice. As computer science is a rapidly evolving field, it is crucial to stay updated with new technologies, algorithms, and problem solving techniques. Continuous learning and improvement contribute to staying competitive and relevant in the field.
Computer scientists can engage in continuous improvement by seeking feedback from peers, participating in research and development activities, attending conferences and workshops, and actively seeking new challenges and problem solving opportunities. This dedication to learning and improvement ensures that one’s problem solving skills remain sharp and effective.
In conclusion, reflecting and learning are integral parts of the problem solving cycle in computer science. They enable computer scientists to refine their problem solving abilities, learn from mistakes, and continuously improve their skills and knowledge. By embracing these steps, computer scientists can stay at the forefront of the ever-changing world of computer science and contribute to its advancements.
Applying Problem Solving in Real Life
In computer science, problem solving is not limited to the realm of programming and algorithms. It is a skill that can be applied to various aspects of our daily lives, helping us to solve problems efficiently and effectively. By using the problem-solving cycle and applying the principles of analysis, data, solution, algorithm, and cycle, we can tackle real-life challenges with confidence and success.
The first step in problem-solving is to analyze the problem at hand. This involves breaking it down into smaller, more manageable parts and identifying the key issues or goals. By understanding the problem thoroughly, we can gain insights into its root causes and potential solutions.
For example, let’s say you’re facing a recurring issue in your daily commute – traffic congestion. By analyzing the problem, you may discover that the main causes are a lack of alternative routes and a lack of communication between drivers. This analysis helps you identify potential solutions such as using navigation apps to find alternate routes or promoting carpooling to reduce the number of vehicles on the road.
Gathering and Analyzing Data
Once we have identified the problem, it is important to gather relevant data to support our analysis. This may involve conducting surveys, collecting statistics, or reviewing existing research. By gathering data, we can make informed decisions and prioritize potential solutions based on their impact and feasibility.
Continuing with the traffic congestion example, you may gather data on the average commute time, the number of vehicles on the road, and the impact of carpooling on congestion levels. This data can help you analyze the problem more accurately and determine the most effective solutions.
Generating and Evaluating Solutions
After analyzing the problem and gathering data, the next step is to generate potential solutions. This can be done through brainstorming, researching best practices, or seeking input from experts. It is important to consider multiple options and think outside the box to find innovative and effective solutions.
For our traffic congestion problem, potential solutions can include implementing a smart traffic management system that optimizes traffic flow or investing in public transportation to incentivize people to leave their cars at home. By evaluating each solution’s potential impact, cost, and feasibility, you can make an informed decision on the best course of action.
Implementing and Iterating
Once a solution has been chosen, it is time to implement it in real life. This may involve developing a plan, allocating resources, and executing the solution. It is important to monitor the progress and collect feedback to learn from the implementation and make necessary adjustments.
For example, if the chosen solution to address traffic congestion is implementing a smart traffic management system, you would work with engineers and transportation authorities to develop and deploy the system. Regular evaluation and iteration of the system’s performance would ensure that it is effective and making a positive impact on reducing congestion.
By applying the problem-solving cycle derived from computer science to real-life situations, we can approach challenges with a systematic and analytical mindset. This can help us make better decisions, improve our problem-solving skills, and ultimately achieve more efficient and effective solutions.
Building Problem Solving Skills
In the field of computer science, problem-solving is a fundamental skill that is crucial for success. Whether you are a computer scientist, programmer, or student, developing strong problem-solving skills will greatly benefit your work and studies. It allows you to approach challenges with a logical and systematic approach, leading to efficient and effective problem resolution.
The Problem Solving Cycle
Problem-solving in computer science involves a cyclical process known as the problem-solving cycle. This cycle consists of several stages, including problem identification, data analysis, solution development, implementation, and evaluation. By following this cycle, computer scientists are able to tackle complex problems and arrive at optimal solutions.
Importance of Data Analysis
Data analysis is a critical step in the problem-solving cycle. It involves gathering and examining relevant data to gain insights and identify patterns that can inform the development of a solution. Without proper data analysis, computer scientists may overlook important information or make unfounded assumptions, leading to subpar solutions.
To effectively analyze data, computer scientists can employ various techniques such as data visualization, statistical analysis, and machine learning algorithms. These tools enable them to extract meaningful information from large datasets and make informed decisions during the problem-solving process.
Developing Effective Solutions
Developing effective solutions requires creativity, critical thinking, and logical reasoning. Computer scientists must evaluate multiple approaches, consider various factors, and assess the feasibility of different solutions. They should also consider potential limitations and trade-offs to ensure that the chosen solution addresses the problem effectively.
Furthermore, collaboration and communication skills are vital when building problem-solving skills. Computer scientists often work in teams and need to effectively communicate their ideas, propose solutions, and address any challenges that arise during the problem-solving process. Strong interpersonal skills facilitate collaboration and enhance problem-solving outcomes.
- Mastering programming languages and algorithms
- Staying updated with technological advancements in the field
- Practicing problem solving through coding challenges and projects
- Seeking feedback and learning from mistakes
- Continuing to learn and improve problem-solving skills
By following these strategies, individuals can strengthen their problem-solving abilities and become more effective computer scientists or programmers. Problem-solving is an essential skill in computer science and plays a central role in driving innovation and advancing the field.
Questions and answers:
What is the problem solving cycle in computer science.
The problem solving cycle in computer science refers to a systematic approach that programmers use to solve problems. It involves several steps, including problem definition, algorithm design, implementation, testing, and debugging.
How important is the problem solving cycle in computer science?
The problem solving cycle is extremely important in computer science as it allows programmers to effectively tackle complex problems and develop efficient solutions. It helps in organizing the thought process and ensures that the problem is approached in a logical and systematic manner.
What are the steps involved in the problem solving cycle?
The problem solving cycle typically consists of the following steps: problem definition and analysis, algorithm design, implementation, testing, and debugging. These steps are repeated as necessary until a satisfactory solution is achieved.
Can you explain the problem definition and analysis step in the problem solving cycle?
During the problem definition and analysis step, the programmer identifies and thoroughly understands the problem that needs to be solved. This involves analyzing the requirements, constraints, and possible inputs and outputs. It is important to have a clear understanding of the problem before proceeding to the next steps.
Why is testing and debugging an important step in the problem solving cycle?
Testing and debugging are important steps in the problem solving cycle because they ensure that the implemented solution functions as intended and is free from errors. Through testing, the programmer can identify and fix any issues or bugs in the code, thereby improving the quality and reliability of the solution.
What is the problem-solving cycle in computer science?
The problem-solving cycle in computer science refers to the systematic approach that computer scientists use to solve problems. It involves various steps, including problem analysis, algorithm design, coding, testing, and debugging.
Related posts:
- The Stages of the Problem Solving Cycle in Cognitive Psychology – Understanding, Planning, Execution, Evaluation, and Reflection
- A Comprehensive Guide to the Problem Solving Cycle in Psychology – Strategies, Techniques, and Applications
- The Step-by-Step Problem Solving Cycle for Effective Solutions
- The Importance of Implementing the Problem Solving Cycle in Education to Foster Critical Thinking and Problem-Solving Skills in Students
- The Importance of the Problem Solving Cycle in Business Studies – Strategies for Success
- The Comprehensive Guide to the Problem Solving Cycle in PDF Format
- A Comprehensive Guide on the Problem Solving Cycle – Step-by-Step Approach with Real-Life Example
- The Seven Essential Steps of the Problem Solving Cycle
What Is Problem Solving? How Software Engineers Approach Complex Challenges

From debugging an existing system to designing an entirely new software application, a day in the life of a software engineer is filled with various challenges and complexities. The one skill that glues these disparate tasks together and makes them manageable? Problem solving .
Throughout this blog post, we’ll explore why problem-solving skills are so critical for software engineers, delve into the techniques they use to address complex challenges, and discuss how hiring managers can identify these skills during the hiring process.
What Is Problem Solving?
But what exactly is problem solving in the context of software engineering? How does it work, and why is it so important?
Problem solving, in the simplest terms, is the process of identifying a problem, analyzing it, and finding the most effective solution to overcome it. For software engineers, this process is deeply embedded in their daily workflow. It could be something as simple as figuring out why a piece of code isn’t working as expected, or something as complex as designing the architecture for a new software system.
In a world where technology is evolving at a blistering pace, the complexity and volume of problems that software engineers face are also growing. As such, the ability to tackle these issues head-on and find innovative solutions is not only a handy skill — it’s a necessity.
The Importance of Problem-Solving Skills for Software Engineers
Problem-solving isn’t just another ability that software engineers pull out of their toolkits when they encounter a bug or a system failure. It’s a constant, ongoing process that’s intrinsic to every aspect of their work. Let’s break down why this skill is so critical.
Driving Development Forward
Without problem solving, software development would hit a standstill. Every new feature, every optimization, and every bug fix is a problem that needs solving. Whether it’s a performance issue that needs diagnosing or a user interface that needs improving, the capacity to tackle and solve these problems is what keeps the wheels of development turning.
It’s estimated that 60% of software development lifecycle costs are related to maintenance tasks, including debugging and problem solving. This highlights how pivotal this skill is to the everyday functioning and advancement of software systems.
Innovation and Optimization
The importance of problem solving isn’t confined to reactive scenarios; it also plays a major role in proactive, innovative initiatives . Software engineers often need to think outside the box to come up with creative solutions, whether it’s optimizing an algorithm to run faster or designing a new feature to meet customer needs. These are all forms of problem solving.
Consider the development of the modern smartphone. It wasn’t born out of a pre-existing issue but was a solution to a problem people didn’t realize they had — a device that combined communication, entertainment, and productivity into one handheld tool.
Increasing Efficiency and Productivity
Good problem-solving skills can save a lot of time and resources. Effective problem-solvers are adept at dissecting an issue to understand its root cause, thus reducing the time spent on trial and error. This efficiency means projects move faster, releases happen sooner, and businesses stay ahead of their competition.
Improving Software Quality
Problem solving also plays a significant role in enhancing the quality of the end product. By tackling the root causes of bugs and system failures, software engineers can deliver reliable, high-performing software. This is critical because, according to the Consortium for Information and Software Quality, poor quality software in the U.S. in 2022 cost at least $2.41 trillion in operational issues, wasted developer time, and other related problems.
Problem-Solving Techniques in Software Engineering
So how do software engineers go about tackling these complex challenges? Let’s explore some of the key problem-solving techniques, theories, and processes they commonly use.
Decomposition
Breaking down a problem into smaller, manageable parts is one of the first steps in the problem-solving process. It’s like dealing with a complicated puzzle. You don’t try to solve it all at once. Instead, you separate the pieces, group them based on similarities, and then start working on the smaller sets. This method allows software engineers to handle complex issues without being overwhelmed and makes it easier to identify where things might be going wrong.
Abstraction
In the realm of software engineering, abstraction means focusing on the necessary information only and ignoring irrelevant details. It is a way of simplifying complex systems to make them easier to understand and manage. For instance, a software engineer might ignore the details of how a database works to focus on the information it holds and how to retrieve or modify that information.
Algorithmic Thinking
At its core, software engineering is about creating algorithms — step-by-step procedures to solve a problem or accomplish a goal. Algorithmic thinking involves conceiving and expressing these procedures clearly and accurately and viewing every problem through an algorithmic lens. A well-designed algorithm not only solves the problem at hand but also does so efficiently, saving computational resources.
Parallel Thinking
Parallel thinking is a structured process where team members think in the same direction at the same time, allowing for more organized discussion and collaboration. It’s an approach popularized by Edward de Bono with the “ Six Thinking Hats ” technique, where each “hat” represents a different style of thinking.
In the context of software engineering, parallel thinking can be highly effective for problem solving. For instance, when dealing with a complex issue, the team can use the “White Hat” to focus solely on the data and facts about the problem, then the “Black Hat” to consider potential problems with a proposed solution, and so on. This structured approach can lead to more comprehensive analysis and more effective solutions, and it ensures that everyone’s perspectives are considered.
This is the process of identifying and fixing errors in code . Debugging involves carefully reviewing the code, reproducing and analyzing the error, and then making necessary modifications to rectify the problem. It’s a key part of maintaining and improving software quality.
Testing and Validation
Testing is an essential part of problem solving in software engineering. Engineers use a variety of tests to verify that their code works as expected and to uncover any potential issues. These range from unit tests that check individual components of the code to integration tests that ensure the pieces work well together. Validation, on the other hand, ensures that the solution not only works but also fulfills the intended requirements and objectives.
Explore verified tech roles & skills.
The definitive directory of tech roles, backed by machine learning and skills intelligence.
Explore all roles
Evaluating Problem-Solving Skills
We’ve examined the importance of problem-solving in the work of a software engineer and explored various techniques software engineers employ to approach complex challenges. Now, let’s delve into how hiring teams can identify and evaluate problem-solving skills during the hiring process.
Recognizing Problem-Solving Skills in Candidates
How can you tell if a candidate is a good problem solver? Look for these indicators:
- Previous Experience: A history of dealing with complex, challenging projects is often a good sign. Ask the candidate to discuss a difficult problem they faced in a previous role and how they solved it.
- Problem-Solving Questions: During interviews, pose hypothetical scenarios or present real problems your company has faced. Ask candidates to explain how they would tackle these issues. You’re not just looking for a correct solution but the thought process that led them there.
- Technical Tests: Coding challenges and other technical tests can provide insight into a candidate’s problem-solving abilities. Consider leveraging a platform for assessing these skills in a realistic, job-related context.
Assessing Problem-Solving Skills
Once you’ve identified potential problem solvers, here are a few ways you can assess their skills:
- Solution Effectiveness: Did the candidate solve the problem? How efficient and effective is their solution?
- Approach and Process: Go beyond whether or not they solved the problem and examine how they arrived at their solution. Did they break the problem down into manageable parts? Did they consider different perspectives and possibilities?
- Communication: A good problem solver can explain their thought process clearly. Can the candidate effectively communicate how they arrived at their solution and why they chose it?
- Adaptability: Problem-solving often involves a degree of trial and error. How does the candidate handle roadblocks? Do they adapt their approach based on new information or feedback?
Hiring managers play a crucial role in identifying and fostering problem-solving skills within their teams. By focusing on these abilities during the hiring process, companies can build teams that are more capable, innovative, and resilient.
Key Takeaways
As you can see, problem solving plays a pivotal role in software engineering. Far from being an occasional requirement, it is the lifeblood that drives development forward, catalyzes innovation, and delivers of quality software.
By leveraging problem-solving techniques, software engineers employ a powerful suite of strategies to overcome complex challenges. But mastering these techniques isn’t simple feat. It requires a learning mindset, regular practice, collaboration, reflective thinking, resilience, and a commitment to staying updated with industry trends.
For hiring managers and team leads, recognizing these skills and fostering a culture that values and nurtures problem solving is key. It’s this emphasis on problem solving that can differentiate an average team from a high-performing one and an ordinary product from an industry-leading one.
At the end of the day, software engineering is fundamentally about solving problems — problems that matter to businesses, to users, and to the wider society. And it’s the proficient problem solvers who stand at the forefront of this dynamic field, turning challenges into opportunities, and ideas into reality.
This article was written with the help of AI. Can you tell which parts?
Get started with HackerRank
Over 2,500 companies and 40% of developers worldwide use HackerRank to hire tech talent and sharpen their skills.
Recommended topics
- Hire Developers
- Problem Solving

Computer Science
- Quantitative Finance
Take a guided, problem-solving based approach to learning Computer Science. These compilations provide unique perspectives and applications you won't find anywhere else.
Computer Science Fundamentals
What's inside.
- Tools of Computer Science
- Computational Problem Solving
- Algorithmic Thinking
Algorithm Fundamentals
- Building Blocks
- Array Algorithms
- The Speed of Algorithms
- Stable Matching
Programming with Python
- Introduction
- String Manipulation
- Loops, Functions and Arguments
Community Wiki
Browse through thousands of Computer Science wikis written by our community of experts.
Types and Data Structures
- Abstract Data Types
- Array (ADT)
- Double Ended Queues
- Associative Arrays
- Priority Queues
- Array (Data Structure)
- Disjoint-set Data Structure (Union-Find)
- Dynamic Array
- Linked List
- Unrolled Linked List
- Hash Tables
- Bloom Filter
- Cuckoo Filter
- Merkle Tree
- Recursive Backtracking
- Fenwick Tree
- Binary Search Trees
- Red-Black Tree
- Scapegoat Tree
- Binary Heap
- Binomial Heap
- Fibonacci Heap
- Pairing Heap
- Graph implementation and representation
- Adjacency Matrix
- Spanning Trees
- Social Networks
- Kruskal's Algorithm
- Regular Expressions
- Divide and Conquer
- Greedy Algorithms
- Randomized Algorithms
- Complexity Theory
- Big O Notation
- Master Theorem
- Amortized Analysis
- Complexity Classes
- P versus NP
- Dynamic Programming
- Backpack Problem
- Egg Dropping
- Fast Fibonacci Transform
- Karatsuba Algorithm
- Sorting Algorithms
- Insertion Sort
- Bubble Sort
- Counting Sort
- Median-finding Algorithm
- Binary Search
- Depth-First Search (DFS)
- Breadth-First Search (BFS)
- Shortest Path Algorithms
- Dijkstra's Shortest Path Algorithm
- Bellman-Ford Algorithm
- Floyd-Warshall Algorithm
- Johnson's Algorithm
- Matching (Graph Theory)
- Matching Algorithms (Graph Theory)
- Flow Network
- Max-flow Min-cut Algorithm
- Ford-Fulkerson Algorithm
- Edmonds-Karp Algorithm
- Shunting Yard Algorithm
- Rabin-Karp Algorithm
- Knuth-Morris-Pratt Algorithm
- Basic Shapes, Polygons, Trigonometry
- Convex Hull
- Finite State Machines
- Turing Machines
- Halting Problem
- Kolmogorov Complexity
- Traveling Salesperson Problem
- Pushdown Automata
- Regular Languages
- Context Free Grammars
- Context Free Languages
- Signals and Systems
- Linear Time Invariant Systems
- Predicting System Behavior
Programming Languages
- Subroutines
- List comprehension
- Primality Testing
- Pattern matching
- Logic Gates
- Control Flow Statements
- Object-Oriented Programming
- Classes (OOP)
- Methods (OOP)
Cryptography and Simulations
- Caesar Cipher
- Vigenère Cipher
- RSA Encryption
- Enigma Machine
- Diffie-Hellman
- Knapsack Cryptosystem
- Secure Hash Algorithms
- Entropy (Information Theory)
- Huffman Code
- Error correcting codes
- Symmetric Ciphers
- Inverse Transform Sampling
- Monte-Carlo Simulation
- Genetic Algorithms
- Programming Blackjack
- Machine Learning
- Supervised Learning
- Unsupervised Learning
- Feature Vector
- Naive Bayes Classifier
- K-nearest Neighbors
- Support Vector Machines
- Principal Component Analysis
- Ridge Regression
- k-Means Clustering
- Markov Chains
- Hidden Markov Models
- Gaussian Mixture Model
- Collaborative Filtering
- Artificial Neural Network
- Feedforward Neural Networks
- Backpropagation
- Recurrent Neural Network
Problem Loading...
Note Loading...
Set Loading...
- Computers & Technology
- Computer Science
Buy new: $92.68 $92.68 FREE delivery: April 8 - 12 Ships from: EMC_STORE Sold by: EMC_STORE
Buy used: $56.76, other sellers on amazon.
Download the free Kindle app and start reading Kindle books instantly on your smartphone, tablet, or computer - no Kindle device required .
Read instantly on your browser with Kindle for Web.
Using your mobile phone camera - scan the code below and download the Kindle app.

Image Unavailable

- To view this video download Flash Player

Follow the author

COMPUTER-BASED PROBLEM SOLVING PROCESS
Purchase options and add-ons.
One side-effect of having made great leaps in computing over the last few decades, is the resulting over-abundance in software tools created to solve the diverse problems. Problem solving with computers has, in consequence, become more demanding; instead of focusing on the problem when conceptualizing strategies to solve them, users are side-tracked by the pursuit of even more programming tools (as available).
Computer-Based Problem Solving Process is a work intended to offer a systematic treatment to the theory and practice of designing, implementing, and using software tools during the problem solving process. This method is obtained by enabling computer systems to be more Intuitive with human logic rather than machine logic. Instead of software dedicated to computer experts, the author advocates an approach dedicated to computer users in general. This approach does not require users to have an advanced computer education, though it does advocate a deeper education of the computer user in his or her problem domain logic.
This book is intended for system software teachers, designers and implementers of various aspects of system software, as well as readers who have made computers a part of their day-today problem solving.
- ISBN-10 9814663735
- ISBN-13 978-9814663731
- Publisher World Scientific Pub Co Inc
- Publication date March 20, 2015
- Language English
- Dimensions 6.25 x 1 x 9.25 inches
- Print length 344 pages
- See all details

Editorial Reviews
From the back cover, product details.
- Publisher : World Scientific Pub Co Inc (March 20, 2015)
- Language : English
- Hardcover : 344 pages
- ISBN-10 : 9814663735
- ISBN-13 : 978-9814663731
- Item Weight : 1.45 pounds
- Dimensions : 6.25 x 1 x 9.25 inches
- #1,323 in Computer Algorithms
- #1,716 in Artificial Intelligence Expert Systems
- #2,296 in Natural Language Processing (Books)
About the author
Discover more of the author’s books, see similar authors, read author blogs and more
Customer reviews
Customer Reviews, including Product Star Ratings help customers to learn more about the product and decide whether it is the right product for them.
To calculate the overall star rating and percentage breakdown by star, we don’t use a simple average. Instead, our system considers things like how recent a review is and if the reviewer bought the item on Amazon. It also analyzed reviews to verify trustworthiness.
No customer reviews
- Amazon Newsletter
- About Amazon
- Accessibility
- Sustainability
- Press Center
- Investor Relations
- Amazon Devices
- Amazon Science
- Start Selling with Amazon
- Sell apps on Amazon
- Supply to Amazon
- Protect & Build Your Brand
- Become an Affiliate
- Become a Delivery Driver
- Start a Package Delivery Business
- Advertise Your Products
- Self-Publish with Us
- Host an Amazon Hub
- › See More Ways to Make Money
- Amazon Visa
- Amazon Store Card
- Amazon Secured Card
- Amazon Business Card
- Shop with Points
- Credit Card Marketplace
- Reload Your Balance
- Amazon Currency Converter
- Your Account
- Your Orders
- Shipping Rates & Policies
- Amazon Prime
- Returns & Replacements
- Manage Your Content and Devices
- Recalls and Product Safety Alerts
- Conditions of Use
- Privacy Notice
- Consumer Health Data Privacy Disclosure
- Your Ads Privacy Choices
ORIGINAL RESEARCH article
Analysis of process data of pisa 2012 computer-based problem solving: application of the modified multilevel mixture irt model.

- 1 Faculty of Psychology, Beijing Normal University, Beijing, China
- 2 Beijing Key Laboratory of Applied Experimental Psychology, Faculty of Psychology, National Demonstration Center for Experimental Psychology Education, Beijing Normal University, Beijing, China
- 3 Collaborative Innovation Center of Assessment Toward Basic Education Quality, Beijing Normal University, Beijing, China
- 4 Educational Supervision and Quality Assessment Research Center, Beijing Academy of Educational Sciences, Beijing, China
Computer-based assessments provide new insights into cognitive processes related to task completion that cannot be easily observed using paper-based instruments. In particular, such new insights may be revealed by time-tamped actions, which are recorded as computer log-files in the assessments. These actions, nested in individual level, are logically interconnected. This interdependency can be modeled straightforwardly in a multi-level framework. This study draws on process data recorded in one of complex problem-solving tasks (Traffic CP007Q02) in Program for International Student Assessment (PISA) 2012 and proposes a modified Multilevel Mixture IRT model (MMixIRT) to explore the problem-solving strategies. It was found that the model can not only explore whether the latent classes differ in their response strategies at the process level, but provide ability estimates at both the process level and the student level. The two level abilities are different across latent classes, and they are related to operational variables such as the number of resets or clicks. The proposed method may allow for better exploration of students' specific strategies for solving a problem, and the strengths and weaknesses of the strategies. Such findings may be further used to design targeted instructional interventions.
Introduction
The problem-solving competence is defined as the capacity to engage in cognitive processing to understand and resolve problem situations where a solution is not immediately obvious. It includes the willingness to engage in these situations in order to achieve one's potential as a constructive and reflective citizen ( OECD, 2014 ; Kurniati and Annizar, 2017 ). Problem solving can be conceptualized as a sequential process where the problem solver must understand the problem, devise a plan, carry out the plan, and monitor the progress in relation to the goal ( Garofalo and Lester, 1985 ; OECD, 2013 ). These problem-solving skills are key to success in all pursuits, and they can be developed in school through curricular subjects. Therefore, it is no surprise that the problem-solving competency is increasingly becoming the focus of many testing programs worldwide.
Advances in technology have expanded opportunities for educational measurement. Computer-based assessments, such as simulation-, scenario-, and game-based assessments, constantly change item design, item delivery, and data collection ( DiCerbo and Behrens, 2012 ; Mislevy et al., 2014 ). These assessments usually provide an interactive environment in which students can solve a problem through choosing among a set of available actions and taking one or more steps to complete a task. All student actions are automatically recorded in system logs as coded and time-stamped strings ( Kerr et al., 2011 ). These strings can be used for instant feedback to students, or for diagnostic and scoring purposes at a later time ( DiCerbo and Behrens, 2012 ). And they are called process data. For example, the problem solving assessment of PISA 2012, which is computer-based, used simulated real-life problem situations, such as a malfunctioning electronic device, to analyze students' reasoning skills, problem-solving ability, and problem-solving strategies. The computer-based assessment of problem solving not only ascertains whether students produce correct responses for their items, but also records a large amount of process data on answering these items. These data make it possible to understand students' strategies to the solution. So far, to evaluate students' higher order thinking, more and more large-scale assessments of problem solving become computer-based.
Recent research has focused on characterizing and scoring process data and using them to measure individual student's abilities. Characterizing process data can be conducted via a variety of approaches, including visualization, clustering, and classification ( Romero and Ventura, 2010 ). DiCerbo et al. (2011) used diagraphs to visualize and analyze sequential process data from assessments. Bergner et al. (2014) used cluster analysis to classify similar behaving groups. Some other researchers used decision trees, neural networks, and Bayesian belief networks (BBNs) ( Romero et al., 2008 ; Desmarais and Baker, 2012 ; Zhu et al., 2016 ), to classify the performance of problem solvers ( Zoanetti, 2010 ) and to predict their success ( Romero et al., 2013 ). Compared to characterizing process data, the research of scoring process data is very limited. Hao et al. (2015) introduced “the editing distance” to score students' behavior sequences based on the process data in a scenario-based task of the National Assessment of Educational Progress (NAEP). Meanwhile, these process data have been used in psychometric studies. Researchers analyzed students' sequential response process data to estimate their ability by combining Markov model and item response theory (IRT) ( Shu et al., 2017 ). It is noteworthy that all these practices have examined process data that describe students' sequential actions to solve a problem.
All the actions, recorded as process level data, which are nested in individual level, are logically interconnected. This interdependency allows a straightforward modeling in a multi-level framework ( Goldstein, 1987 ; Raudenbush and Bryk, 2002 ; Hox, 2010 ). This framework is similar to those used in longitudinal studies, yet with some differences. In longitudinal studies, measurements are typically consistent to show the development pattern of certain traits. For process data, however, actions are typically different within each individual. These successive actions are used to characterizing individuals' problem solving strategies.
It is common in computer-based assessments that a nested data structure exists. To appropriately analyze process data (e.g., time series actions) within a nested structure (e.g., process within individuals), the multi-level IRT model can be modified by allowing process data to be a function of the latent traits at both process and individual levels. It is noteworthy that in the modified model, the concept of “item” in IRT changed to each action in individuals' responses, which was scored based on certain rules.
With respect to the assessment of problem solving competency, the focus of this study is the ability estimate at the student level. We were not concerned with individual's ability reflected from each action at the process level, since the task needs to be completed by taking series actions. Even for individuals with high problem solving ability, the first few actions may not accurately reflect test takers' ability. As a result, more attention was put on the development of ability at the process level because it can reveal students' problem solving strategies. Mixture item response theory (MixIRT) models have been used in describing important effects in assessment, including the differential use of response strategies ( Mislevy and Verhelst, 1990 ; Rost, 1990 ; Bolt et al., 2001 ). The value of MixIRT models lies in that they provide a way of detecting different latent groups which are formed by the dimensionality arising directly from the process data. These groups are substantively useful because they reflect how and why students responded the way they did.
In this study, we incorporated the multilevel structure into a mixture IRT model and used the modified multilevel mixture IRT (MMixIRT) model to detect and compare the latent groups in the data that have differential problem solving strategies. The advantage of this approach is the usage of latent groups. Although they are not immediately observable, these latent groups, which are defined by certain shared response patterns, can help explain process-level performance about how members of one latent group differ from another. The approach proposed in this study was used to estimate abilities both at process and student levels, and classify students into different latent groups according to their response strategies.
The goal of this study is to illustrate steps involved in applying the modified MMixIRT model in a computer-based problem solving assessment then to further present and interpret the results. Specifically, this article focuses on (a) describing and demonstrating the modified MMixIRT model using a task of PISA 2012 problem-solving process data; (b) interpreting the different action patterns; (c) analyzing the correlation between characteristics of different strategies and task performance, as well as some other operational variables such as the number of resets or clicks. All the following analysis was based on one sample data set.
Measurement Material and Dataset
Problem solving item and log data file.
This study illustrates the use of the modified MMixIRT model in analyzing process data through one of the problem-solving tasks in PISA 2012 (Traffic CP007Q02). The task is shown in Figure 1 . In this task, students were given a map and the travel time on each route, and then they were asked to find the quickest route from Diamond to Einsten, which takes 31 min.

Figure 1 . Traffic.
The data are from the task's log file (CBA_cp007q02_logs12_SPSS.SAV, data source: http://www.oecd.org/pisa/data/ ) (an example of log data file is shown in Appendix 1 ). The data file contains four variables associated with the process. The “event” variable refers to the type of event, which may be either system generated (start item, end item) or student generated (e.g., ACER_EVENT, Click, Dblclick). The “time” variable is the event time for this item, given in seconds since the beginning of the assessment, with all click and double-click events included. The “event_value” variable is recorded in two rows, as a click event involves selecting or de-selecting a route of the map. For example, in the eleventh row where the state of the entire map is given, 1 in the sequence means that the route was selected, and 0 means that it was not; the twelfth row records an event involving highlighting, or un-highlighting. A route of the map represents the same click event, and it is in the form “hit_segment name” (The notes on log file data can be downloaded from http://www.oecd.org/pisa/data/ ). All the “click” and “double-click” events represent that a student performs a click action that is not related to select a route. Table 1 shows the label, the route and the correct state of the entire selected routes.

Table 1 . The routes of the map.
The study sample was drawn from PISA 2012 released dataset, consisting of a total of 413 students from 157 American schools who participated in the traffic problem-solving assessment (47.2% as females). The average age of students was 15.80 years ( SD = 0.29 years), ranging from 15.33 to 16.33 years.
For the traffic item response, the total effective sample size under analysis was 406, after excluding seven incomplete responses. For the log file of the process record, there were 15,897 records in the final data file, and the average record number for each student was 39 ( SD = 33), ranging from 1 to 183. The average response time was 672.64 s ( SD = 518.85 s), ranging from 58.30 to 1995.20 s.
The Modified MMixIRT Model for Process Data
Process-level data coding.
In this task log file, “ACER_EVENT” is associated with “click.” However, in this study we only collected the information of ACER_EVENT and deleted the redundant click data. Then, we split and rearranged the data by routes, making each row represent a step in the process of individual students, and each column represent a route (0 for de-selecting, and 1 for selecting). Table 2 shows part of the reorganized data file, indicating how individual student selected each route in each step. For example, the first line represents that student 00017 selected P2 in his/her first step.

Table 2 . Example of the reorganized data file.
Process data were first recoded for the analysis purpose. Twenty-three variables were created to represent a total number of available routes that can possibly be selected (similar to 23 items). The right way for solving this problem is to select the following six routes: Diamond–Nowhere–Sakharov–Market–Lee–Mandela–Einstein (i.e., P1, P5, P7, P8, P13, and P17). For the correct routes, the scored response was 1 if one was selected, and 0 otherwise; for the incorrect routes, the scored response was 0 if one was selected, and 1 otherwise. Each row in the data file represents an effective step (or action) a student took during the process. In each step, when a route was selected or not, the response for this route was recoded accordingly. When a student finished an item, all the steps during the process were recorded. Therefore, for the completed data set, the responses of the 23 variables were obtained and the steps were nested within students.
The Modified MMixIRT Model Specification
The MMixIRT model has mixtures of latent classes at the process level or at both process and student levels. It assumes that possible heterogeneity exists in response patterns at the process level and therefore are not to be ignored ( Mislevy and Verhelst, 1990 ; Rost, 1990 ). Latent classes can capture the interactions among the responses at the process level ( Vermunt, 2003 ). It is interesting to note that if no process-level latent classes exist, there are no student-level latent classes, either. The reason lies in that student-level units are clustered based on the likelihood of the processes belonging to one of the latent classes. For this particular consideration, the main focus in this study is to explore how to classify the process-level data, and the modified MMixIRT model only focus on latent classes at the process level.
The MMixIRT model accounts for the heterogeneity by incorporating categorical or continuous latent variables at different levels. Because mixture models have categorical latent variables and item response models have continuous latent variables, latent variables at each level may be categorical or continuous. In this study, the modified MMixIRT includes both categorical (latent class estimates) and continuous latent variables at the process level and only continuous (ability estimates) latent variables at the student level.
The modified MMixIRT model for process-level data is specified as follows:
Process-Level
Student-Level
For the process level, in Equation (1), i is an index for i th route ( i = 1, …, I ), k is an index for a student ( k = 1,…, K ), j is an index for the j th valid step of a student during the response process ( j = 1, …, J k ),( J is the total steps of the k th student) and g indexes the latent classes ( C jk = 1, …, g … G , where G is the number of latent classes), C jk is a categorical latent variable at the process level for the j th valid step of student k , which captures the heterogeneity of the selections of routes in each step. P ( y jki = 1|θ jkg , C jk = g ) is the probability of selecting an route i in the j th step of student k , which is predicted by the two-parameter logistic (2PL) model, and α ig . W is the discrimination parameter of process-level in class g, W means within-level, β ig is the location parameter in class g , and θ jkg is the latent ability of examinee k for a specific step j during the process of selecting the route, which is called the process ability in this study (θ jkg ~ N( μ jkg , σ j k g 2 ) ). The process abilities across different latent classes are constrained to follow a normal distribution ( θ jk ~ N(0, 1)) . In Equation (2), P ( y jk 1 = ω 1 , y jk 2 = ω 2 , ⋯ , y jkI = ω I ) is the joint probability of the actions in the j th step of student k . ω i denotes either selected or not selected for i th route. For the correct routes, 1 represents that the route was selected, and 0 otherwise; for the incorrect routes, 0 represents that the route was selected, and 1 otherwise. γ jkg is the proportion of the j th step in each latent class and ∑ g = 1 G γ j k g = 1 . As can be seen from the Equation (2), the probability of the actions ( y jki ) are assumed to be independent from each other given class membership, which is known as the local independence assumption for mixture models.
For the student level, in Equation (3), α i . B is the item discrimination parameter where B represents between-level. β i is the item location parameter which is correlated with the responses of the final step of the item. θ k is the ability estimate at the student level based on the final step of the process, which also represents the problem-solving ability of student k in this study ( θ k ~ N(0 , 1)) .
Figure 2 demonstrates a modified two-level mixture item response model with within-level latent classes. The squares in the figure represent item responses, the ellipses represent latent variables, and 1 inside the triangle represents a vector of 1 s. As is shown in the figure, the response for each route of the jth step [ y jk 1 ,…, y jki ,…, y jkI ] is explained by both categorical and continuous latent variables ( C jk and θ jkg , respectively) at the process level; and the final response of students for each route [ y k 1 ,…, y ki ,…, y kI ] is explained by a continuous latent variable (θ k ) at the student level. The arrows from the continuous latent variables to the item (route) represent item (route) discrimination parameters (α ig, W at the process level and α i, B at the student level), and the arrows from the triangle to the item responses represent item location parameters at both levels. The dotted arrows from the categorical latent variable to the other arrows indicate that all item parameters are class-specific.

Figure 2 . The modified MMixIRT model for process data.
It should be noted that the MMixIRT model is different from the traditional two-level mixture item response model in the definition of the latent variables at the between-level. In the standard MMixIRT model, the between-level latent variables are generally obtained from the measurement results made by within-level response variables [ y jk 1 ,…, y jki ,…, y jkI ] on between-level latent variables ( Lee et al., 2017 ). In this study, the process-level data mainly reflect the strategies for problem solving, while the responses at the last step represent students' final answers on this task. Therefore, students' final responses are used to estimate their problem-solving abilities (latent variable at the between-level, i.e., ability of the student level) in the modified MMixIRT model.
Mplus Software ( Muthén and Muthén, 1998-2015 ) was used to estimate the parameters of the modified MMixIRT model, as specified above. In addition, the detailed syntax are presented in Appendix 5 .
Results of Descriptive Statistics
Table 3 shows the proportion of each route selected by the students in the correct group and in the wrong group, respectively. The correct group consists of students who selected the right routes, and the wrong group refers to students who failed to do so. There are a total of 476 students, with 377 in the correct group and 99 in the wrong group. The results show that most of the students in the correct group selected the right routes, while a large number of students in the wrong group selected the wrong routes. To further explore the differences of the proportion of students selecting the wrong routes in the two groups, χ 2 -tests were conducted. No significant differences were found between the correct group and the wrong group in terms of the proportion of students who clicked four wrong routes, including P4 [χ 2 (1) = 0.370, P > 0.05], P9 [χ 2 (1) = 3.199, P > 0.05], P10 [χ 2 (1) = 3.636, P > 0.05], and P15 [χ 2 (1) = 2.282, P > 0.05]. This further suggests that it was difficult for the correct group to avoid these routes during their response process, and even quite a number of students in the correct group experienced trial and error before eventually solving the problem.

Table 3 . The proportion of route selection.
Results of the Modified MMixIRT Model
Model selection.
The determination of the number of latent classes has been discussed in many studies ( Tofighi and Enders, 2008 ; Li et al., 2009 ; Peugh and Fan, 2012 ). Several statistics of the mixture IRT models are often computed to compare relative fits of these models. Akaike's (1974) information criterion (AIC) incorporates a kind of penalty function for over-parameterization on model complexity. A criticism of AIC has been that it is not asymptotically consistent because the sample size is not directly involved in its calculation ( Janssen and De Boeck, 1999 ; Forster, 2004 ). Schwarz (1978) proposed BIC as another information-based index, which attains asymptotic consistency by penalizing over-parameterization by using a logarithmic function of the sample size. For the sample size in BIC, the number of persons is used in multilevel model ( Hamaker Ellen et al., 2011 ) and in multilevel item response model ( Cohen and Cho, 2016 ). Most studies suggested the BIC value as the best choice because it was a sample-based index that also penalized the sophisticated model. However, Tofighi and Enders (2008) indicated in their simulation study that a sample size-adjusted BIC (aBIC) was an even better index. Smaller AIC, BIC, and aBIC values indicate a better model fit for mixture IRT models. Besides, entropy value has been used to measure how well a mixture model separates the classes; an entropy value close to 1 indicates good classification certainty ( Asparouhov and Muthén, 2014 ).
The model selection results for the modified MMixIRT models are given in Table 4 . The model fit indicates that LL, AIC, BIC , and aBIC decreased consistently as the class number increased to eight classes, and the nine-class model did not converge. As noted above, the best fit for AIC, BIC , and aBIC was determined or dictated by the smallest value in the ordered set of models from the least to the most complex. As suggested by Rosato and Baer (2012) , selecting a robust latent class model is a balance between the statistical result of the model fit and the substantive meaning of the model. The model that fits best and yields meaningful classes should be retained. In this study the proportions of latent classes were examined to ensure the empirical significance, and the interpretability of each class was considered accordingly. For the 6-class model, the proportion of each class was 18.1, 30.7, 18.1, 20.1, 7.2, and 5.9%. And for the 7-class model, the proportion was 19.9, 13.4, 6.0, 12.3, 13.5, 27.4, and 7.5%. Compared to the 6-class model, in the 7-class model, the extra class of the steps was similar to class 2 of the 6-class model, while mixing class 4 at the same time. This makes the 7-class model hard to interpret. For the 8-class model, the proportion of one of the classes was too small (only 2.7%). Taking into account both the model fit index and the interpretability of each class, the 6-class model was retained in this study.

Table 4 . Model comparison and selection.
Description of Class Characteristics
The most likely latent class membership are displayed in Table 5 . In this matrix, steps from each class have an average probability of being in each class. Large probabilities are expected on the diagonal. The numbers on diagonal are greater than 0.9. It can be concluded from the results that the modified MMixIRT model can classify students properly based on process data.

Table 5 . Most likely latent class membership of each class.
Figure 3 presents the characteristics of route selection for each class based on the 6-class mixture IRT model, with ➀, ➁, ➂.…indicating the order of the routes. Based on the results of the modified MMixIRT model, the number of clicks of the 23 routes (P1–P23) in each class is listed in Appendix 2 . The characteristics of route selection can be obtained pursuant to routes that get more clicks than others in each class, as well as the relations among routes shown in Figure 1 . For example, P17, P13, P1, P8, P5, P16, and P7 in Class 1 were clicked more than other routes; however, Figure 1 shows that there is no obvious relationship between P16 and other routes. Therefore, the characteristic of Class 1 was defined as P1-P13-P17-P8-P5-P7 and P16 was removed. These routes were sequenced by the number of clicks they got, with the most clicked routes taking the lead. As indicated in Figure 3 , different latent classes have typical characteristics depending on the similarity of the correct answers. For example, the route selection strategy of Class 1 best approximated the ideal route required by the item. Based on their last click, almost all the students in Class 1 gave the correct answer. Therefore, Class 1 could be regarded as the correct answer class, while the rest classes took different wrong routes.

Figure 3 . Route selection strategy by class.
The numbers in circles (➀, ➁, ➂….) indicate the order of the routes.
As is illustrated in Table 6 , different classes demonstrated different means of process-level ability. It is obvious that the mean process ability in Class 1 is the highest (0.493), followed by Class 6, Class 2, Class 4, yet Class 5 and Class 3 with the lowest process-level ability. A closer check of these classes in Figure 3 indicates that the selected routes of Class 5 and Class 3 were incredibly far away from the correct one, and they took far more than 31 min. Therefore, it is no surprise that the mean process-level ability estimates of these two classes were the lowest and were both negative (−1.438 and −0.935, respectively). In addition, as can be seen in the number of students, almost all the students in Class 1 provided the right answer, demonstrating that different latent classes had different probabilities of the correct answer. In summary, the process-level ability is different across latent classes, which is related to different strategies of students' route selection or cognitive process.

Table 6 . Means and standard deviations of process level abilities.
The Sequence of Latent Classes at the Process Level
Based on the results of the modified MMixIRT model, the characteristics of the strategy shifts between step-specific classes were explored and summarized. To capture the characteristics of students' strategy shifts during the response, it is necessary to identify the typical route selection strategy of each class in the first place. In this study, if a student applied the strategy of a certain class three or more times consecutively, it was considered that the student had employed the strategy of this class at the process level. Three times was chosen as the rule of thumb because it demonstrated enough stability to classify a solution behavior. Then the strategy shifts of each student during their clicking procedure could be obtained in orders. The typical route selection strategy of different classes and the class shifts of students in the correct group are presented in Appendixes 3 , 4 , respectively. The results in Appendix 4 provide useful and specific information about the strategy shifts used by students over time. For example, in the correct group, 58 students shifted from one class to another, including 22 from Class 2 to Class 1, 3 from Class 3 to Class 1, 30 from Class 4 to Class 0, and 3 from Class 6 to Class 1. It is noteworthy that when students did not apply any strategies for more than three times consecutively, it was regarded as class 0 in this study.
The Relationship of the Two Level Ability Estimates and Operational Variables
To validate whether students with different patterns of actions will have different process-level ability, the descriptive statistics were conducted of operational variables such as the number of route clicks and resets and their correlation with the mean ability estimate of process-level ability (See Table 7 for details). To further explore the differences of click actions between the correct group and the wrong group, several T -tests were conducted. The results indicate that students in the correct group did significantly fewer resets than their counterparts in the wrong group [ t (404) = 2.310, P < 0.05]. No significant differences were detected of the number of routes clicked or the response time between the correct group and the wrong group [ t (404) = 1.656, P = 0.099; t (404) = −0.199, P = 0.843]. The results in Table 7 suggest two things. Firstly, positive correlation existed between the estimate of student-level ability and that of process-level ability. This means that the process-level ability estimate provides consistency and auxiliary diagnostic information about the process. The students with higher process-level ability had higher ability estimates of student level. Secondly, for the process-level ability, a significant negative correlation existed between the mean process-level ability estimate and variables such as the valid number of route clicks and the number of resets for students in the correct group. It is concluded that in the correct group, the less frequently a student clicks the routes and resets the whole process, the higher process-level ability he or she is likely to obtain. For students in the wrong group, however, no significant correlations were observed between the mean ability estimate and the variables discussed above. Instead, a significant negative correlation was found between the mean process-level ability estimate and the absolute time of difference from 31 min. For these students, their process-level ability decreased as the time cost by the wrong routes increased. Third, the mean process-level ability estimate for the correct group was 0.310, in contrast to −0.175 for the wrong group, which reveals a significant difference between the two groups [ t (404) = 8.959, P < 0.001]. In terms of student-level ability, the estimate for the correct group was significantly higher than for the wrong group [ t (404) = 112.83, P < 0.001].

Table 7 . Correlation between ability estimates and operational variables in process.
The result in Table 8 indicates that the sequence of latent classes are consistent with the ability estimates at both process and student levels. For students in the correct group, the mean process-level ability estimate decreased as the number of class shifts, clicks and resets increased. Students with higher process-level ability tended to select the correct route immediately or after a few attempts. Consequently, these students clicked and reset for fewer times because they had a clearer answer in mind and therefore were more certain about it. In contrast, for students in the wrong group, the mean ability estimates at both process and student levels were rather small when the number of class shifts were 0 and 1. When the number of class shifts was 0, students failed to stick with a specific strategy to solve the problem during the process. It took them a longer response time with about two resets on average; as a result, the time cost for their route selection was nearly twice the target time. When the number of class shifts was 1, these students simply stuck to a totally wrong route for the entire time, with shorter response time and fewer numbers of clicks. However, unlike the correct group, the number of class shifts in the wrong group showed a non-linear relationship with the mean ability at both process and student levels. At first, when the number of class shifts increased from 0 to 4, the ability estimates at both levels increased as well. The explanation was that because these students figured out the right routes, they should have higher abilities than the 0 shift group that sticks to the wrong route all the time. For example, students with four shifts all ended up using strategy of Class 1, which was the right strategy class (Appendix 4 ). Therefore, they were supposed to have the highest process ability in the wrong group. However, when the number of class shifts increased from 5 to 6, the process-level ability estimate dropped. This has much to do with the fact that too many shifts reflected little consideration and a lack of deep cognitive processing.

Table 8 . Ability estimates and the operational variables in the different numbers of class shifts in the correct group and wrong group.
A modified MMixIRT model was described for modeling response data at process and student levels. The model developed in this study combined the features of an IRT model, a latent class model, and a multilevel model. The process-level data provide an opportunity to determine whether latent classes or class shifts differ in their response strategies to solve the problem. The student-level data can be used to account for the differences of students' problem solving abilities. The ability estimate at both process and student levels are different across latent classes. The modified MMixIRT model makes it possible to describe differential strategies based on process-level and student-level characteristics. If a student's specific strategies and their strengths and weaknesses can be described in the process of solving a problem, then the assessment of a student's proficiency in problem solving can guide instructional interventions in target areas.
As process data from various computer-based assessment or educational learning system have become common, there is an urgent call for analyzing such data in an accurate way. The psychometrical model-based approach has a great potential in this aspect. Latent classes and the characteristics of latent class shifts obtained from process data can reveal students' reasoning skills in problem-solving. The findings of characteristics of process-level latent classes make it easy to uncover meaningful and interesting action patterns from the process data, and to compare patterns from different students. These findings provide valuable information to psychometricians and test developers, help them better understand what distinguishes successful students from unsuccessful ones, and eventually lead to better test design. In addition, as shown in this study, some operational variables such as the number of resets and the number of clicks or double clicks are related to the ability estimates at both process and student levels and therefore can predict student scores on problem solving assessment. Since students' different abilities capture individual patterns in process data, it can be used to score or validate the rubrics. Williamson et al. (2006) explain that a “key to leveraging the expanded capability to collect and record data from complex assessment tasks is implementing automated scoring algorithms to interpret data of the quantity and complexity that can now be collected” (p. 2).
The extension of the modified MMixIRT approach proposed in this study can be implemented in several ways. Firstly, it can be simplified in removing the process-level ability parameters, and also be extended to include student-level latent classes instead of abilities. Secondly, one of the advantages of this proposed model is that item parameters can be constrained to be equal across the process-level and student-level. So the abilities of both levels are on the same scale and can be compared and evaluated. Lastly, the main benefits of multilevel IRT modeling lie in the possibility of estimating the latent traits (e.g., problem solving) at each level. More measurement errors can be accounted for by considering other relevant predictors such as motivations ( Fox and Glas, 2003 ).
The psychometrical model-based approach also has its limitations. First, even though latent class shifts preserve the sequential information in action series, they do not capture all the related information. For instance, for the purpose of convenient analysis in this study, some unstable characteristics of a latent class such as random shifts were not used in our definition of class characteristics and class shifts. Fortunately, in many cases, as in this study, this missing information does not affect the results. If it becomes an issue in some cases, it can be addressed by considering more details about the latent class shifts to minimize the ambiguity. Second, this study only takes a single route as an analysis unit, yet failing to consider possible route combinations. For example, in some cases two routes are available, it makes full sense to combine these two routes into one to conduct analysis, because the link between these routes is exclusive. In the future, we may consider the transition model for different route combinations, such as Bi-Road. In terms of the generalizability of the modified MMixIRT model for solving complicated problems, if the process data for another single task can be recoded or restructured as the data file in this study, similar models can be applied to explore the latent classes and characteristics of the problem solving process. However, the difficulty during the analysis lies in how to recode the responses into dichotomous data. For multiple tasks, a three-level model can be applied, with the first level as the process level, the second as the task level and the third as the student level. If there are plenty of tasks, the ability estimates of the student will stay stable. Therefore, while the generalizability of the model may be conditional, the main logic of the MMixIRT approach can be generalized.
Author Contributions
HL research design, data analysis, and paper writing. YL paper writing. ML data analysis, and paper writing.
Supported by National Natural Science Foundation of China (31571152); Special Found for Beijing Common Construction Project (019-105812).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2018.01372/full#supplementary-material
Akaike, H. (1974). A new look at the statistical model identification. IEEE Trans. Autom. Control 19, 716–723. doi: 10.1109/TAC.1974.1100705
CrossRef Full Text | Google Scholar
Asparouhov, T., and Muthén, B. (2014). Auxiliary variables in mixture modeling: three-step approaches using Mplus. Struct. Equat. Model. 21, 329–341. doi: 10.1080/10705511.2014.915181
Bergner, Y., Shu, Z., and von Davier, A. A. (2014). “Visualization and confirmatory clustering of sequence data from a simulation based assessment task,” in Proceedings of the 7th International Conference on Educational Data Mining , 177–184. Available online at: http://educationaldatamining.org/EDM2014/uploads/procs2014/long%20papers/177_EDM-2014-Full.pdf
Google Scholar
Bolt, D. M., Cohen, A. S., and Wollack, J. A. (2001). A mixture item response for multiple choice data. J. Educ. Behav. Stat. 26, 381–409. doi: 10.3102/10769986026004381
Cohen, A. S., and Cho, S. J. (2016). “Information criteria,” in Handbook of Item Response Theory: Statistical Tools , ed W. J. van der Linden (Boca Raton, FL: Chapman and Hall/CRC), 363–378.
Desmarais, M. C., and Baker, R. S. J. D. (2012). A review of recent advances in learner and skill modeling in intelligent learning environments. User Model. User Adapt. Interact. 22, 9–38. doi: 10.1007/s11257-011-9106-8
DiCerbo, K. E., and Behrens, J. T. (2012). “Implications of the digital ocean on current andfuture assessment,” in Computers and their Impact on State Assessment: Recent History and Predictions for the Future , eds R. Lissitz and H. Jiao (Charlotte, NC: Information Age Publishing), 273–306.
DiCerbo, K. E., Liu, J., Rutstein, D. W., Choi, Y., and Behrens, J. T. (2011). Visualanalysis of sequential log data from complex performance assessments . Paper presented at the Annual Meeting of the American Educational Research Association (New Orleans, LA).
Forster, M. R. (2004). Simplicity and Unification in Model Selection. University of Wisconsin–Madison . Available online at: http://philosophy.wisc.edu/forster/520/Chapter%230.pdf
Fox, J. P., and Glas, C. A. W. (2003). Bayesian modeling of measurement error in predictor variables using item response theory. Psychometrika 68, 169–191. doi: 10.1007/bf02294796
Garofalo, J., and Lester, F. K. (1985). Metacognition, cognitive monitoring, and mathematical performance. J. Res. Math. Educ. 16, 163–176. doi: 10.2307/748391
Goldstein, H. (1987). Multilevel models in education and social research. High. Educ. Res. Dev. 28, 664–645.
Hamaker Ellen, L., van Hattum, P., Kuiper Rebecca, M., and Hoijtink, H. (2011). “Model selection based on information criteria in multilevel modeling,” in Handbook of Advanced Multilevel Analysis , eds J. J. Hox and J. K. Roberts (New York, NY: Routledge), 231–256.
Hao, J., Shu, Z., and von Davier, A. (2015). Analyzing process data from game/scenario-basedtasks: an edit distance approach. J. Educ. Data Mining 7, 33–50.
Hox, J. J. (2010). Multilevel Analysis Methods: Techniques and Applications . New York, NY: Routledge.
Janssen, R., and De Boeck, P. (1999). Confirmatory analyses of componential test structure using multidimensional item response theory. Multivariate Behav. Res. 34, 245–268. doi: 10.1207/s15327906mb340205
PubMed Abstract | CrossRef Full Text | Google Scholar
Kerr, D., Chung, G., and Iseli, M. (2011). The Feasibility of Using Cluster Analysis to Examine Log Data From Educational Video Games . CRESST Report, No. 790. Los Angeles, CA: National Center for Research on Evaluation, Standards, and Student Testing (CRESST).
Kurniati, D., and Annizar, A. M. (2017). The analysis of students' cognitive problem solving skill in solving PISA standard-based test item. Adv. Sci. Lett. 23, 776–780. doi: 10.1166/asl.2017.7466
Lee, W. Y., Cho, S. J., and Sterba, S. K. (2017). Ignoring a multilevel structure in mixture item response models: impact on parameter recovery and model selection. Appl. Psychol. Meas. 42, 136–154. doi: 10.1177/0146621617711999
Li, F., Cohen, A. S., Kim, S. H., and Cho, S. J. (2009). Model selection methods for mixture dichotomous IRT models. Appl. Psychol. Meas. 33, 353–373. doi: 10.1177/0146621608326422
Mislevy, R. J., Oranje, A., Bauer, M. I., von Davier, A. A., Hao, J., Corrigan, S., et al. (2014). Psychometric Considerations in Game-Based Assessment . GlassLab Research White Paper. Princeton, NJ: Educational Testing Service.
Mislevy, R. J., and Verhelst, N. (1990). Modeling item responses when different subjects employ different solution strategies. Psychometrika 55, 195–215. doi: 10.1007/bf02295283
Muthén, L. K., and Muthén, B. O. (1998-2015). Mplus Users Guide, 7th Edn . Los Angeles, CA: Muthén Muthén.
OECD (2013). PISA 2012 Assessment and Analytical Framework: Mathematics, Reading, Science, Problem Solving and Financial Literacy. OECD Publishing . Available online at: http://www.oecd.org/pisa/pisaproducts/pisa2012draftframeworks-mathematicsproblemsolvingandfinancialliteracy.htm
OECD (2014). PISA 2012 Results: Creative Problem Solving: Students' Skills in Tackling Real-LIFE Problems Vol. 5, PISA, OECD Publishing . Available online at: http://www.oecd.org/education/pisa-2012-results-volume-v.htm
Peugh, J., and Fan, X. (2012). How well does growth mixture modeling identify heterogeneous growth trajectories? a simulation study examining GMM's performance characteristics . Struct. Equat. Model. 19, 204–226. doi: 10.1080/10705511.2012.659618
CrossRef Full Text
Raudenbush, S. W., and Bryk, A. S. (2002). Hierarchical Linear Models: Applications and Data Analysis Methods, 2nd Edn . Newbury Park, CA: SAGE.
Romero, C., Espejo, P. G., Zafra, A., Romero, J. R., and Ventura, S. (2013). Web usage mining for predicting final marks of students that use moodle courses. Comput. Appl. Eng. Educ. 21, 135–146. doi: 10.1002/cae.20456
Romero, C., and Ventura, S. (2010). Educational datamining: a review of the state of the art. IEEE Trans. Syst. Man Cybern. Part C 40, 601–618. doi: 10.1109/tsmcc.2010.2053532
Romero, C., Ventura, S., and García, E. (2008). Data mining in course management systems: moodle case study and tutorial. Comput. Educ. 51, 368–384. doi: 10.1016/j.compedu.2007.05.016
Rosato, N. S., and Baer, J. C. (2012). Latent class analysis: a method for capturing heterogeneity. Soc. Work Res. 36, 61–69.doi: 10.1093/swr/svs006
Rost, J. (1990). Rasch models in latent classes: an integration of two approaches to item analysis. Appl. Psychol. Meas. 14, 271–282. doi: 10.1177/014662169001400305
Schwarz, G. (1978). Estimating the dimension of a model. Ann. Stat. 6, 461–464. doi: 10.1214/aos/1176344136
Shu, Z., Bergner, Y., Zhu, M., Hao, J., and von Davier, A. A. (2017). An item response theory analysis of problem-solving processed in scenario-based tasks. Psychol. Test Assess. Model. 59, 109–131.
Tofighi, D., and Enders, C. K. (2008). Identifying the Correct Number of Classes in Growth Mixture Models , Vol. 13. Charlotte, NC: Information Age Publishing Inc.
Vermunt, J. K. (2003). Multilevel latent class models. Sociol. Methodol. 33, 213–239. doi: 10.1111/j.0081-1750.2003.t01-1-00131.x
Williamson, D., Bejar, I. I., and Mislevy, R. J. (2006). “Automated scoring of complex tasks in computer-based testing: an introduction,” in Automated Scoring of Complex Tasks in Computer-Based Testing , eds D. M. Williamson, I. I. Bejar, and R. J. Mislevy (Hillsdale, NJ: Laurence Erlbaum), 1–13.
Zhu, M., Shu, Z., and von Davier, A. A. (2016). Using networks to visualize and analyzeprocess data for educational assessment. J. Educ. Meas. 53, 190–211. doi: 10.1111/jedm.12107
Zoanetti, N. (2010). Interactive computer based assessment tasks: how problem-solving process data can inform instruction. Austral. J. Educ. Technol. 26, 585–606. doi: 10.14742/ajet.1053
Keywords: computer-based problem solving, PISA2012, process data, the modified multilevel mixture IRT model, the process level, the student level
Citation: Liu H, Liu Y and Li M (2018) Analysis of Process Data of PISA 2012 Computer-Based Problem Solving: Application of the Modified Multilevel Mixture IRT Model. Front. Psychol . 9:1372. doi: 10.3389/fpsyg.2018.01372
Received: 03 February 2018; Accepted: 16 July 2018; Published: 03 August 2018.
Reviewed by:
Copyright © 2018 Liu, Liu and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY) . The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Meijuan Li, [email protected]
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
35 problem-solving techniques and methods for solving complex problems

Design your next session with SessionLab
Join the 150,000+ facilitators using SessionLab.
Recommended Articles
A step-by-step guide to planning a workshop, how to create an unforgettable training session in 8 simple steps, 47 useful online tools for workshop planning and meeting facilitation.
All teams and organizations encounter challenges as they grow. There are problems that might occur for teams when it comes to miscommunication or resolving business-critical issues . You may face challenges around growth , design , user engagement, and even team culture and happiness. In short, problem-solving techniques should be part of every team’s skillset.
Problem-solving methods are primarily designed to help a group or team through a process of first identifying problems and challenges , ideating possible solutions , and then evaluating the most suitable .
Finding effective solutions to complex problems isn’t easy, but by using the right process and techniques, you can help your team be more efficient in the process.
So how do you develop strategies that are engaging, and empower your team to solve problems effectively?
In this blog post, we share a series of problem-solving tools you can use in your next workshop or team meeting. You’ll also find some tips for facilitating the process and how to enable others to solve complex problems.
Let’s get started!
How do you identify problems?
How do you identify the right solution.
- Tips for more effective problem-solving
Complete problem-solving methods
- Problem-solving techniques to identify and analyze problems
- Problem-solving techniques for developing solutions
Problem-solving warm-up activities
Closing activities for a problem-solving process.
Before you can move towards finding the right solution for a given problem, you first need to identify and define the problem you wish to solve.
Here, you want to clearly articulate what the problem is and allow your group to do the same. Remember that everyone in a group is likely to have differing perspectives and alignment is necessary in order to help the group move forward.
Identifying a problem accurately also requires that all members of a group are able to contribute their views in an open and safe manner. It can be scary for people to stand up and contribute, especially if the problems or challenges are emotive or personal in nature. Be sure to try and create a psychologically safe space for these kinds of discussions.
Remember that problem analysis and further discussion are also important. Not taking the time to fully analyze and discuss a challenge can result in the development of solutions that are not fit for purpose or do not address the underlying issue.
Successfully identifying and then analyzing a problem means facilitating a group through activities designed to help them clearly and honestly articulate their thoughts and produce usable insight.
With this data, you might then produce a problem statement that clearly describes the problem you wish to be addressed and also state the goal of any process you undertake to tackle this issue.
Finding solutions is the end goal of any process. Complex organizational challenges can only be solved with an appropriate solution but discovering them requires using the right problem-solving tool.
After you’ve explored a problem and discussed ideas, you need to help a team discuss and choose the right solution. Consensus tools and methods such as those below help a group explore possible solutions before then voting for the best. They’re a great way to tap into the collective intelligence of the group for great results!
Remember that the process is often iterative. Great problem solvers often roadtest a viable solution in a measured way to see what works too. While you might not get the right solution on your first try, the methods below help teams land on the most likely to succeed solution while also holding space for improvement.
Every effective problem solving process begins with an agenda . A well-structured workshop is one of the best methods for successfully guiding a group from exploring a problem to implementing a solution.
In SessionLab, it’s easy to go from an idea to a complete agenda . Start by dragging and dropping your core problem solving activities into place . Add timings, breaks and necessary materials before sharing your agenda with your colleagues.
The resulting agenda will be your guide to an effective and productive problem solving session that will also help you stay organized on the day!
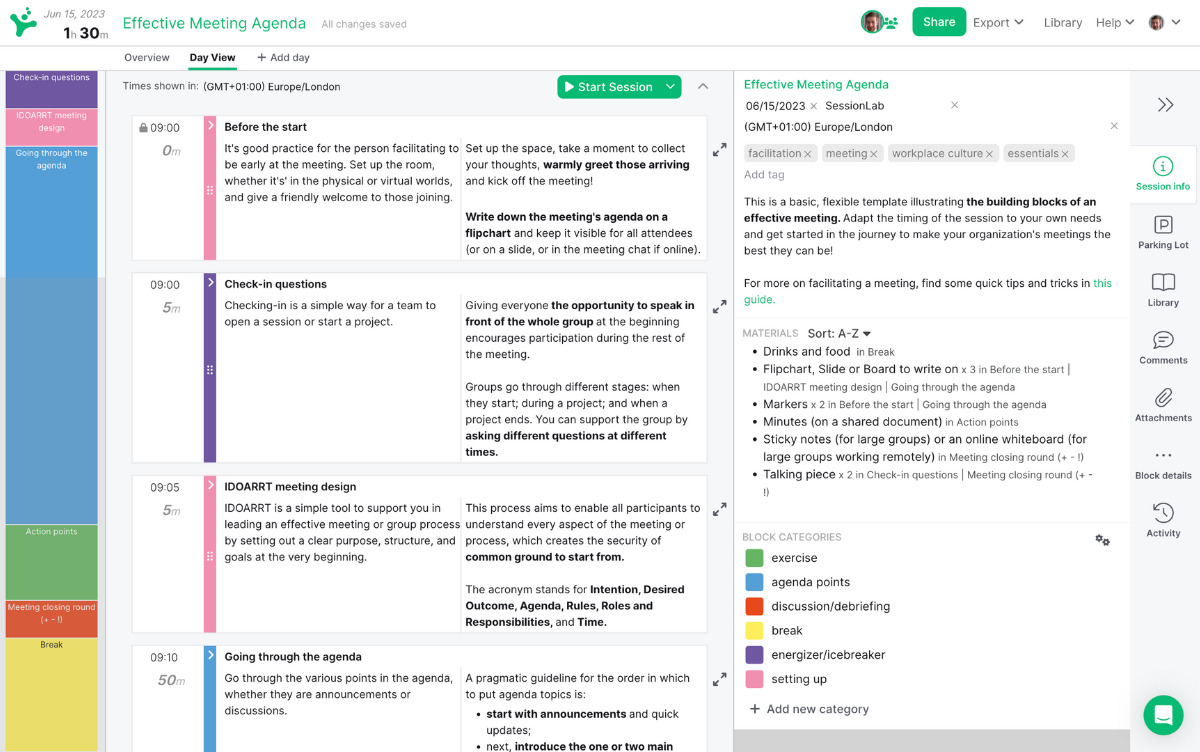
Tips for more effective problem solving
Problem-solving activities are only one part of the puzzle. While a great method can help unlock your team’s ability to solve problems, without a thoughtful approach and strong facilitation the solutions may not be fit for purpose.
Let’s take a look at some problem-solving tips you can apply to any process to help it be a success!
Clearly define the problem
Jumping straight to solutions can be tempting, though without first clearly articulating a problem, the solution might not be the right one. Many of the problem-solving activities below include sections where the problem is explored and clearly defined before moving on.
This is a vital part of the problem-solving process and taking the time to fully define an issue can save time and effort later. A clear definition helps identify irrelevant information and it also ensures that your team sets off on the right track.
Don’t jump to conclusions
It’s easy for groups to exhibit cognitive bias or have preconceived ideas about both problems and potential solutions. Be sure to back up any problem statements or potential solutions with facts, research, and adequate forethought.
The best techniques ask participants to be methodical and challenge preconceived notions. Make sure you give the group enough time and space to collect relevant information and consider the problem in a new way. By approaching the process with a clear, rational mindset, you’ll often find that better solutions are more forthcoming.
Try different approaches
Problems come in all shapes and sizes and so too should the methods you use to solve them. If you find that one approach isn’t yielding results and your team isn’t finding different solutions, try mixing it up. You’ll be surprised at how using a new creative activity can unblock your team and generate great solutions.
Don’t take it personally
Depending on the nature of your team or organizational problems, it’s easy for conversations to get heated. While it’s good for participants to be engaged in the discussions, ensure that emotions don’t run too high and that blame isn’t thrown around while finding solutions.
You’re all in it together, and even if your team or area is seeing problems, that isn’t necessarily a disparagement of you personally. Using facilitation skills to manage group dynamics is one effective method of helping conversations be more constructive.
Get the right people in the room
Your problem-solving method is often only as effective as the group using it. Getting the right people on the job and managing the number of people present is important too!
If the group is too small, you may not get enough different perspectives to effectively solve a problem. If the group is too large, you can go round and round during the ideation stages.
Creating the right group makeup is also important in ensuring you have the necessary expertise and skillset to both identify and follow up on potential solutions. Carefully consider who to include at each stage to help ensure your problem-solving method is followed and positioned for success.
Document everything
The best solutions can take refinement, iteration, and reflection to come out. Get into a habit of documenting your process in order to keep all the learnings from the session and to allow ideas to mature and develop. Many of the methods below involve the creation of documents or shared resources. Be sure to keep and share these so everyone can benefit from the work done!
Bring a facilitator
Facilitation is all about making group processes easier. With a subject as potentially emotive and important as problem-solving, having an impartial third party in the form of a facilitator can make all the difference in finding great solutions and keeping the process moving. Consider bringing a facilitator to your problem-solving session to get better results and generate meaningful solutions!
Develop your problem-solving skills
It takes time and practice to be an effective problem solver. While some roles or participants might more naturally gravitate towards problem-solving, it can take development and planning to help everyone create better solutions.
You might develop a training program, run a problem-solving workshop or simply ask your team to practice using the techniques below. Check out our post on problem-solving skills to see how you and your group can develop the right mental process and be more resilient to issues too!
Design a great agenda
Workshops are a great format for solving problems. With the right approach, you can focus a group and help them find the solutions to their own problems. But designing a process can be time-consuming and finding the right activities can be difficult.
Check out our workshop planning guide to level-up your agenda design and start running more effective workshops. Need inspiration? Check out templates designed by expert facilitators to help you kickstart your process!
In this section, we’ll look at in-depth problem-solving methods that provide a complete end-to-end process for developing effective solutions. These will help guide your team from the discovery and definition of a problem through to delivering the right solution.
If you’re looking for an all-encompassing method or problem-solving model, these processes are a great place to start. They’ll ask your team to challenge preconceived ideas and adopt a mindset for solving problems more effectively.
- Six Thinking Hats
- Lightning Decision Jam
- Problem Definition Process
- Discovery & Action Dialogue
Design Sprint 2.0
- Open Space Technology
1. Six Thinking Hats
Individual approaches to solving a problem can be very different based on what team or role an individual holds. It can be easy for existing biases or perspectives to find their way into the mix, or for internal politics to direct a conversation.
Six Thinking Hats is a classic method for identifying the problems that need to be solved and enables your team to consider them from different angles, whether that is by focusing on facts and data, creative solutions, or by considering why a particular solution might not work.
Like all problem-solving frameworks, Six Thinking Hats is effective at helping teams remove roadblocks from a conversation or discussion and come to terms with all the aspects necessary to solve complex problems.
2. Lightning Decision Jam
Featured courtesy of Jonathan Courtney of AJ&Smart Berlin, Lightning Decision Jam is one of those strategies that should be in every facilitation toolbox. Exploring problems and finding solutions is often creative in nature, though as with any creative process, there is the potential to lose focus and get lost.
Unstructured discussions might get you there in the end, but it’s much more effective to use a method that creates a clear process and team focus.
In Lightning Decision Jam, participants are invited to begin by writing challenges, concerns, or mistakes on post-its without discussing them before then being invited by the moderator to present them to the group.
From there, the team vote on which problems to solve and are guided through steps that will allow them to reframe those problems, create solutions and then decide what to execute on.
By deciding the problems that need to be solved as a team before moving on, this group process is great for ensuring the whole team is aligned and can take ownership over the next stages.
Lightning Decision Jam (LDJ) #action #decision making #problem solving #issue analysis #innovation #design #remote-friendly The problem with anything that requires creative thinking is that it’s easy to get lost—lose focus and fall into the trap of having useless, open-ended, unstructured discussions. Here’s the most effective solution I’ve found: Replace all open, unstructured discussion with a clear process. What to use this exercise for: Anything which requires a group of people to make decisions, solve problems or discuss challenges. It’s always good to frame an LDJ session with a broad topic, here are some examples: The conversion flow of our checkout Our internal design process How we organise events Keeping up with our competition Improving sales flow
3. Problem Definition Process
While problems can be complex, the problem-solving methods you use to identify and solve those problems can often be simple in design.
By taking the time to truly identify and define a problem before asking the group to reframe the challenge as an opportunity, this method is a great way to enable change.
Begin by identifying a focus question and exploring the ways in which it manifests before splitting into five teams who will each consider the problem using a different method: escape, reversal, exaggeration, distortion or wishful. Teams develop a problem objective and create ideas in line with their method before then feeding them back to the group.
This method is great for enabling in-depth discussions while also creating space for finding creative solutions too!
Problem Definition #problem solving #idea generation #creativity #online #remote-friendly A problem solving technique to define a problem, challenge or opportunity and to generate ideas.
4. The 5 Whys
Sometimes, a group needs to go further with their strategies and analyze the root cause at the heart of organizational issues. An RCA or root cause analysis is the process of identifying what is at the heart of business problems or recurring challenges.
The 5 Whys is a simple and effective method of helping a group go find the root cause of any problem or challenge and conduct analysis that will deliver results.
By beginning with the creation of a problem statement and going through five stages to refine it, The 5 Whys provides everything you need to truly discover the cause of an issue.
The 5 Whys #hyperisland #innovation This simple and powerful method is useful for getting to the core of a problem or challenge. As the title suggests, the group defines a problems, then asks the question “why” five times, often using the resulting explanation as a starting point for creative problem solving.
5. World Cafe
World Cafe is a simple but powerful facilitation technique to help bigger groups to focus their energy and attention on solving complex problems.
World Cafe enables this approach by creating a relaxed atmosphere where participants are able to self-organize and explore topics relevant and important to them which are themed around a central problem-solving purpose. Create the right atmosphere by modeling your space after a cafe and after guiding the group through the method, let them take the lead!
Making problem-solving a part of your organization’s culture in the long term can be a difficult undertaking. More approachable formats like World Cafe can be especially effective in bringing people unfamiliar with workshops into the fold.
World Cafe #hyperisland #innovation #issue analysis World Café is a simple yet powerful method, originated by Juanita Brown, for enabling meaningful conversations driven completely by participants and the topics that are relevant and important to them. Facilitators create a cafe-style space and provide simple guidelines. Participants then self-organize and explore a set of relevant topics or questions for conversation.
6. Discovery & Action Dialogue (DAD)
One of the best approaches is to create a safe space for a group to share and discover practices and behaviors that can help them find their own solutions.
With DAD, you can help a group choose which problems they wish to solve and which approaches they will take to do so. It’s great at helping remove resistance to change and can help get buy-in at every level too!
This process of enabling frontline ownership is great in ensuring follow-through and is one of the methods you will want in your toolbox as a facilitator.
Discovery & Action Dialogue (DAD) #idea generation #liberating structures #action #issue analysis #remote-friendly DADs make it easy for a group or community to discover practices and behaviors that enable some individuals (without access to special resources and facing the same constraints) to find better solutions than their peers to common problems. These are called positive deviant (PD) behaviors and practices. DADs make it possible for people in the group, unit, or community to discover by themselves these PD practices. DADs also create favorable conditions for stimulating participants’ creativity in spaces where they can feel safe to invent new and more effective practices. Resistance to change evaporates as participants are unleashed to choose freely which practices they will adopt or try and which problems they will tackle. DADs make it possible to achieve frontline ownership of solutions.
7. Design Sprint 2.0
Want to see how a team can solve big problems and move forward with prototyping and testing solutions in a few days? The Design Sprint 2.0 template from Jake Knapp, author of Sprint, is a complete agenda for a with proven results.
Developing the right agenda can involve difficult but necessary planning. Ensuring all the correct steps are followed can also be stressful or time-consuming depending on your level of experience.
Use this complete 4-day workshop template if you are finding there is no obvious solution to your challenge and want to focus your team around a specific problem that might require a shortcut to launching a minimum viable product or waiting for the organization-wide implementation of a solution.
8. Open space technology
Open space technology- developed by Harrison Owen – creates a space where large groups are invited to take ownership of their problem solving and lead individual sessions. Open space technology is a great format when you have a great deal of expertise and insight in the room and want to allow for different takes and approaches on a particular theme or problem you need to be solved.
Start by bringing your participants together to align around a central theme and focus their efforts. Explain the ground rules to help guide the problem-solving process and then invite members to identify any issue connecting to the central theme that they are interested in and are prepared to take responsibility for.
Once participants have decided on their approach to the core theme, they write their issue on a piece of paper, announce it to the group, pick a session time and place, and post the paper on the wall. As the wall fills up with sessions, the group is then invited to join the sessions that interest them the most and which they can contribute to, then you’re ready to begin!
Everyone joins the problem-solving group they’ve signed up to, record the discussion and if appropriate, findings can then be shared with the rest of the group afterward.
Open Space Technology #action plan #idea generation #problem solving #issue analysis #large group #online #remote-friendly Open Space is a methodology for large groups to create their agenda discerning important topics for discussion, suitable for conferences, community gatherings and whole system facilitation
Techniques to identify and analyze problems
Using a problem-solving method to help a team identify and analyze a problem can be a quick and effective addition to any workshop or meeting.
While further actions are always necessary, you can generate momentum and alignment easily, and these activities are a great place to get started.
We’ve put together this list of techniques to help you and your team with problem identification, analysis, and discussion that sets the foundation for developing effective solutions.
Let’s take a look!
- The Creativity Dice
- Fishbone Analysis
- Problem Tree
- SWOT Analysis
- Agreement-Certainty Matrix
- The Journalistic Six
- LEGO Challenge
- What, So What, Now What?
- Journalists
Individual and group perspectives are incredibly important, but what happens if people are set in their minds and need a change of perspective in order to approach a problem more effectively?
Flip It is a method we love because it is both simple to understand and run, and allows groups to understand how their perspectives and biases are formed.
Participants in Flip It are first invited to consider concerns, issues, or problems from a perspective of fear and write them on a flip chart. Then, the group is asked to consider those same issues from a perspective of hope and flip their understanding.
No problem and solution is free from existing bias and by changing perspectives with Flip It, you can then develop a problem solving model quickly and effectively.
Flip It! #gamestorming #problem solving #action Often, a change in a problem or situation comes simply from a change in our perspectives. Flip It! is a quick game designed to show players that perspectives are made, not born.
10. The Creativity Dice
One of the most useful problem solving skills you can teach your team is of approaching challenges with creativity, flexibility, and openness. Games like The Creativity Dice allow teams to overcome the potential hurdle of too much linear thinking and approach the process with a sense of fun and speed.
In The Creativity Dice, participants are organized around a topic and roll a dice to determine what they will work on for a period of 3 minutes at a time. They might roll a 3 and work on investigating factual information on the chosen topic. They might roll a 1 and work on identifying the specific goals, standards, or criteria for the session.
Encouraging rapid work and iteration while asking participants to be flexible are great skills to cultivate. Having a stage for idea incubation in this game is also important. Moments of pause can help ensure the ideas that are put forward are the most suitable.
The Creativity Dice #creativity #problem solving #thiagi #issue analysis Too much linear thinking is hazardous to creative problem solving. To be creative, you should approach the problem (or the opportunity) from different points of view. You should leave a thought hanging in mid-air and move to another. This skipping around prevents premature closure and lets your brain incubate one line of thought while you consciously pursue another.
11. Fishbone Analysis
Organizational or team challenges are rarely simple, and it’s important to remember that one problem can be an indication of something that goes deeper and may require further consideration to be solved.
Fishbone Analysis helps groups to dig deeper and understand the origins of a problem. It’s a great example of a root cause analysis method that is simple for everyone on a team to get their head around.
Participants in this activity are asked to annotate a diagram of a fish, first adding the problem or issue to be worked on at the head of a fish before then brainstorming the root causes of the problem and adding them as bones on the fish.
Using abstractions such as a diagram of a fish can really help a team break out of their regular thinking and develop a creative approach.
Fishbone Analysis #problem solving ##root cause analysis #decision making #online facilitation A process to help identify and understand the origins of problems, issues or observations.
12. Problem Tree
Encouraging visual thinking can be an essential part of many strategies. By simply reframing and clarifying problems, a group can move towards developing a problem solving model that works for them.
In Problem Tree, groups are asked to first brainstorm a list of problems – these can be design problems, team problems or larger business problems – and then organize them into a hierarchy. The hierarchy could be from most important to least important or abstract to practical, though the key thing with problem solving games that involve this aspect is that your group has some way of managing and sorting all the issues that are raised.
Once you have a list of problems that need to be solved and have organized them accordingly, you’re then well-positioned for the next problem solving steps.
Problem tree #define intentions #create #design #issue analysis A problem tree is a tool to clarify the hierarchy of problems addressed by the team within a design project; it represents high level problems or related sublevel problems.
13. SWOT Analysis
Chances are you’ve heard of the SWOT Analysis before. This problem-solving method focuses on identifying strengths, weaknesses, opportunities, and threats is a tried and tested method for both individuals and teams.
Start by creating a desired end state or outcome and bare this in mind – any process solving model is made more effective by knowing what you are moving towards. Create a quadrant made up of the four categories of a SWOT analysis and ask participants to generate ideas based on each of those quadrants.
Once you have those ideas assembled in their quadrants, cluster them together based on their affinity with other ideas. These clusters are then used to facilitate group conversations and move things forward.
SWOT analysis #gamestorming #problem solving #action #meeting facilitation The SWOT Analysis is a long-standing technique of looking at what we have, with respect to the desired end state, as well as what we could improve on. It gives us an opportunity to gauge approaching opportunities and dangers, and assess the seriousness of the conditions that affect our future. When we understand those conditions, we can influence what comes next.
14. Agreement-Certainty Matrix
Not every problem-solving approach is right for every challenge, and deciding on the right method for the challenge at hand is a key part of being an effective team.
The Agreement Certainty matrix helps teams align on the nature of the challenges facing them. By sorting problems from simple to chaotic, your team can understand what methods are suitable for each problem and what they can do to ensure effective results.
If you are already using Liberating Structures techniques as part of your problem-solving strategy, the Agreement-Certainty Matrix can be an invaluable addition to your process. We’ve found it particularly if you are having issues with recurring problems in your organization and want to go deeper in understanding the root cause.
Agreement-Certainty Matrix #issue analysis #liberating structures #problem solving You can help individuals or groups avoid the frequent mistake of trying to solve a problem with methods that are not adapted to the nature of their challenge. The combination of two questions makes it possible to easily sort challenges into four categories: simple, complicated, complex , and chaotic . A problem is simple when it can be solved reliably with practices that are easy to duplicate. It is complicated when experts are required to devise a sophisticated solution that will yield the desired results predictably. A problem is complex when there are several valid ways to proceed but outcomes are not predictable in detail. Chaotic is when the context is too turbulent to identify a path forward. A loose analogy may be used to describe these differences: simple is like following a recipe, complicated like sending a rocket to the moon, complex like raising a child, and chaotic is like the game “Pin the Tail on the Donkey.” The Liberating Structures Matching Matrix in Chapter 5 can be used as the first step to clarify the nature of a challenge and avoid the mismatches between problems and solutions that are frequently at the root of chronic, recurring problems.
Organizing and charting a team’s progress can be important in ensuring its success. SQUID (Sequential Question and Insight Diagram) is a great model that allows a team to effectively switch between giving questions and answers and develop the skills they need to stay on track throughout the process.
Begin with two different colored sticky notes – one for questions and one for answers – and with your central topic (the head of the squid) on the board. Ask the group to first come up with a series of questions connected to their best guess of how to approach the topic. Ask the group to come up with answers to those questions, fix them to the board and connect them with a line. After some discussion, go back to question mode by responding to the generated answers or other points on the board.
It’s rewarding to see a diagram grow throughout the exercise, and a completed SQUID can provide a visual resource for future effort and as an example for other teams.
SQUID #gamestorming #project planning #issue analysis #problem solving When exploring an information space, it’s important for a group to know where they are at any given time. By using SQUID, a group charts out the territory as they go and can navigate accordingly. SQUID stands for Sequential Question and Insight Diagram.
16. Speed Boat
To continue with our nautical theme, Speed Boat is a short and sweet activity that can help a team quickly identify what employees, clients or service users might have a problem with and analyze what might be standing in the way of achieving a solution.
Methods that allow for a group to make observations, have insights and obtain those eureka moments quickly are invaluable when trying to solve complex problems.
In Speed Boat, the approach is to first consider what anchors and challenges might be holding an organization (or boat) back. Bonus points if you are able to identify any sharks in the water and develop ideas that can also deal with competitors!
Speed Boat #gamestorming #problem solving #action Speedboat is a short and sweet way to identify what your employees or clients don’t like about your product/service or what’s standing in the way of a desired goal.
17. The Journalistic Six
Some of the most effective ways of solving problems is by encouraging teams to be more inclusive and diverse in their thinking.
Based on the six key questions journalism students are taught to answer in articles and news stories, The Journalistic Six helps create teams to see the whole picture. By using who, what, when, where, why, and how to facilitate the conversation and encourage creative thinking, your team can make sure that the problem identification and problem analysis stages of the are covered exhaustively and thoughtfully. Reporter’s notebook and dictaphone optional.
The Journalistic Six – Who What When Where Why How #idea generation #issue analysis #problem solving #online #creative thinking #remote-friendly A questioning method for generating, explaining, investigating ideas.
18. LEGO Challenge
Now for an activity that is a little out of the (toy) box. LEGO Serious Play is a facilitation methodology that can be used to improve creative thinking and problem-solving skills.
The LEGO Challenge includes giving each member of the team an assignment that is hidden from the rest of the group while they create a structure without speaking.
What the LEGO challenge brings to the table is a fun working example of working with stakeholders who might not be on the same page to solve problems. Also, it’s LEGO! Who doesn’t love LEGO!
LEGO Challenge #hyperisland #team A team-building activity in which groups must work together to build a structure out of LEGO, but each individual has a secret “assignment” which makes the collaborative process more challenging. It emphasizes group communication, leadership dynamics, conflict, cooperation, patience and problem solving strategy.
19. What, So What, Now What?
If not carefully managed, the problem identification and problem analysis stages of the problem-solving process can actually create more problems and misunderstandings.
The What, So What, Now What? problem-solving activity is designed to help collect insights and move forward while also eliminating the possibility of disagreement when it comes to identifying, clarifying, and analyzing organizational or work problems.
Facilitation is all about bringing groups together so that might work on a shared goal and the best problem-solving strategies ensure that teams are aligned in purpose, if not initially in opinion or insight.
Throughout the three steps of this game, you give everyone on a team to reflect on a problem by asking what happened, why it is important, and what actions should then be taken.
This can be a great activity for bringing our individual perceptions about a problem or challenge and contextualizing it in a larger group setting. This is one of the most important problem-solving skills you can bring to your organization.
W³ – What, So What, Now What? #issue analysis #innovation #liberating structures You can help groups reflect on a shared experience in a way that builds understanding and spurs coordinated action while avoiding unproductive conflict. It is possible for every voice to be heard while simultaneously sifting for insights and shaping new direction. Progressing in stages makes this practical—from collecting facts about What Happened to making sense of these facts with So What and finally to what actions logically follow with Now What . The shared progression eliminates most of the misunderstandings that otherwise fuel disagreements about what to do. Voila!
20. Journalists
Problem analysis can be one of the most important and decisive stages of all problem-solving tools. Sometimes, a team can become bogged down in the details and are unable to move forward.
Journalists is an activity that can avoid a group from getting stuck in the problem identification or problem analysis stages of the process.
In Journalists, the group is invited to draft the front page of a fictional newspaper and figure out what stories deserve to be on the cover and what headlines those stories will have. By reframing how your problems and challenges are approached, you can help a team move productively through the process and be better prepared for the steps to follow.
Journalists #vision #big picture #issue analysis #remote-friendly This is an exercise to use when the group gets stuck in details and struggles to see the big picture. Also good for defining a vision.
Problem-solving techniques for developing solutions
The success of any problem-solving process can be measured by the solutions it produces. After you’ve defined the issue, explored existing ideas, and ideated, it’s time to narrow down to the correct solution.
Use these problem-solving techniques when you want to help your team find consensus, compare possible solutions, and move towards taking action on a particular problem.
- Improved Solutions
- Four-Step Sketch
- 15% Solutions
- How-Now-Wow matrix
- Impact Effort Matrix
21. Mindspin
Brainstorming is part of the bread and butter of the problem-solving process and all problem-solving strategies benefit from getting ideas out and challenging a team to generate solutions quickly.
With Mindspin, participants are encouraged not only to generate ideas but to do so under time constraints and by slamming down cards and passing them on. By doing multiple rounds, your team can begin with a free generation of possible solutions before moving on to developing those solutions and encouraging further ideation.
This is one of our favorite problem-solving activities and can be great for keeping the energy up throughout the workshop. Remember the importance of helping people become engaged in the process – energizing problem-solving techniques like Mindspin can help ensure your team stays engaged and happy, even when the problems they’re coming together to solve are complex.
MindSpin #teampedia #idea generation #problem solving #action A fast and loud method to enhance brainstorming within a team. Since this activity has more than round ideas that are repetitive can be ruled out leaving more creative and innovative answers to the challenge.
22. Improved Solutions
After a team has successfully identified a problem and come up with a few solutions, it can be tempting to call the work of the problem-solving process complete. That said, the first solution is not necessarily the best, and by including a further review and reflection activity into your problem-solving model, you can ensure your group reaches the best possible result.
One of a number of problem-solving games from Thiagi Group, Improved Solutions helps you go the extra mile and develop suggested solutions with close consideration and peer review. By supporting the discussion of several problems at once and by shifting team roles throughout, this problem-solving technique is a dynamic way of finding the best solution.
Improved Solutions #creativity #thiagi #problem solving #action #team You can improve any solution by objectively reviewing its strengths and weaknesses and making suitable adjustments. In this creativity framegame, you improve the solutions to several problems. To maintain objective detachment, you deal with a different problem during each of six rounds and assume different roles (problem owner, consultant, basher, booster, enhancer, and evaluator) during each round. At the conclusion of the activity, each player ends up with two solutions to her problem.
23. Four Step Sketch
Creative thinking and visual ideation does not need to be confined to the opening stages of your problem-solving strategies. Exercises that include sketching and prototyping on paper can be effective at the solution finding and development stage of the process, and can be great for keeping a team engaged.
By going from simple notes to a crazy 8s round that involves rapidly sketching 8 variations on their ideas before then producing a final solution sketch, the group is able to iterate quickly and visually. Problem-solving techniques like Four-Step Sketch are great if you have a group of different thinkers and want to change things up from a more textual or discussion-based approach.
Four-Step Sketch #design sprint #innovation #idea generation #remote-friendly The four-step sketch is an exercise that helps people to create well-formed concepts through a structured process that includes: Review key information Start design work on paper, Consider multiple variations , Create a detailed solution . This exercise is preceded by a set of other activities allowing the group to clarify the challenge they want to solve. See how the Four Step Sketch exercise fits into a Design Sprint
24. 15% Solutions
Some problems are simpler than others and with the right problem-solving activities, you can empower people to take immediate actions that can help create organizational change.
Part of the liberating structures toolkit, 15% solutions is a problem-solving technique that focuses on finding and implementing solutions quickly. A process of iterating and making small changes quickly can help generate momentum and an appetite for solving complex problems.
Problem-solving strategies can live and die on whether people are onboard. Getting some quick wins is a great way of getting people behind the process.
It can be extremely empowering for a team to realize that problem-solving techniques can be deployed quickly and easily and delineate between things they can positively impact and those things they cannot change.
15% Solutions #action #liberating structures #remote-friendly You can reveal the actions, however small, that everyone can do immediately. At a minimum, these will create momentum, and that may make a BIG difference. 15% Solutions show that there is no reason to wait around, feel powerless, or fearful. They help people pick it up a level. They get individuals and the group to focus on what is within their discretion instead of what they cannot change. With a very simple question, you can flip the conversation to what can be done and find solutions to big problems that are often distributed widely in places not known in advance. Shifting a few grains of sand may trigger a landslide and change the whole landscape.
25. How-Now-Wow Matrix
The problem-solving process is often creative, as complex problems usually require a change of thinking and creative response in order to find the best solutions. While it’s common for the first stages to encourage creative thinking, groups can often gravitate to familiar solutions when it comes to the end of the process.
When selecting solutions, you don’t want to lose your creative energy! The How-Now-Wow Matrix from Gamestorming is a great problem-solving activity that enables a group to stay creative and think out of the box when it comes to selecting the right solution for a given problem.
Problem-solving techniques that encourage creative thinking and the ideation and selection of new solutions can be the most effective in organisational change. Give the How-Now-Wow Matrix a go, and not just for how pleasant it is to say out loud.
How-Now-Wow Matrix #gamestorming #idea generation #remote-friendly When people want to develop new ideas, they most often think out of the box in the brainstorming or divergent phase. However, when it comes to convergence, people often end up picking ideas that are most familiar to them. This is called a ‘creative paradox’ or a ‘creadox’. The How-Now-Wow matrix is an idea selection tool that breaks the creadox by forcing people to weigh each idea on 2 parameters.
26. Impact and Effort Matrix
All problem-solving techniques hope to not only find solutions to a given problem or challenge but to find the best solution. When it comes to finding a solution, groups are invited to put on their decision-making hats and really think about how a proposed idea would work in practice.
The Impact and Effort Matrix is one of the problem-solving techniques that fall into this camp, empowering participants to first generate ideas and then categorize them into a 2×2 matrix based on impact and effort.
Activities that invite critical thinking while remaining simple are invaluable. Use the Impact and Effort Matrix to move from ideation and towards evaluating potential solutions before then committing to them.
Impact and Effort Matrix #gamestorming #decision making #action #remote-friendly In this decision-making exercise, possible actions are mapped based on two factors: effort required to implement and potential impact. Categorizing ideas along these lines is a useful technique in decision making, as it obliges contributors to balance and evaluate suggested actions before committing to them.
27. Dotmocracy
If you’ve followed each of the problem-solving steps with your group successfully, you should move towards the end of your process with heaps of possible solutions developed with a specific problem in mind. But how do you help a group go from ideation to putting a solution into action?
Dotmocracy – or Dot Voting -is a tried and tested method of helping a team in the problem-solving process make decisions and put actions in place with a degree of oversight and consensus.
One of the problem-solving techniques that should be in every facilitator’s toolbox, Dot Voting is fast and effective and can help identify the most popular and best solutions and help bring a group to a decision effectively.
Dotmocracy #action #decision making #group prioritization #hyperisland #remote-friendly Dotmocracy is a simple method for group prioritization or decision-making. It is not an activity on its own, but a method to use in processes where prioritization or decision-making is the aim. The method supports a group to quickly see which options are most popular or relevant. The options or ideas are written on post-its and stuck up on a wall for the whole group to see. Each person votes for the options they think are the strongest, and that information is used to inform a decision.
All facilitators know that warm-ups and icebreakers are useful for any workshop or group process. Problem-solving workshops are no different.
Use these problem-solving techniques to warm up a group and prepare them for the rest of the process. Activating your group by tapping into some of the top problem-solving skills can be one of the best ways to see great outcomes from your session.
- Check-in/Check-out
- Doodling Together
- Show and Tell
- Constellations
- Draw a Tree
28. Check-in / Check-out
Solid processes are planned from beginning to end, and the best facilitators know that setting the tone and establishing a safe, open environment can be integral to a successful problem-solving process.
Check-in / Check-out is a great way to begin and/or bookend a problem-solving workshop. Checking in to a session emphasizes that everyone will be seen, heard, and expected to contribute.
If you are running a series of meetings, setting a consistent pattern of checking in and checking out can really help your team get into a groove. We recommend this opening-closing activity for small to medium-sized groups though it can work with large groups if they’re disciplined!
Check-in / Check-out #team #opening #closing #hyperisland #remote-friendly Either checking-in or checking-out is a simple way for a team to open or close a process, symbolically and in a collaborative way. Checking-in/out invites each member in a group to be present, seen and heard, and to express a reflection or a feeling. Checking-in emphasizes presence, focus and group commitment; checking-out emphasizes reflection and symbolic closure.
29. Doodling Together
Thinking creatively and not being afraid to make suggestions are important problem-solving skills for any group or team, and warming up by encouraging these behaviors is a great way to start.
Doodling Together is one of our favorite creative ice breaker games – it’s quick, effective, and fun and can make all following problem-solving steps easier by encouraging a group to collaborate visually. By passing cards and adding additional items as they go, the workshop group gets into a groove of co-creation and idea development that is crucial to finding solutions to problems.
Doodling Together #collaboration #creativity #teamwork #fun #team #visual methods #energiser #icebreaker #remote-friendly Create wild, weird and often funny postcards together & establish a group’s creative confidence.
30. Show and Tell
You might remember some version of Show and Tell from being a kid in school and it’s a great problem-solving activity to kick off a session.
Asking participants to prepare a little something before a workshop by bringing an object for show and tell can help them warm up before the session has even begun! Games that include a physical object can also help encourage early engagement before moving onto more big-picture thinking.
By asking your participants to tell stories about why they chose to bring a particular item to the group, you can help teams see things from new perspectives and see both differences and similarities in the way they approach a topic. Great groundwork for approaching a problem-solving process as a team!
Show and Tell #gamestorming #action #opening #meeting facilitation Show and Tell taps into the power of metaphors to reveal players’ underlying assumptions and associations around a topic The aim of the game is to get a deeper understanding of stakeholders’ perspectives on anything—a new project, an organizational restructuring, a shift in the company’s vision or team dynamic.
31. Constellations
Who doesn’t love stars? Constellations is a great warm-up activity for any workshop as it gets people up off their feet, energized, and ready to engage in new ways with established topics. It’s also great for showing existing beliefs, biases, and patterns that can come into play as part of your session.
Using warm-up games that help build trust and connection while also allowing for non-verbal responses can be great for easing people into the problem-solving process and encouraging engagement from everyone in the group. Constellations is great in large spaces that allow for movement and is definitely a practical exercise to allow the group to see patterns that are otherwise invisible.
Constellations #trust #connection #opening #coaching #patterns #system Individuals express their response to a statement or idea by standing closer or further from a central object. Used with teams to reveal system, hidden patterns, perspectives.
32. Draw a Tree
Problem-solving games that help raise group awareness through a central, unifying metaphor can be effective ways to warm-up a group in any problem-solving model.
Draw a Tree is a simple warm-up activity you can use in any group and which can provide a quick jolt of energy. Start by asking your participants to draw a tree in just 45 seconds – they can choose whether it will be abstract or realistic.
Once the timer is up, ask the group how many people included the roots of the tree and use this as a means to discuss how we can ignore important parts of any system simply because they are not visible.
All problem-solving strategies are made more effective by thinking of problems critically and by exposing things that may not normally come to light. Warm-up games like Draw a Tree are great in that they quickly demonstrate some key problem-solving skills in an accessible and effective way.
Draw a Tree #thiagi #opening #perspectives #remote-friendly With this game you can raise awarness about being more mindful, and aware of the environment we live in.
Each step of the problem-solving workshop benefits from an intelligent deployment of activities, games, and techniques. Bringing your session to an effective close helps ensure that solutions are followed through on and that you also celebrate what has been achieved.
Here are some problem-solving activities you can use to effectively close a workshop or meeting and ensure the great work you’ve done can continue afterward.
- One Breath Feedback
- Who What When Matrix
- Response Cards
How do I conclude a problem-solving process?
All good things must come to an end. With the bulk of the work done, it can be tempting to conclude your workshop swiftly and without a moment to debrief and align. This can be problematic in that it doesn’t allow your team to fully process the results or reflect on the process.
At the end of an effective session, your team will have gone through a process that, while productive, can be exhausting. It’s important to give your group a moment to take a breath, ensure that they are clear on future actions, and provide short feedback before leaving the space.
The primary purpose of any problem-solving method is to generate solutions and then implement them. Be sure to take the opportunity to ensure everyone is aligned and ready to effectively implement the solutions you produced in the workshop.
Remember that every process can be improved and by giving a short moment to collect feedback in the session, you can further refine your problem-solving methods and see further success in the future too.
33. One Breath Feedback
Maintaining attention and focus during the closing stages of a problem-solving workshop can be tricky and so being concise when giving feedback can be important. It’s easy to incur “death by feedback” should some team members go on for too long sharing their perspectives in a quick feedback round.
One Breath Feedback is a great closing activity for workshops. You give everyone an opportunity to provide feedback on what they’ve done but only in the space of a single breath. This keeps feedback short and to the point and means that everyone is encouraged to provide the most important piece of feedback to them.
One breath feedback #closing #feedback #action This is a feedback round in just one breath that excels in maintaining attention: each participants is able to speak during just one breath … for most people that’s around 20 to 25 seconds … unless of course you’ve been a deep sea diver in which case you’ll be able to do it for longer.
34. Who What When Matrix
Matrices feature as part of many effective problem-solving strategies and with good reason. They are easily recognizable, simple to use, and generate results.
The Who What When Matrix is a great tool to use when closing your problem-solving session by attributing a who, what and when to the actions and solutions you have decided upon. The resulting matrix is a simple, easy-to-follow way of ensuring your team can move forward.
Great solutions can’t be enacted without action and ownership. Your problem-solving process should include a stage for allocating tasks to individuals or teams and creating a realistic timeframe for those solutions to be implemented or checked out. Use this method to keep the solution implementation process clear and simple for all involved.
Who/What/When Matrix #gamestorming #action #project planning With Who/What/When matrix, you can connect people with clear actions they have defined and have committed to.
35. Response cards
Group discussion can comprise the bulk of most problem-solving activities and by the end of the process, you might find that your team is talked out!
Providing a means for your team to give feedback with short written notes can ensure everyone is head and can contribute without the need to stand up and talk. Depending on the needs of the group, giving an alternative can help ensure everyone can contribute to your problem-solving model in the way that makes the most sense for them.
Response Cards is a great way to close a workshop if you are looking for a gentle warm-down and want to get some swift discussion around some of the feedback that is raised.
Response Cards #debriefing #closing #structured sharing #questions and answers #thiagi #action It can be hard to involve everyone during a closing of a session. Some might stay in the background or get unheard because of louder participants. However, with the use of Response Cards, everyone will be involved in providing feedback or clarify questions at the end of a session.
Save time and effort discovering the right solutions
A structured problem solving process is a surefire way of solving tough problems, discovering creative solutions and driving organizational change. But how can you design for successful outcomes?
With SessionLab, it’s easy to design engaging workshops that deliver results. Drag, drop and reorder blocks to build your agenda. When you make changes or update your agenda, your session timing adjusts automatically , saving you time on manual adjustments.
Collaborating with stakeholders or clients? Share your agenda with a single click and collaborate in real-time. No more sending documents back and forth over email.
Explore how to use SessionLab to design effective problem solving workshops or watch this five minute video to see the planner in action!

Over to you
The problem-solving process can often be as complicated and multifaceted as the problems they are set-up to solve. With the right problem-solving techniques and a mix of creative exercises designed to guide discussion and generate purposeful ideas, we hope we’ve given you the tools to find the best solutions as simply and easily as possible.
Is there a problem-solving technique that you are missing here? Do you have a favorite activity or method you use when facilitating? Let us know in the comments below, we’d love to hear from you!

thank you very much for these excellent techniques

Certainly wonderful article, very detailed. Shared!
Leave a Comment Cancel reply
Your email address will not be published. Required fields are marked *

Going from a mere idea to a workshop that delivers results for your clients can feel like a daunting task. In this piece, we will shine a light on all the work behind the scenes and help you learn how to plan a workshop from start to finish. On a good day, facilitation can feel like effortless magic, but that is mostly the result of backstage work, foresight, and a lot of careful planning. Read on to learn a step-by-step approach to breaking the process of planning a workshop into small, manageable chunks. The flow starts with the first meeting with a client to define the purposes of a workshop.…

How does learning work? A clever 9-year-old once told me: “I know I am learning something new when I am surprised.” The science of adult learning tells us that, in order to learn new skills (which, unsurprisingly, is harder for adults to do than kids) grown-ups need to first get into a specific headspace. In a business, this approach is often employed in a training session where employees learn new skills or work on professional development. But how do you ensure your training is effective? In this guide, we'll explore how to create an effective training session plan and run engaging training sessions. As team leader, project manager, or consultant,…

Effective online tools are a necessity for smooth and engaging virtual workshops and meetings. But how do you choose the right ones? Do you sometimes feel that the good old pen and paper or MS Office toolkit and email leaves you struggling to stay on top of managing and delivering your workshop? Fortunately, there are plenty of online tools to make your life easier when you need to facilitate a meeting and lead workshops. In this post, we’ll share our favorite online tools you can use to make your job as a facilitator easier. In fact, there are plenty of free online workshop tools and meeting facilitation software you can…
Design your next workshop with SessionLab
Join the 150,000 facilitators using SessionLab
Sign up for free
Using learners’ problem-solving processes in computer-based assessments for enhanced learner modeling: A deep learning approach
- Open access
- Published: 22 December 2023
Cite this article
You have full access to this open access article
- Fu Chen ORCID: orcid.org/0000-0002-9073-5267 1 , 2 ,
- Chang Lu 3 &
- Ying Cui 4
634 Accesses
Explore all metrics
Successful computer-based assessments for learning greatly rely on an effective learner modeling approach to analyze learner data and evaluate learner behaviors. In addition to explicit learning performance (i.e., product data), the process data logged by computer-based assessments provide a treasure trove of information about how learners solve assessment questions. Unfortunately, how to make the best use of both product and process data to sequentially model learning behaviors is still under investigation. This study proposes a novel deep learning-based approach for enhanced learner modeling that can sequentially predict learners’ future learning performance (i.e., item responses) based on modeling their history learning behaviors. The evaluation results show that the proposed model outperforms another popular deep learning-based learner model, and process data learning of the model contributes to improved prediction performance. In addition, the model can be used to discover the mapping of items to skills from scratch without prior expert knowledge. Our study showcases how product and process data can be modelled under the same framework for enhanced learner modeling. It offers a novel approach for learning evaluation in the context of computer-based assessments.
Similar content being viewed by others

Machine learning and deep learning
Christian Janiesch, Patrick Zschech & Kai Heinrich

Review of deep learning: concepts, CNN architectures, challenges, applications, future directions
Laith Alzubaidi, Jinglan Zhang, … Laith Farhan

Artificial intelligence in online higher education: A systematic review of empirical research from 2011 to 2020
Fan Ouyang, Luyi Zheng & Pengcheng Jiao
Avoid common mistakes on your manuscript.
1 Introduction
Analytics of big data in education for enhanced teaching and learning has gained increasing attention over the past years. Advanced by the rapid evolution in information and communication technologies, integrating big data and adaptive learning systems has given rise to a growing personalized learning movement that can tackle conventional educational challenges (Dishon, 2017 ). Personalized learning benefits learners in multiple ways — learning can be customized, gamified, self-directed, collaborative, and, notably, much more accessible and affordable than traditional learning.
In a personalized learning system, customized learning plans are typically created for learners based on what they know, what they lack, and how they learn best. This requires that data on learning behaviors can be tracked, logged, retrieved, and modelled by digital learning environments. A typical scenario where personalized learning is situated is computer-based assessments (CBAs) for learning, widely used to evaluate and promote learning performance in various learning contexts (Shute & Rahimi, 2017 ). The popularity and effectiveness of CBAs for personalized learning are attributable to their capacities to evaluate higher-level learner competencies and their flexibility in assessment administration. Moreover, from the data perspective, compared with standardized paper–pencil assessments, CBAs can elicit and collect much more information about how learners perform on and solve each learning task. This enables education practitioners to better evaluate and validate an assessment and to provide learners with finer-grained feedback. Therefore, this study situates the proposed model in the context of CBA for learning.
Making inferences about learners’ knowledge states or skill levels based on learners’ interactions with learning resources and assessment questions, or learner modeling, is indispensable for an effective CBA. Research on analytics of the two forms of learner data— product and process data—from learners’ interactions with CBAs has received increasing attention from communities of educational data mining and educational assessment (Mislevy et al., 2012 ; Rupp et al., 2012 ). Product data mainly include final work products interacting with CBAs (e.g., success or failure on assessment tasks and scores of assessment questions). Process data, often represented by log file entries, store the information on learners’ problem-solving processes relevant to their final work products (Rupp et al., 2012 ). Over the past decades, to make the best use of learner product data, tremendous research efforts have been devoted to developing various models and analytic approaches for learner modeling. For example, Bayesian knowledge tracing (BKT; Corbett & Anderson, 1994 ) is a popular learner model to evaluate and track learners’ cognitive states in intelligent tutoring systems (Psotka et al., 1988 ). In educational measurement, item response theory (IRT; Lord, 1952 ) models and cognitive diagnosis models (CDM; Tatsuoka, 1990 ) are two representative families of modern psychometric techniques analyzing learners’ item responses to infer their latent skill levels. Despite their popularity, these mainstream approaches are mainly applicable to product data and are limited in addressing learner process data. Unlike product data, which are often explicit and structured, process data are inherently unstructured with much noise. However, process data is of great potential to reveal a wealth of information on how learners interact with assessments and what contributes to their final working products. As such, in the communities of educational assessment and educational data mining, in recent years, utilizing process data to profile, evaluate and facilitate learning has been an emerging research topic. For example, analytics of process data in the context of CBAs has been used to predict learners’ problem-solving outcomes (Chen et al., 2019 ), probe learners’ problem-solving strategies (Greiff et al., 2015 ), and assess learners’ latent skills (Liu et al., 2018 ). These pioneering studies have shed light on the potential of process data to promote our understanding of how learners approach complex assessment tasks. Nevertheless, the existing approaches are often not generalizable to other CBA settings since they were primarily developed for case studies. There is an urgent need for generic approaches for learner modeling with process data in the context of CBAs.
In recent years, machine learning advances, especially deep learning techniques, have fostered new paradigms of learner data analytics. Machine learning-based approaches for learner modeling are highly scalable and strongly predictive, which greatly benefit large-scale applications of CBAs (e.g., Bergner et al., 2012 ; Cheng et al., 2019 ; Lan et al., 2014 ). Compared with conventional approaches, they are more capable of handling unstructured and incomplete learner data and addressing tremendous amounts of items and learners in large-scale settings. For example, due to their personalized learning nature, most CBAs allow learners access to subsets of assessment items from the item bank. As such, learner data logged by such CBAs are often of large volume and extreme sparseness. To address this, for example, collaborative filtering (CF), a technique widely used for recommender systems, is exceptionally effective for inferring learners’ cognitive states or skill levels based on sparse learner data (e.g., Chen et al., 2023 ). Moreover, to capture a higher degree of complexity of learner data, informed by research from other domains (e.g., He et al., 2017 ; Zhang et al., 2016 ), deep learning techniques can be used for enhanced learner modeling through exploiting additional learner and item information or improving the intricacy of model architectures. Unfortunately, to our best knowledge, despite existing deep learning-based approaches (e.g., deep knowledge tracing [DKT]; Piech et al., 2015 ), theoretical and empirical studies on deep learning approaches for learner modeling applicable to process data in the context of CBAs remain sparse. Considering their modeling flexibility and predictive capacity evidenced by existing studies in other domains, in our study, we attempt to investigate how deep learning-based approaches can be used to address process data for enhanced learner modeling and examine if they are advantageous over conventional approaches.
Specifically, the key objective of the present study is to develop a deep learning-based approach capable of modeling both product and process data for enhanced learner modeling. We attempt to address several specific issues with respect to CBAs for learning in the current study. First, since learners’ skill levels improve as they continuously interact with a learning system, the proposed model should address the temporal dependencies between learner-item interactions (i.e., it is a sequential modeling approach). Second, in addition to predicting learners’ performance on unseen items (e.g., item responses to unseen items), the proposed model is expected to be capable of discovering the mapping of items to the targeted latent skills (i.e., item-skill associations). That is, under the assumption that a set of underlying skills affect how learners respond to assessment items, efforts from domain experts in tagging assessment items with skill labels can be less needed if the proposed model can automatically estimate item-skill associations. Finally, given the potential of process data to reflect learners’ efforts in attempting assessment questions, the proposed model should be capable of capturing the latent representations of process data to improve the prediction performance. To achieve these, in this study, we proposed a novel deep learning-based approach that can address both product and process data for learner modeling based on deep neural networks, long short-term memory (LSTM) networks, and the attention mechanism. More concretely, the LSTM networks are adopted to capture the temporal dependencies between learner-item interactions and between learners’ problem-solving actions; the deep neural networks are adopted to capture the latent representations of learners and items as well as their interactions; and the self-attention mechanism is adopted to estimate the mapping of items to skills from scratch.
In summary, our work makes the following contribution to the literature.
We investigate the possibility of using deep learning as technical underpinnings for enhanced learner modeling, which has rarely been investigated in previous studies.
We attempt to develop an approach that can deal with both product and process data for learner modelling in the context of CBAs.
We attempt to develop an approach with the potential of automatically discovering item-skill associations without expert knowledge. This might benefit large-scale CBA scenarios by reducing human efforts in prespecifying the mapping of items to skills.
2 Literature review
2.1 existing approaches for learner modeling.
In educational measurement, two families of modern psychometric models —IRT and CDMs — are widely used to model the process of learners responding to assessment items measuring one or multiple underlying skills. Psychometric models estimate learners’ latent skill levels and item parameters characterizing item features (e.g., difficulty and discrimination). In contrast to computational approaches, psychometric models rely on strong theoretical assumptions regarding the associations of skill mastery with item responses. For example, standard IRT models only allow one latent skill to be measured (i.e., unidimensionality), making them inadequate in addressing multiple skills. Learner modeling by CDMs requires a pre-specified human-labelled mapping of items to latent skills, failing to address CBAs with many assessment items. In addition, unlike computational approaches, constrained by their theoretical assumptions, psychometric models, without sophisticated model revisions, have limited capacity to discover how assessment items associate with targeted latent skills from scratch. This feature of learner modeling, however, benefits large-scale CBAs since human efforts in defining item-skill associations are less needed. Moreover, psychometric models are mostly used in conventional standardized assessments in which learner data is typically structured, clean, and complete. However, learners may interact with different subsets of CBA items asynchronously. As such, learner data may be of unequal sequence lengths and with much randomness and noise. Therefore, conventional psychometric models are not scalable enough to model large-scale learner data. Finally, since learning occurs as learners continuously interact with CBA items, learner modeling without accounting for how previous learning outcomes affect current and future learning might overlook the dynamic changes in learners’ cognitive states. Unfortunately, given that psychometric models typically require the assumption of local independence (i.e., conditional on latent skill levels, item responses are independent of each other), they are limited in modeling the temporal dependencies between item responses.
Bayesian approaches have also been widely used for learner modeling, since they are computationally sound, and highly flexible and expressive (Desmarais et al., 2012 ). Particularly, Bayesian networks, a type of probabilistic graphic model that graphically represents a joint distribution of random variables (Koller & Friedman, 2009 ), are of great popularity for learner modeling (de Klerk et al., 2015 ). To address the dynamic changes in cognitive states across multiple CBA items, variants of Bayesian networks with a temporal dimension — dynamic Bayesian networks (DBNs) and its special case BKT — were developed to estimate and update learners’ skill levels as learning progresses. In empirical studies, Bayesian networks and their variants have been used for learner modeling in CBAs assessing high-level skills (e.g., creative problem solving, Shute et al., 2009 ; 21st-century skills, Shute & Ventura, 2013 ) and knowledge and skills in science and mathematics (e.g., Cui et al., 2019 ; Levy, 2014 ). Despite their popularity, learner modeling with Bayesian approaches in CBAs suffers from the curse of dimensionality — a great number of items and skills may lead to highly complex computations of conditional probabilities. In addition, similar to psychometric models, standard Bayesian approaches typically require the mapping of items to skills to be prespecified so that they cannot be directly used for automatic discovery of item-skill associations.
Another strand of educational data mining research has focused on adapting CF techniques for learner modeling. Initially developed and used for recommender systems, the CF technique has gained increasing popularity in modeling educational data in recent years (e.g., Almutairi et al., 2017 ; Desmarais & Naceur, 2013 ; Durand et al., 2015 ; Lan et al., 2014 ; Matsuda et al., 2015 ). For example, matrix factorization, a model-based CF approach, is of great potential for learner modeling because of its effectiveness in recovering unknown user-item interactions given sparse user data. It should be noted that most CF research in educational data mining mainly focused on employing CF to evaluate, discover, or refine the mapping of items to skills (e.g., Desmarais, 2012 ; Desmarais & Naceur, 2013 ; Durand et al., 2015 ; Lan et al., 2014 ; Matsuda et al., 2015 ; Sun et al., 2014 ). For example, the data-driven item-skill associations by CF-based approaches were close to or even outperformed the expert-specified ones (Desmarais & Naceur, 2013 ; Matsuda et al., 2015 ; Sun et al., 2014 ). In summary, the literature highlights the potential of CF approaches for learner modeling and their capacity to learn item-skill associations from the scratch.
2.2 Deep learning approaches for learner modeling
Recently, deep learning-based approaches have proven exceptionally effective in predicting learners’ unknown or future learning outcomes. Learner modeling with deep learning is essentially a supervised learning problem — based on various inputs regarding learners, items, and learning contexts, a deep learning model outputs the predictions of learners’ unknown or future item responses (e.g., probabilities of succeeding on unknown or future items). Notably, the variety of deep learning architectures (e.g., deep neural networks and recurrent neural networks [RNNs]) allows the flexibility of deep learning approaches in addressing complex learner data. For example, previous studies have exploited the side information of learners and items (e.g., item context and learner background) to improve the accuracy of learner modeling with convolutional neural networks or RNNs (Chaplot et al., 2018 ; Cheng et al., 2019 ; Su et al., 2018 ). Particularly, DKT (Piech et al., 2015 ), an RNN-based learner modeling approach, is exceptionally effective in accounting for the temporal dependencies between item responses. The advantages of DKT and its variants in learner modeling over conventional learner models have been well documented in the literature (e.g., Wang et al., 2017 ; Xiong et al., 2016 ; Yeung, 2019 ; Yeung & Yeung, 2018 ).
More recently, researchers have incorporated deep learning architectures into the CF framework for improved learner modeling (e.g., Chen et al., 2023 ). Deep learning-based CF approaches can capture a high degree of complexity (e.g., non-linearity) of learner-item interactions through deep neural networks. For example, multiple neural network layers can be used to learner item and user vectors, resulting in enhanced prediction performance through strong item and learner representations (e.g., He et al., 2017 ; Nguyen et al., 2018 ). The inclusion of deep learning architectures largely improves the prediction performance of conventional CF methods because they have a strong capacity to learn finer-grained representations and auxiliary information of users and items. However, the effectiveness of deep learning-based CF approaches for learner modeling in the CBA context remains under-investigated.
2.3 Learner modeling with process data
As mentioned, a few case studies exist showing how process data analytics can inform learning in the CBA settings. For instance, Greiff et al. ( 2015 ) analyzed the process data of one question on complex problem-solving in PISA 2012 to identify learners’ problem-solving strategies. They extracted a set of frequency-related and time-related features from the process data and examined how these features predicted learners’ problem-solving success. Notably, they identified a dominant strategy for solving the question. However, their analyses were conducted in an exploratory fashion with only one item, which is not scalable and extendable in other settings. With the data of an item from the same assessment, Liu et al., ( 2018 ) proposed to use a modified multilevel mixture IRT model to analyze learners’ process data, which identified different latent classes of problem-solving strategies and estimated learners’ abilities at both the process and item levels. Their approach was also examined with the data of one item and showed limited generalizability. The PISA dataset was also analyzed by the event history analysis model proposed by Chen et al., ( 2019 ). Their approach was developed to model the problem-solving process with the aim of predicting both the remaining time a learner needs to complete the item and the final problem-solving outcomes (success or failure). However, their approach suffers the limitation of single-item analysis as well, which cannot be well extended to multiple-item analysis. Similarly, Shu et al., ( 2017 ) proposed a Markov-IRT model to extract features from learners’ problem-solving processes as evidence for psychometric measurement. However, the Markov property assumed by their approach limits the temporal dependencies in problem-solving between two consecutive actions.
More recently, Tang et al., ( 2021 ) proposed a more generalizable approach for extracting informative features from learners’ action sequences in solving a problem based on the sequence-to-sequence autoencoder. The learned latent features indicate how learners attempt a problem, which can be used for subsequent statistical or machine-learning analysis. Essentially, their approach is the representation learning of action sequences. However, it is limited in dealing with multiple items simultaneously and modeling the time information. Moreover, in terms of learner modeling or other predictive analyses, a sophisticated model is still needed to connect representation learning of action sequences with different model architectures.
In summary, the existing approaches for learner modeling with process data were mainly developed and examined in specific contexts, and they often fail to deal with multiple items. Moreover, some approaches heavily rely on statistical or psychometric assumptions and require human-specified rules, undermining their scalability and generalizability. Regarding learner modeling, few approaches can model item responses with process data at a large scale across multiple items.
Overall, our review of the existing literature on learner modeling concluded that deep learning-based approaches are of great potential for effective learner modeling in the context of CBAs, but this topic remains under investigated. In addition, existing deep learning-based approaches for learner modeling cannot adequately address process data. Consequently, this study aims to develop a deep learning-based approach to address product and process data for enhanced learner modeling. Specifically, the following three research questions are to be addressed in this study.
Do the proposed model and its variants show satisfactory prediction accuracy in predicting learning performance in the context of CBAs?
Does the proposed model outperform another popular deep learning-based learner model (i.e., DKT)?
Does the proposed model show good prediction performance at different levels of data availability for training?
Can the proposed model automatically discover interpretable item-skill associations?
In the following, we first introduce the proposed model with technical details. Then we describe how to evaluate the effectiveness of the proposed model with a real-world dataset.
3.1 Introduction to the proposed model
The following sections present technical details for the proposed model, starting with the problem formulation, followed by the technical details of the modeling framework.
3.1.1 Problem formulation
Suppose the approach applies to data of \(m\) independent learners interacting with an \(n\) -item assessment on \(k\) latent skills. As such, the learner-item interactions can be represented as \({\mathbf{R}}_{i}=\{({\mathbf{m}}_{i},{\mathbf{n}}_{1}^{i},{R}_{1}^{i}, {L}_{1}^{i}),({\mathbf{m}}_{i},{\mathbf{n}}_{2}^{i},{R}_{2}^{i}, {L}_{2}^{i}),\dots ,({\mathbf{m}}_{i},{\mathbf{n}}_{T}^{i},{R}_{T}^{i}, {L}_{T}^{i})\}\) , where \({\mathbf{m}}_{i}\) and \({\mathbf{n}}_{t}^{i}\) label learner identifications and item identifications at the \(t\) th timestep, respectively. Moreover, \({R}_{t}^{i}\) , taking a value of either one (correct) or zero (incorrect), denotes the learning outcome at the \(t\) th timestep, and \({L}_{t}^{i}=\{{{\varvec{a}}}_{t}^{i},{{\varvec{t}}}_{t}^{i}\}\) , consisting of an action sequence \({{\varvec{a}}}_{t}^{i}\) and a time sequence \({{\varvec{t}}}_{t}^{i}\) , denotes the problem-solving process associated with \({R}_{t}^{i}\) at the \(t\) th timestep. Given a sequence of a learner’s learner-item interactions \({\mathbf{R}}_{i}\) over \(T\) timesteps, the proposed model aims to learn a model \(\mathcal{M}\) that predicts his or her learning outcome \({\widehat{R}}_{T+1}^{i}\) on the next item \({\mathbf{n}}_{T+1}^{i}\) at the timestep \(T+1\) . In addition to predictions of future learning outcomes, the proposed model discovers the mapping of items to latent skills from the associations between items during the model training process.
3.1.2 Modeling process of the approach
Figure 1 graphically presents the architecture of the proposed model, which is of two sub-architectures: one architecture for modeling item responses and problem-solving processes and the other for predicting future item responses.

Graphical representation of the proposed model
Embeddings of items and learners
Given the raw data \({\mathbf{R}}_{i}\) , the proposed model first learns latent representations of learners and items from the identification vectors \({\mathbf{m}}_{i}\) and \({\mathbf{n}}_{t}\) through embedding layers. Specifically, the approach converts sparse vectors of learners and items to dense vectors with a pre-specified dimensionality \(k\) . As such, learner and item identifications can be represented by a \(k\) -dimensional learner representation \(\mathbf{U}=\left[{\mathbf{u}}_{1},\dots ,{\mathbf{u}}_{m}\right]\) and a \(k\) -dimensional item latent representation \(\mathbf{V}=\left[{\mathbf{v}}_{1},\dots ,{\mathbf{v}}_{n}\right]\) respectively.
Deep learning of problem-solving processes
In addition to learner and item embeddings, the process data needs to be processed and learned for sequential modeling (see Fig. 2 ). At the \(t\) th timestep, learner \({\mathbf{m}}_{i}\) responding item \({\mathbf{n}}_{t}^{i}\) produces a sequence of problem-solving actions \({{\varvec{a}}}_{t}^{i}=\{{e}_{1},{e}_{2},\dots {e}_{Q}\}\) and a sequence of action-associated time durations \({{\varvec{t}}}_{t}^{i} =\{{t}_{1},{t}_{2},\dots {t}_{Q}\}\) , where \({e}_{q}\) and \({t}_{q}\) indicate the \(q\) th problem-solving step and associated time duration. Given that \({{\varvec{a}}}_{t}^{i}\) is a vector with categorical values, the model converts each action \({e}_{q}\) to a dense vector of \({d}_{0}\) dimensions through embedding, which is then fed into an LSTM network layer for learning the time-series dependencies between actions. It should be noted that multiple LSTM layers are allowed to better capture the complexity of temporal dependencies across multiple timesteps. The LSTM networks finally produce learned representations of actions and time durations. Subsequently, the approach concatenates learned representations of actions and time durations and feeds them into a deep neural network architecture for learning the interactions between actions and time durations, producing a final learned representation of process data at the \(t\) th timestep \({\phi }_{t}^{i}\) .

Architecture for process data learning in the proposed model
Concatenating leaner-item interactions
Next, the proposed model first concatenates the latent representations of learners and items, and the latent representation of process data, resulting in a (2 \(k+{d}_{a}\) )-dimensional vector, \({\mathbf{e}}_{ij}\) . To concatenate \({\mathbf{e}}_{ij}\) with the item response \({R}_{t}^{i}\) at timestep \(t\) , since \({R}_{t}^{i}\) takes a value of either one or zero, \({\mathbf{e}}_{ij}\) is extended to a (2 \(k+{d}_{a}\) )-dimensional vector \(\bf 0=(\mathrm{0,0,\dots ,0})\) , resulting in a final concatenated vector \({\mathbf{e}}_{ij}^{t}\) as:
where \(\oplus\) indicates concatenation.
Deep learning for sequential learning
After concatenations, the model feeds \({\mathbf{e}}_{ij}^{t}\) into one or multiple LSTM network layers to learn how item responses temporally associate with each other. Mathematically, an LSTM network layer recurrently updates the hidden state of each \({\mathbf{e}}_{ij}^{t}\) at the \(t\) th timestep \({h}_{t}\) with its previous hidden state \({h}_{t-1}\) :
In the above, \({f}_{t}\) , \({i}_{t}\) and \({o}_{t}\) denotes the forget, input, and output gates within an LSTM cell respectively, \({C}_{t}\) denotes the cell state at the \(t\) th step, and \(\sigma\) and \(\mathrm{tanh}\) indicate the Sigmoid and the hyperbolic tangent activation functions respectively. In addition, \({W}_{f}\) and \({b}_{f}\) , \({W}_{i}\) and \({b}_{i}\) , and \({W}_{o}\) and \({b}_{o}\) indicate the weights and bias of the forget gate, the input gate, and the output gate respectively. In summary, the three gates of an LSTM cell control what information to be inputted, remembered, forgotten, and outputted through the cell. This feature contributes to the effectiveness of the LSTM network in learning temporal dependencies. The output sequence of the last LSTM layer \(\mathbf{S}=\{{s}_{1}^{i},{s}_{2}^{i},\dots ,{s}_{T}^{i}\}\) incorporates the sequential information on how a learner interacts with items over the past \(T\) timesteps. Next, the model concatenates \({s}_{T}^{i}\) with the embedding vector of the next item at timestep \(T+1\) , \({\mathbf{v}}_{{\varvec{j}}}^{{\varvec{T}}+1}\) , and feeds the concatenation into multiple neural network layers, which can be formally stated as:
In the above, \({\mathbf{W}}_{1}\) to \({\mathbf{W}}_{H}\) , and \({f}_{1}\) to \({f}_{H}\) denote the weights and activation functions for the \(H\) neural network layers, respectively. The final output of the multiple neural network layers, \({D}_{T+1}^{i}\) , combines the information on the current item for prediction and the information regarding all history item responding processes.
Self-attention mechanism
To make the model more predictive of item responses, in addition to LSTM networks, the proposed model applies a self-attention layer (Vaswani et al., 2017 ) to model the relevance of an item for prediction with a learner’s history item responding processes. The attention mechanism deals with three types of vector inputs: query, key, and value. Specifically, in the proposed model, the query refers to the item embeddings of an item for prediction, and both keys and values refer to a learner’s history item responding processes \({\mathbf{e}}_{ij}^{t}\) . In the attention mechanism, a compatibility function is used to model the relevance of a query with different keys, represented by attention weights. The output of the attention mechanism is calculated as a weighted sum of value vectors using the attention weights. Specific to the proposed model, the relevance of an item for prediction with previous items can be represented by its attention weights connecting to other items. We used the scaled dot-product attention (Vaswani et al., 2017 ) in the current study, which is formally calculated as:
where \(\mathbf{S}\) , \(\mathbf{S}\) , and \(\mathbf{V}\) denote the query, key, and value matrices of dimension \(k\) respectively, and \(\mathrm{softmax}({\mathbf{V}\mathbf{S}}^{T}/\sqrt{k})\) generates the attention weights. It is noteworthy that the prediction of an item response at timestep \(T+1\) should be solely based on the item responding processes over the past \(T\) timesteps, and therefore when computing attention weights, the model omits keys at timesteps later than \(t\) for any query at timestep \(t\) . In addition, to impose non-linearity on the weighted attention output, according to Vaswani et al., ( 2017 ), for each timestep, the output of the attention layer is fed into a feedforward neural network layer and one layer with the ReLU activation. Moreover, through a residual connection (He et al., 2016 ), the model adds up the input and the output of each layer as the final output so that the importance of lower-layer features can be better captured. Layer normalization (Ba et al., 2016 ) applies to each layer of the attention mechanism.
The proposed model makes predictions through feeding the concatenated output of the deep LSTM network architecture \(\mathrm{D}\) and the attention mechanism \(\mathrm{F}\) into one neural network layer with Sigmoid activation (see the right-hand part of Fig. 1 ):
Model learning
During the training process, the proposed model updates the following model parameters: the embedding weights for items, learners, and problem-solving actions, the LSTM network weights, and the neural network weights. The binary cross-entropy loss is used as the objective function for model learning:
where \({\widehat{R}}_{t}^{i}\) indicates the model-predicted likelihood of correctly solving items at the \(t\) th timestep. The Adaptive Moment Estimation (Adam; Kingma & Ba, 2014 ) is selected as the optimizer in training.
3.2 Dataset description
To evaluate the effectiveness of the proposed model, we used a real-world dataset accessed from the PSLC DataShop Footnote 1 (Koedinger et al., 2010 ), named “Lab study 2012 (cleanedLogs).” There are 74 learners, 14,959 problem-solving steps, and 37,889 transactions involved in the dataset. Moreover, among the six latent skill models (each corresponds to a different number of latent skills), we selected the one labelled “KC (DefaultFewer_corrected)” for training the model. The data was generated through learners interacting with the web-based tutoring system when solving fraction problems. Notably, learners might take different sets of fraction problems, implying different item sequences for each learner. In this study, since learners might take several problem-solving steps to solve a fraction problem, in this study, one problem-solving step was considered an independent item which involved one or multiple transactions (i.e., specific timestamped problem-solving actions). To preprocess the dataset, we first deleted all system-produced and/or non-timestamped transactions and then treated all problem-solving steps related to hints as intermediate actions for solving a problem. In addition, to make problem-solving actions differentiable, we concatenated the labels of actions and corresponding learner selections, given that actions of the same categories share the same labels. For learners’ action and time sequences for solving each item, we fixed the maximum action and time sequence length at six because over 90% of items were attempted with six or fewer actions by learners. Finally, since most sequences of learner-item interactions are of more than 200 timesteps, we split the item sequences of the 74 learners into multiple 20-timestep subsequences to increase the size of item sequences for training. This resulted in a final dataset involving 866 item sequences, 32 unique items, and 15 unique skills.
3.3 Training settings
In this study, the embedding weights of items, learners, and actions were regularized with a finalized regularization weight of 0.001, which was selected from four candidate weights: 0, 0.001, 0.01, and 0.1. In addition, to reduce overfitting, a dropout layer with a dropout rate of 0.5 was applied prior to each neural network layer, which was selected from three candidate rates: 0, 0.2, and 0.5. Regarding the sub-architectures of the proposed model, both the deep LSTM network architecture and the architecture for prediction involve one layer with output dimensions of five and two, respectively. Moreover, we selected a latent dimension of 120 for the embedding layers of items, learners, and actions. The learning rate for Adam was finalized at 0.0001, which was selected from the following four values: 0.0001, 0.001, 0.01, and 0.1. The model was trained for 150 epochs with a finalized batch size of 256, which was selected from the following candidate values: 5, 32, 64, 128, and 256.
3.4 Evaluation settings
In this study, DKT was selected as the baseline for evaluating the effectiveness of the proposed model. DKT is a deep learning-based learner modeling approach that predicts the probabilities of the next learning performance based on modeling history learning performance with an RNN architecture (Piech et al., 2015 ). DKT was used as a baseline for model evaluation in many learner modeling studies, where it has been found to outperform conventional models such as BKT (e.g., Xiong et al., 2016 ). In this study, DKT was modelled with a 100-node LSTM layer, and the model was trained at the skill level (i.e., skill IDs were used as inputs) with a learning rate of 0.001. In addition to DKT, the proposed model was compared against its two sub-architectures, the attention and the LSTM variants. Instead of concatenating the attention and the LSTM outputs for final predictions as in the full model, the attention and the LSTM variants make predictions solely based on the outputs of the attention mechanism and the LSTM architecture, respectively. Moreover, to examine if process data learning is effective for improving prediction performance, we compared the proposed model with a variant without the module for process data learning.
In this study, to evaluate the performance of the proposed model, we selected the first 30%, 50%, and 70% of item responses of each learner item response sequence for training. The model was evaluated with both the regression and classification metrics. The classification metrics included Accuracy (ACC) and the Area Under the Receiver Operating Characteristic (ROC) Curve (AUC; Ling et al., 2003 ). ACC scores are computed as the percentage of correctly predicted item responses with a cut-off value of 0.5. Unlike ACC, AUC indicates the area under the plot of sensitivity rates against the false-positive rates and therefore, its calculation does not rely on any specific cut-off values. This feature of AUC makes it insensitive to class imbalance (e.g., the majority of item responses are correct, and few are incorrect). The regression evaluation metrics (Willmott & Matsuura, 2005 ) included the Mean Absolute Error (MAE) and the Root Mean Square Error (RMSE).
4.1 Prediction performance
The evaluation performance of each model on the test datasets across different training/test partition ratios is presented in Table 1 . Generally, disregarding the training/test partition ratios, the proposed model demonstrates higher ACC and AUC rates and lower MAE and RMSE rates than DKT and the variant without process data learning. Moreover, using more history items for training slightly improves the prediction accuracy of the proposed model, shown by slightly higher ACC and AUC rates and slightly lower MAE and RMSE rates.
Regarding the comparison between the proposed model and its two sub-architecture variants, it is evident that the proposed model has a similar or higher prediction performance than its two sub-architecture variants. However, the attention variant slightly outperforms the LSTM variant.
4.2 Mapping of items to skills
In this study, the proposed model adopted the approach by Pandey & Karypis, ( 2019 ) to discover the mapping of items to skills. In the model, through the attention mechanism, the attention weights of each item for prediction (i.e., the query) can be used to indicate the connection strength of an item with its previous items. The attention weights for each possible item pair (i.e., [query item, key item]) can be summed over all learners to derive their relevance weights, which are then normalized for each query item so that weights of each item sum to one. According to the relevance weights of each item, the items measuring the same skill can be indicated by the clusters of items with the strongest connections to each other.
According to the heatmap of item relevance weights (see Fig. 3 ), even though the clustering of items is not fully clear-cut, it can be found that a major item cluster includes items 10 to 21, shown by their stronger connections to each other than others, indicating that items 10 to 21 might measure the same skill. To validate this, we compared the discovered item-skill associations with the original skill model. According to the skill model, items 10 to 21 were designed to evaluate the same skill of “equivDragFract” (see Table 2 ), which suggests the potential of the proposed model to identify item-skill associations from the scratch automatically. However, unfortunately, the heatmap shows that the proposed model might be less capable of discovering item-skill associations in case only one or two items are developed for measuring a skill. Unsurprisingly, given few items developed for a skill, the skill might not be fully represented and measured by the items, and learners might not have adequate opportunities to exercise the skill. As such, the relevance weights might be calculated with much randomness, resulting in a less clear-cut clustering of items. Moreover, it should be noted that despite multiple skill models for the dataset, the ground truths regarding the connections between items and skills are never known. Therefore, we cannot fully validate the estimated item-skill associations by the proposed model. To sum up, the proposed model successfully identified the mapping of the major skill to most assessment items, supporting its potential to discover item-skill associations from scratch.

Heatmap indicating item relevance by the proposed model. Note. The item and skill names are presented in Table 2
5 Discussion and future work
This work proposed a novel deep learning-based model to sequentially model learning outcomes using product and process data. According to the evaluation results, we conclude that the proposed model can predict learning outcomes with high accuracy and automatically identify the mapping of items to skills without prior expert knowledge. Compared with the model without process data learning, the proposed model accounts for additional information from learner problem-solving processes to improve prediction accuracy.
Notably, our approach aligns with the multiple purposes of learning outcome modeling in the context proposed by Pelánek ( 2017 ). Specifically, learners’ future interactions with a system are affected by the outputs (e.g., predictions of future item responses) of a model analyzing learner data extracted from the system through three loops. During the process of learners interacting with an assessment item, the process data modelling module of the proposed model has the potential to process learners’ problem-solving steps and produce estimated probabilities of item successes, which is characterized as affecting learners’ short-term behaviors within the “inner loop” of learning outcome modelling. Regarding the predictions of future item responses, they can be used to inform the instructional policies for improved learning effects. For example, suppose a system predicts that a learner will correctly solve the next item with a 95% chance. In that case, the system will stop presenting other similar items for measuring the same skill since the learner is very likely to have mastered the skill. Moreover, if a system predicts that an item is too hard or too easy for a learner, then the system will skip or delay presenting the item to the learner to maximize his or her learning effects. These exemplify how the proposed model can affect learners’ future interactions through the “outer loop” of learning outcome modeling by Pelánek ( 2017 ). Regarding the third loop with human involvement, the item-skill associations discovered by the proposed model can be used to provide actional insights. For example, if a system discovers that an item is of low quality or not related to most other items, a human expert might consider dropping this item from the item bank to improve the validity of the assessment system. In summary, the proposed model, the proposed model, bears great potential in promoting personalized learning through its three major features of process data learning, learner modeling, and domain modeling, which correspond to the three loops of learning outcome modeling proposed by Pelánek ( 2017 ).
Pedagogically, our study posits that the proposed model substantively contributes to personalized learning applications, particularly in the context of CBAs, in several key dimensions. First, our study offers a novel, scalable learning outcome modelling approach, affording education practitioners a valuable tool to adeptly leverage both learner product and process data. As suggested by our findings, incorporating student process data significantly enhances the predictive capacity of personalized learning systems. This implies that education practitioners should not only prioritize learners’ explicit performance but also examine their problem-solving processes for a comprehensive understanding of how learners achieve learning objectives. Second, the high predictive capability of the proposed model facilitates a more efficient personalized learning system, proficiently tailoring recommendations for learning materials and assessments to individual students. Finally, the functionality of the proposed model to discover the mapping of items to skills benefits the development of large-scale assessments. Since items can be automatically mapped onto their targeted skills, the development of a large-scale CBA can be more expeditious and cost-effective. In terms of practical implications, educators are encouraged to implement the proposed model to create more reliable and predictive personalized learning experiences for learners, with insights into both the “where” and “why” of learners’ performance. In addition, the proposed model streamlines the development of large-scale CBAs. More importantly, the proposed model holds promise for adaptation to other digital learning environments where learners’ product and process data are available (e.g., massive open online courses) to inform the optimization of learning outcomes and the learning context.
Inevitably, several limitations exist for the current work. First, since the model discovers item-skill associations through identifying major item clusters based on the estimated relevance weights between items instead of parameterizing latent skills, the mapping of items to skills might be discovered with randomness, especially when skills are measured by a limited number of assessment items. Second, despite its satisfactory performance in addressing dichotomous item responses, the model needs to be adapted to deal with polytomous item responses in future work since non-binary scoring is prevailing in most educational settings. Third, the better demonstrate and understand how learners acquire new knowledge, the interpretability of the proposed model can be enhanced considering the black box nature of deep learning architectures.
Data availability
The datasets generated during and/or analysed during the current study are available in the PISA official database, https://www.oecd.org/pisa/pisaproducts/database-cbapisa2012.htm
https://pslcdatashop.web.cmu.edu/
Almutairi, F. M., Sidiropoulos, N. D., & Karypis, G. (2017). Context-aware recommendation-based learning analytics using tensor and coupled matrix factorization. IEEE Journal of Selected Topics in Signal Processing, 11 (5), 729–741. https://doi.org/10.1109/JSTSP.2017.2705581
Article Google Scholar
Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer normalization . arXiv preprint. https://doi.org/10.48550/arXiv.1607.06450
Bergner, Y., Droschler, S., Kortemeyer, G., Rayyan, S., Seaton, D., & Pritchard, D. E. (2012). Model-based collaborative filtering analysis of student response data: Machine-learning item response theory. In Proceedings of the 5th International Conference on Educational Data Mining (pp. 95–102). International Educational Data Mining Society.
Chaplot, D. S., MacLellan, C., Salakhutdinov, R., & Koedinger, K. (2018). Learning cognitive models using neural networks. In International Conference on Artificial Intelligence in Education (pp. 43–56). Springer. https://doi.org/10.1007/978-3-319-93843-1_4
Chen, Y., Li, X., Liu, J., & Ying, Z. (2019). Statistical analysis of complex problem-solving process data: An event history analysis approach. Frontiers in Psychology . https://doi.org/10.3389/fpsyg.2019.00486
Chen, F., Lu, C., Cui, Y., & Gao, Y. (2023). Learning outcome modeling in computer-based assessments for learning: A sequential deep collaborative filtering approach. IEEE Transactions on Learning Technologies, 16 (2), 243–255. https://doi.org/10.1109/TLT.2022.3224075
Cheng, S., Liu, Q., Chen, E., Huang, Z., Huang, Z., Chen, Y., ... & Hu, G. (2019). Dirt: Deep learning enhanced item response theory for cognitive diagnosis. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (pp. 2397–2400). Association for Computing Machinery. https://doi.org/10.1145/3357384.3358070
Corbett, A. T., & Anderson, J. R. (1994). Knowledge tracing: Modeling the acquisition of procedural knowledge. User Modeling and User-Adapted Interaction, 4 (4), 253–278. https://doi.org/10.1007/BF01099821
Cui, Y., Chu, M. W., & Chen, F. (2019). Analyzing student process data in game-based assessments with Bayesian knowledge tracing and dynamic Bayesian networks. Journal of Educational Data Mining, 11 (1), 80–100. https://doi.org/10.5281/zenodo.3554751
de Klerk, S., Veldkamp, B. P., & Eggen, T. J. (2015). Psychometric analysis of the performance data of simulation-based assessment: A systematic review and a Bayesian network example. Computers & Education, 85 , 23–34. https://doi.org/10.1016/j.compedu.2014.12.020
Desmarais, M. C. (2012). Mapping question items to skills with non-negative matrix factorization. ACM SIGKDD Explorations Newsletter, 13 (2), 30–36. https://doi.org/10.1145/2207243.2207248
Desmarais, M. C., Baker, R. S., & d. (2012). A review of recent advances in learner and skill modeling in intelligent learning environments. User Modeling and User-Adapted Interaction, 22 (1–2), 9–38. https://doi.org/10.1007/s11257-011-9106-8
Desmarais, M. C., & Naceur, R. (2013). A matrix factorization method for mapping items to skills and for enhancing expert-based q-matrices. In International Conference on Artificial Intelligence in Education (pp. 441–450). Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-39112-5_45
Dishon, G. (2017). New data, old tensions: Big data, personalized learning, and the challenges of progressive education. Theory and Research in Education, 15 (3), 272–289. https://doi.org/10.1177/1477878517735233
Durand, G., Belacel, N., & Goutte, C. (2015). Evaluation of expert-based Q-matrices predictive quality in matrix factorization models. In Design for teaching and learning in a networked world (pp. 56–69). Springer, Cham. https://doi.org/10.1007/978-3-319-24258-3_5
Greiff, S., Wüstenberg, S., & Avvisati, F. (2015). Computer-generated log-file analyses as a window into students’ minds? A showcase study based on the PISA 2012 assessment of problem solving. Computers & Education, 91 , 92–105. https://doi.org/10.1016/j.compedu.2015.10.018
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778).
He, X., Liao, L., Zhang, H., Nie, L., Hu, X., & Chua, T. S. (2017). Neural collaborative filtering. In Proceedings of the 26th international conference on world wide web (pp. 173–182). International World Wide Web Conferences Steering Committee. https://doi.org/10.1145/3038912.3052569
Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization . arXiv preprint. https://doi.org/10.48550/arXiv.1412.6980
Koedinger, K. R., Baker, R. S. J., & d., Cunningham, K., Skogsholm, A., Leber, B., & Stamper, J. (2010). A data repository for the EDM community: The PSLC dataShop. In C. Romero, S. Ventura, M. Pechenizkiy, & R. S. J. D. Baker (Eds.), Handbook of educational data mining (pp. 43–55). CRC Press.
Google Scholar
Koller, D., & Friedman, N. (2009). Probabilistic graphical models: Principles and techniques . The MIT Press.
Kong, S. C., & Song, Y. (2015). An experience of personalized learning hub initiative embedding BYOD for reflective engagement in higher education. Computers & Education, 88 , 227–240. https://doi.org/10.1016/j.compedu.2015.06.003
Lan, A. S., Waters, A. E., Studer, C., & Baraniuk, R. G. (2014). Sparse factor analysis for learning and content analytics. The Journal of Machine Learning Research, 15 (1), 1959–2008.
MathSciNet Google Scholar
Levy, R. (2014). Dynamic Bayesian Network Modeling of Game Based Diagnostic Assessments. CRESST Report 837. National Center for Research on Evaluation, Standards, and Student Testing (CRESST) .
Ling, C. X., Huang, J., & Zhang, H. (2003). AUC: A better measure than accuracy in comparing learning algorithms. In Conference of the canadian society for computational studies of intelligence (pp. 329–341). Springer. https://doi.org/10.1007/3-540-44886-1_25
Liu, H., Liu, Y., & Li, M. (2018). Analysis of process data of PISA 2012 computer-based problem solving: Application of the modified multilevel mixture IRT model. Frontiers in Psychology . https://doi.org/10.3389/fpsyg.2018.01372
Lord, F. M. (1952). A theory of test scores (Psychometric Monograph, No. 7) . Psychometric Corporation.
Matsuda, N., Furukawa, T., Bier, N., & Faloutsos, C. (2015). Machine beats experts: Automatic discovery of skill models for data-driven online course refinement. In Proceedings of the 8th International Conference on Educational Data Mining (pp. 101–108). International Educational Data Mining Society.
Mislevy, R. J., Behrens, J. T., Dicerbo, K. E., & Levy, R. (2012). Design and discovery in educational assessment: Evidence centered design, psychometrics, and educational data mining. Journal of Educational Data Mining, 4 (1), 11–48. https://doi.org/10.5281/zenodo.3554641
Nguyen, D. M., Tsiligianni, E., & Deligiannis, N. (2018). Extendable neural matrix completion. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6328–6332). IEEE. https://doi.org/10.1109/ICASSP.2018.8462164
Pandey, S., & Karypis, G. (2019). A self-attentive model for knowledge tracing. In 2th International Conference on Educational Data Mining, EDM 2019 (pp. 384–389). International Educational Data Mining Society.
Pelánek, R. (2017). Bayesian knowledge tracing, logistic models, and beyond: An overview of learner modeling techniques. User Modeling and User-Adapted Interaction, 27 (3–5), 313–350. https://doi.org/10.1007/s11257-017-9193-2
Piech, C., Bassen, J., Huang, J., Ganguli, S., Sahami, M., Guibas, L., & Sohl-Dickstein, J. (2015, December). Deep knowledge tracing. In Proceedings of the 28th International Conference on Neural Information Processing Systems (Vol 1, pp. 505–513).
Psotka, J., Massey, L. D., & Mutter, S. A. (1988). Intelligent tutoring systems: Lessons learned . Psychology Press.
Rupp, A. A., Nugent, R., & Nelson, B. (2012). Evidence-centered design for diagnostic assessment within digital learning environments: Integrating modern psychometrics and educational data mining. Journal of Educational Data Mining, 4 (1), 1–10. https://doi.org/10.5281/zenodo.3554639
Sarwar, B., Karypis, G., Konstan, J., & Riedl, J. (2001). Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th international conference on World Wide Web (pp. 285–295). Association for Computing Machinery. https://doi.org/10.1145/371920.372071
Shu, Z., Bergner, Y., Zhu, M., Hao, J., & von Davier, A. A. (2017). An item response theory analysis of problem-solving processes in scenario-based tasks. Psychological Test and Assessment Modeling, 59 (1), 109–131.
Shute, V. J., & Ventura, M. (2013). Measuring and supporting learning in games: Stealth assessment . The MIT Press.
Shute, V. J., Ventura, M., Bauer, M., & Zapata-Rivera, D. (2009). Melding the power of serious games and embedded assessment to monitor and foster learning. In U. Ritterfeld, M. Cody, & P. Vorderer (Eds.), Serious games: Mechanisms and effects (pp. 295–321). Mahwah, NJ: Routledge, Taylor and Francis.
Shute, V. J., & Rahimi, S. (2017). Review of computer-based assessment for learning in elementary and secondary education. Journal of Computer Assisted Learning, 33 (1), 1–19. https://doi.org/10.1111/jcal.12172
Su, X., & Khoshgoftaar, T. M. (2009). A survey of collaborative filtering techniques. Advances in Artificial Intelligence, 2009 , 421425. https://doi.org/10.1155/2009/421425
Su, Y., Liu, Q., Liu, Q., Huang, Z., Yin, Y., Chen, E., et al. (2018). Exercise-enhanced sequential modeling for student performance prediction. In Thirty-Second AAAI Conference on Artificial Intelligence (pp. 2435–2443).
Sun, Y., Ye, S., Inoue, S., & Sun, Y. (2014). Alternating recursive method for Q-matrix learning. In Proceedings of the 7th international conference on educational data mining (pp. 14–20). International Educational Data Mining Society.
Tang, X., Wang, Z., Liu, J., & Ying, Z. (2021). An exploratory analysis of the latent structure of process data via action sequence autoencoders. British Journal of Mathematical and Statistical Psychology, 74 (1), 1–33. https://doi.org/10.1111/bmsp.12203
Tatsuoka, K. K. (1990). Toward an integration of item response theory and cognitive error diagnosis. In N. Frederiksen, R. Glaser, A. Lesgold, & M. G. Shafto (Eds.), Diagnostic monitoring of skill and knowledge acquisition (pp. 453–488). Lawrence Erlbaum Associates Inc.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). Attention is all you need. In Advances in Neural Information Processing Systems 30 (NeurIPS 2017) (pp. 5998–6008).
Wang, H., Wang, N., & Yeung, D. Y. (2015). Collaborative deep learning for recommender systems. In Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1235–1244). Association for Computing Machinery. https://doi.org/10.1145/2783258.2783273
Wang, L., Sy, A., Liu, L., & Piech, C. (2017). Deep knowledge tracing on programming exercises. In Proceedings of the fourth annual ACM conference on learning at scale (pp. 201–204). https://doi.org/10.1145/3051457.3053985
Willmott, C. J., & Matsuura, K. (2005). Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Climate Research, 30 (1), 79–82. https://doi.org/10.3354/cr030079
Xiong, X., Zhao, S., Van Inwegen, E. G., & Beck, J. E. (2016). Going deeper with deep knowledge tracing. In Proceedings of the 9th international conference on educational data mining (pp. 545–550). International Educational Data Mining Society.
Yeung, C. K., & Yeung, D. Y. (2018). Addressing two problems in deep knowledge tracing via prediction-consistent regularization. In Proceedings of the fifth annual ACM conference on learning at scale (pp. 1–10). https://doi.org/10.1145/3231644.3231647
Yeung, C. K. (2019). Deep-IRT: Make deep learning based knowledge tracing explainable using item response theory . arXiv preprint arXiv:1904.11738 https://arxiv.org/abs/1904.11738
Zhang, F., Yuan, N. J., Lian, D., Xie, X., & Ma, W. Y. (2016). Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 353–362). Association for Computing Machinery. https://doi.org/10.1145/2939672.2939673 .
Download references
This paper was supported by the University of Macau Start-up Research Grant (Grant No. SRG2021-00023-FED).
Author information
Authors and affiliations.
Faculty of Education, University of Macau, Taipa, Macau, China
Institute of Collaborative Innovation, University of Macau, Taipa, Macau, China
School of Education, Shanghai Jiao Tong University, Shanghai, China
Department of Educational Psychology, University of Alberta, Edmonton, Canada
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Fu Chen .
Ethics declarations
Ethics approval.
Not applicable.
Conflict of interest
The authors declare that they have no competing interests.
Informed consent
Additional information, publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Chen, F., Lu, C. & Cui, Y. Using learners’ problem-solving processes in computer-based assessments for enhanced learner modeling: A deep learning approach. Educ Inf Technol (2023). https://doi.org/10.1007/s10639-023-12389-x
Download citation
Received : 06 June 2023
Accepted : 26 November 2023
Published : 22 December 2023
DOI : https://doi.org/10.1007/s10639-023-12389-x
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Learner modeling
- Collaborative filtering
- Deep learning
- Process data
- Attentive modeling
- Computer-based assessment
- Find a journal
- Publish with us
- Track your research

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
Computer-Based Collaborative Problem Solving in PISA 2015 and the Role of Personality
Matthias stadler.
1 Psychologie und Pädagogik, Ludwig-Maximilians-Universität München, 80802 Munich, Germany
2 Computer Based Assessment, University of Luxembourg, Esch-Sur-Alzette, L-4366 Luxembourg, Luxembourg
Katharina Herborn
Maida mustafić, samuel greiff.
Collaborative problem solving (CPS) is an essential 21st century skill at the intersection of social collaboration and cognitive problem solving, and is increasingly integrated in educational programs, such as the influential Programme for International Student Assessment (PISA). As research has identified the impact of the Big Five personality traits either on cognitive ability or social collaboration skills in groups, this study firstly identified their impact on the conjoint construct of CPS. Results from structural equation modelling ( N = 483) found openness to experience and agreeableness as predictors for CPS performance. The results are embedded in the lifelong learning and investment model by Ackermann and provide implications for PISA 2015, as original PISA 2015 CPS tasks were used.
1. Introduction
Problem solving skills in collaboration with others (i.e., collaborative problem solving (CPS)) are increasingly important in many aspects of life in the 21st century [ 1 ]. Especially in educational and professional settings, students regularly learn and work in groups and professionals collaborate with colleagues in order to share their expertise, divide tasks, and solve problems that cannot be addressed individually. Thus, CPS skills have evolved as essential domain-general skills for college and career readiness [ 2 ] and public integration in today’s society [ 3 , 4 ].
As an immediate consequence of the increasing relevance of CPS, national and international governmental education commissions and policymakers have recently started to integrate CPS into comprehensive educational initiatives and programs for students. Programs, such as the Partnership for 21st Century Learning (P21; [ 5 ]) or the International Assessment and Teaching of 21st Century Skills project (ATC21S; [ 1 ]), aim to foster and assess CPS to ensure sufficient CPS development during compulsory school education. Among these initiatives, the Programme for International Student Assessment (PISA; [ 6 ]) probably counts as the most influential, with a direct impact on educational policies. PISA assesses over 500,000 students from more than 70 countries every three years in the major scholastic domains of mathematics, science, and reading. Due to the increasing relevance of CPS as a 21st century skill, PISA began assessing CPS in 2015 as a transversal skill and just recently published the results on the country comparisons on CPS performance (for further information see [ 6 ]). Taking into consideration that CPS is increasingly required in virtual settings in our global and computerized society, PISA 2015 assessed CPS via computer-based CPS approaches to adequately prepare students for realistic future environments.
However, despite the increased relevance of CPS in general, and particularly within computer-based environments, academic research on CPS is currently scarce and far below what would be expected given the great current political and educational relevance of CPS. In fact, there is scant empirical evidence on how CPS relates to other constructs and how it can be generally predicted. However, CPS is defined as a skill at the intersection of social collaboration skills and cognitive problem solving skills, and an existing body of research has found that personality is a predictor for both of these constructs, both generally and in virtual environments. For example, research has found that individual group members’ Big Five traits (i.e., openness to experience, neuroticism, conscientiousness, extraversion, and agreeableness) are contributors to the resulting overall group performance [ 7 ], and that this finding can be generalized to virtual environments [ 8 ]. Interrelations have also been found between the Big Five personality traits and general cognitive ability [ 9 ], as well as cognitive problem solving in virtual tasks [ 10 ].
Investment theories, such as the lifelong learning and investment model (intelligence-as process, personality, interests, and knowledge; PPIK) by [ 11 ], ground these relations between cognitive ability and affective traits in their interdependent development during childhood and adolescence, which ultimately creates patterns of abilities, skills, personality, and interests [ 12 ]. The PPIK theory integrates intelligence-as-process, personality, interest, and intelligence-as-knowledge, thereby grounding ability levels and personality dispositions as determinates of success in particular task domains (e.g., science or mathematics) [ 13 ]. Transferring existing research and the PPIK theory onto CPS, the Big Five personality traits (i.e., openness to experience, neuroticism, conscientiousness, extraversion, and agreeableness) should also play a role in CPS to varying degrees, as CPS is a construct that integrates social collaboration and cognitive problem solving skills. However, existing findings investigate either the personality–social collaboration link or the personality–cognitive ability link separately, with no existing findings on the role of the Big Five in the conjoint construct of CPS. To better understand the nature of CPS and develop educational assessments and interventions, the role of personality in CPS needs to be explored.
To identify the role of personality in CPS, and address the discrepancy between a lack of academic research on the one hand and increasing educational and political demands on the other, this study first reviews the PISA 2015 CPS approach before subsequently investigating whether and to what extent personality can predict CPS performance. In a final step, as reasoning and reading skills play a role in CPS skills, we ensured that the association between personality and CPS is distinct by controlling for reasoning and reading performance.
2. Computer-Based Assessment of CPS in PISA 2015
In PISA 2015, CPS is defined as a skill “(…) to effectively engage in a process whereby two or more agents attempt to solve a problem by sharing the understanding and effort required to come to a solution and pooling their knowledge, skills and efforts to reach that solution” [ 14 ]. To assess CPS on the fine-grained level of specific aspects of cognitive problem solving in social collaborative environments, 12 distinguishable CPS skills were stipulated for PISA 2015. Each CPS skill represented a particular aspect of social collaboration with others (e.g., maintaining shared understanding within the group) or cognitive problem solving processes (e.g., planning and executing) (for further details on the 12 CPS skills, see the PISA 2015 “12-Cells Matrix” in Table 1 , [ 14 ]). At the end of the PISA 2015 CPS assessment, CPS sub-skills were summed up to obtain an overall CPS score.
The 12-Cells Matrix illustrating the 12 collaborative problem solving (CPS) skills in the Programme for International Student Assessment (PISA) 2015 Assessment. Drawn from the Organisation for Economic Co-operation and Development (OECD) CPS Draft Report in PISA 2015 [ 6 ].
PISA 2015 chose a computer-based approach to assess students’ preparedness for present-day and future virtual CPS environments in our global and computerized 21st century society. More specifically, CPS skills in PISA 2015 were assessed via individual computer-based CPS tasks, which required the individual to collaborate with a minimum of one and a maximum of three virtual computer agents (human-agent (H-A)) approach in simulated real-life problem scenarios beyond the specific context of school subjects. Figure 1 depicts a screenshot of the example PISA 2015 CPS task “The Visit,” which required students to organize a trip for a school class. As shown in Figure 1 , the English version of the PISA 2015 task “The Visit” required students to collaborate with the computer-simulated agents, George, Rachel, and Brad, by exchanging predefined messages in a chat box on the left side of the screen, while solving simulated problems in a task space on the right side of the screen (for more detailed information, see [ 14 ]). Students’ CPS skills were scored on the basis of their message selection and performance on problem solving actions; students always received a selection of predefined messages of which one (and in seldom cases two) was the correct answer, reflecting a specific CPS skill in this particular situation. For example, in Figure 1 , the highlighted response is the correct answer and represents skill “B1,” as it helps to advance the group’s shared understanding of what “local” means (i.e., B1: Building a shared representation and negotiating the meaning of the problem, common ground) [ 15 ].

Screenshot of the released example PISA 2015 CPS task “The Visit” (OECD, 2015). The Visit is one officially published PISA 2015 CPS task. It only ran in the PISA 2015 field trial and not in the main study [ 15 ].
The general setup of the PISA 2015 CPS tasks was to simulate real-life collaborative environments by attributing varying characteristics and CPS skills to the agents, varying group sizes, and assigning different group roles to the students in the tasks. Therefore, the computer agents responded to the students’ requests differently across tasks, group sizes varied from two to four group members, and students performed different roles, such as coordinator or decision-maker, within the group. For example, in the example task, “The Visit,” Rachel was simulated as having stronger CPS skills than George and Brad by providing more helpful information, the group consisted of four members, and the student had to maintain shared understanding in the group. This enabled the simulation of real-life CPS environments and allowed CPS skills to be assessed in a standardized and controlled manner without external effects from collaboration partners, such as personality impacting the student data [ 14 ].
Whereas external effects on the assessed students can be controlled for via standardized assessment conditions, effects of students’ personality differences on resulting CPS performance are present, although their extent is unknown. While a growing body of research has found personality to be a predictor of both cognitive ability as well as social collaboration skills in groups, it can be hypothesized that personality also plays a role in CPS. However, the role of personality in the conjoint construct of CPS has not been investigated to date yet. Only selective aspects of CPS have been examined, and the role of individual personality in problem solving processes in social collaboration with others remains unclear. However, just as computer agents’ personalities change group interactions and CPS behaviors, the test-taker’s personality should also exert an effect on CPS performance within the group. Understanding personality differences in CPS performance could sharpen the development of CPS assessments and interventions. For example, findings on the role of personality for selective aspects of CPS, such as group composition [ 7 ], or how the combination of members’ personalities affects interaction and group performance [ 16 ] supported the development of CPS assessments, such as those for PISA 2015 (for further details, see [ 14 ]), which aim to sufficiently prepare students for current and future 21st century challenges. Therefore, we draw appropriate hypotheses from the separate bodies of literature on the personality–social collaboration link and the personality–cognitive ability link in our analysis of the role of personality in the conjoint construct of CPS.
3. The Triad between Personality and Social and Cognitive Abilities
3.1. personality and social collaboration abilities.
Social collaboration represents an essential component in the conjoint construct of CPS, alongside cognitive problem solving, and personality research has identified personality traits as important influencers of individuals’ social collaboration behavior in groups. This collaborative behavior, in turn, shapes group members’ interactions and overall group performance. In fact, human resources departments within organizations are increasingly taking individual personality differences into account when composing groups of employees for work-related tasks [ 17 ]. The majority of existing academic research on the role of personality in social collaboration captures personality differences with the Big Five model, which summarizes personality according to the five main personality traits of openness to experience, neuroticism, conscientiousness, extraversion, and agreeableness (FFM; Big Five [ 18 ]). More specifically, a high level of openness to experience describes individuals with an active imagination (fantasy), aesthetic sensitivity, attentiveness to inner feelings, preference for variety, and intellectual curiosity [ 18 ]. In direct contrast, high levels of neuroticism characterize anxious, hostile, depressive, self-conscious, vulnerable, impulsive individuals who frequently experience negative moods [ 18 ]. Conscientious individuals are characterized as hardworking, responsible, self-disciplined, organized, and achievement-oriented [ 18 ], whereas extraverted individuals are described as sociable, outgoing, energetic, impulsive, and also less introspective [ 18 ]. High levels of agreeableness in individuals reflect trusting, frank, altruistic, cooperative, caring, and empathetic characteristics.
Meta-analytical results on the Big Five and their impact on social collaboration show that group members’ Big Five personality traits affect their social collaboration skills with other group members. For example, openness to experience reflects curiosity, preference for variety, and broad-mindedness, which seems to support social collaboration in groups. Homan and colleagues [ 16 ] found that open individuals encourage information exchange and the sharing of other group members’ ideas and opinions, enhancing overall group performance (for more specific meta-analytical results, see [ 19 ]). In direct contrast to this, high levels of neuroticism have been found to be a negative predictor of social collaboration, as neurotic individuals appear to be less cooperative, interact less with their fellow group members [ 20 ], and are less willing to help [ 21 ]. Therefore, groups with higher levels of neuroticism tend to perform lower in team performance tasks due to, for example, the development of negative work climates [ 22 ].
Furthermore, higher levels of conscientiousness are found among hardworking, organized, and achievement-oriented individuals, and tend to support social collaboration with others and thus group performance. Conscientious individuals enhance groups’ achievement orientation, and research has shown that groups with a high need for achievement outperform groups with a lower need for achievement in a variety of tasks [ 23 ]. Likewise, high levels of extraversion exhibit positive effects on social collaboration. Extraversion enhances interactions between team members, which is generally considered beneficial for overall group performance. The sociability and talkativeness of extroverts tend to support information exchange and interactions between group members [ 24 , 25 ] and create positive group climates in which individuals feel like they can express themselves [ 26 ]. Despite research identifying limitations in the extent to which extraversion contributes to group performance, for instance, that too many extraverts in a team can hinder group performance due to distractions resulting from social interaction [ 27 ], or social dominance [ 23 ], extraversion can be seen as a positive predictor overall. Finally, a high level of agreeableness is found among trusting, cooperative, and empathetic individuals, and facilitates interpersonal attraction, cooperation, smooth conflict resolution, open communication, and information seeking in groups (for more details, see [ 26 ]). Therefore, groups with lower levels of agreeableness and lower levels of tolerance, friendliness, helpfulness, and non-competitiveness tend to also have lower performance [ 24 , 26 ].
3.2. Personality and Cognitive (Problem Solving) Abilities
Cognitive problem solving accounts for the cognitive component of the conjoint construct of CPS. As problem solving can be seen as a facet of cognitive ability [ 28 ], existing findings on the relation between cognitive measures and personality can be helpful in forming hypotheses on the role of personality in CPS. A body of research and meta-analyses have identified consistent interrelations between personality traits and diverse cognitive tests assessing different aspects of cognitive ability (e.g., fluid and crystallized intelligence, reasoning, and memory), despite the longstanding debate on the degree to which personality and cognitive ability are inseparable or independent constructs [ 29 , 30 ]. Investment and developmental theories, such as the lifelong learning and investment model (PPIK) by Ackermann [ 11 ], ground relations between cognitive ability and affective traits in their interdependent development during childhood and adolescence, which ultimately creates patterns of abilities, skills, personality, and interests [ 12 ]. The PPIK theory integrates intelligence-as-process, personality, interest, and intelligence-as-knowledge, and therefore grounds ability levels and personality dispositions as determinates of success in particular task domains (e.g., science or mathematics) [ 13 ].
Personality generally accounts for approximately 5% to 10% of the variance in cognitive performance [ 31 ]. Hereby, the most consistent relations with cognitive ability have been identified for openness to experience and neuroticism. Openness to experience has been found to be a positive predictor of cognitive ability [ 32 ], as higher levels of openness to experience seem to induce stronger intellectual curiosity, interest, and engagement in cognitively stimulating tasks, which support the development of general cognitive ability [ 9 , 33 ]. Particularly in students, higher levels of openness to experience tend to be associated with general learning motivation [ 34 ] and critical thinking [ 35 ], positively affecting students’ academic performance in the form of grades in languages (i.e., German and French), and intelligence assessed via five subtests (i.e., figural thinking, reasoning, numerical, and arithmetical thinking), as found in PISA 2009 longitudinal data [ 36 ].
In direct contrast to this, neuroticism is a negative predictor of cognitive ability and problem solving. Neuroticism has been found to induce negative thoughts and test anxiety in testing conditions [ 12 ] and to decrease students’ general level of interest, which can lead to lower cognitive ability of attainment and skills [ 12 ] as well as dysfunctional thought processes, such as overgeneralizing or dependence on others [ 37 ]. Neuroticism also seems to impede students’ academic performance, for shifting students’ focus to emotional states and self-talk rather than academic task performance [ 38 ]. With regard to problem solving, neuroticism was negatively related to knowledge acquisition and application among students in virtual problem solving tasks [ 10 ].
Less consistent relations have been identified between cognitive ability and the three remaining Big Five traits of conscientiousness, extraversion, and agreeableness. Conscientiousness has sometimes been found to be negatively associated with cognitive ability and problem solving [ 10 ]. However, this is highly controversial, as conscientiousness has been found to be positively correlated with work-related outcomes (for possible reasons for this contradiction, see [ 30 ]). In student populations, conscientiousness is positively correlated with academic performance at school [ 39 ], particularly in mathematics, German, and French, and intelligence [ 36 ]. Similarly, inconsistent results have been found for the link between extraversion and cognitive ability. Extraversion has been identified as a positive predictor for diverse intelligence categories [ 40 ], including verbal learning, conditioning, and short and long-term memory recall [ 41 ]; however, it has also been found to be a negative predictor for performance in cognitive tasks [ 42 , 43 ]. For example, extraverted students seem to perform better academically due to higher energy levels and desires to learn [ 38 ] but also perform lower due to distraction resulting from socializing instead of studying [ 39 ]. Chamorro-Premuzic and Furnham [ 44 ] argue that a high level of extraversion supports academic performance during elementary school up to an age of approximately 12 years, but hinders it during secondary education. Likewise, inconsistent results have been obtained for the connection between agreeableness and cognitive ability. Only some facets of agreeableness have exhibited effects on cognitive ability, including a negative effect for aggressiveness [ 13 ], and positive effects for emotional perception and facilitation [ 45 ]. Findings about the link between agreeableness and academic performance are also consistently insignificant [ 46 ].
4. Purpose of This Study and Hypotheses
Despite the increasing relevance of CPS as a 21st century skill in students, and its integration into governmental education programs, such as PISA 2015 [ 14 ], there is little empirical evidence on how CPS is related to other constructs, its antecedents, or how it can be generally predicted. However, an existing body of research has identified the Big Five as predictors of social collaboration and cognitive problem solving. Considering that CPS is a conjoint construct of social collaboration and cognitive problem solving, the Big Five are expected to also play a role in CPS. Nevertheless, existing findings investigate either the personality–social collaboration link or the personality–cognitive ability link separately, and there is no research on the role of the Big Five in the conjoint construct of CPS. To overcome this, this study investigates the role of the Big Five in CPS and draws the following hypotheses from the separate bodies of literature on the personality–social collaboration link and the personality–cognitive ability link.
H1: The Big Five personality traits of openness to experience, conscientiousness, extraversion, and agreeableness will be positively associated with CPS.
H2: The Big Five personality trait of neuroticism will be negatively associated with CPS.
Existing findings on the relationship between cognitive ability and personality are consistent (see Section 3.2 . Personality and Cognitive (Problem Solving) Abilities). To ensure that CPS is not only assessing cognitive performance, we control for two cognitive indicators in a second step of our analysis: Reasoning, due to its strong association with problem solving, and reading, as the PISA 2015 CPS units have a strong reading load. We hypothesize that the association between personality and CPS is distinct and therefore control for reasoning and reading performance in an additional step.
H3: The association between the Big Five personality traits on CPS will remain constant after controlling for reasoning and reading.
5.1. Sample
A total of 748 students participated voluntarily in the study. Students were ninth and tenth graders at seven different secondary grammar schools in Germany. Grammar schools are the academically most demanding track in the German school system (for more information, please see [ 47 ]). Students without signed informed consent forms, or who had participated in pilot studies ( N = 71) were excluded from the sample. We also dealt with missing data by design ( N = 192) which had to be excluded from the final sample. The final convenience sample consisted of 483 participants ( M = 15.80, SD = 0.65, 59.0% identified as female). Students received individual feedback on their results if requested.
5.2. Measures and Procedure
Collaborative Problem Solving (CPS). CPS was assessed using four of the seven original German PISA 2015 tasks we received from the OECD. As illustrated in Section 2 , the PISA 2015 CPS tasks required students to collaborate with agents by exchanging predefined messages in a chat box, and performing actions (e.g., drag and drop) within a simulated problem in a task space ( Figure 1 ). Writing directly to collaboration partners (so-called open chat communication) was not possible. Scoring was equivalent to the original PISA 2015 scoring, with one (or in rare cases, two) of the offered predefined messages, which represented a specific CPS skill, scored as the correct answer. All four tasks consisted of several consecutive task sections all within the same problem scenario; however, each task section was scored separately to allow for ongoing improvement throughout the units (for further information, please see [ 14 ]). In the tasks, students were given full credit (1 or in rare cases 2 points) for selecting the correct predefined messages and performing specific actions (e.g., correct drag and drop actions) in the problem space. Otherwise participants received no credit (0 points). To reduce the number of parameter estimations, we reduced the PISA 2015 CPS tasks into sum parcels [ 48 ]. Items were summed up to overall CPS scores for each CPS task.
Personality. The German version of the Neo Five-Factor Inventory (NEO-FFI) [ 49 ] was used to assess personality in a self-report format. The questionnaire consisted of a total of 60 items capturing the five personality traits of openness to experience, neuroticism, conscientiousness, extraversion, and agreeableness. Each trait was measured with 12 items on a 5-point Likert scale from 0 ( strongly disagree ) to 4 ( strongly agree ). Negatively phrased items were reversed. In accordance with the test manual, sums scores were calculated for each trait and divided by the number of answered questions. The resulting values reflected the strength of each personality trait.
Reasoning. The Intelligence Structure Test-Screening (IST-Screening) [ 50 ] was used to assess students’ reasoning skills. According to the IST-Screening manual, the test encompasses three subtests for numerical intelligence, verbal intelligence, and figural intelligence [ 50 ]. These subtests assessed each aspect of intelligence via number series, verbal analogies, and figure selection, and the overall test lasted approximately 30 minutes. Items were scored dichotomously such that students received full credit (1) or no credit (0) for each individual task. In accordance with the test manual, the sum of points was used to reflect the overall reasoning score.
Reading. Reading competency was assessed via one published paper-based PISA 2009 reading task “mobile phone security” (the German tasks can be viewed under http://www.men.public.lu/fr/themes-transversaux/qualite-scolaire/pilotage-monitoring/programme-international-pisa/ ). The task first had students read text material about a real-life situation (for example, information on mobile phone security). The task consisted of four items. The task included multiple-choice and open-response items. In accordance with the PISA 2009 coding guidelines, students received full credit (1) for selecting the designated correct answer in multiple-choice items, and no credit (0) otherwise [ 15 ]. In open response tasks, students were required to construct their own responses, for which they received full credit (1) for responding correctly, and no credit (0) otherwise [ 15 ]. Notably, open response tasks required their scoring by external independent coders following the PISA 2009 coding guidelines. Items were scored dichotomously such that students received full credit (1) or no credit (0) for individual tasks. In accordance with the PISA 2009 coding guidelines, an overall sum score was calculated by adding up the subscores on the task.
Procedure. The Luxembourgish National Commission for Data Protection, and the Education Ministries of Rhineland-Palatinate and Hesse approved the data collection in schools. Schools were recruited over email and participating classes received a financial reward in form of a donation of 160 Euro per class. Two trained test administrators assessed students over the course of one full school day (approximately 4.5 h) during regular class time, following a standardized assessment procedure for each class. Students completed several computer-based and paper-based performance tests and self-report questionnaires, from which the CPS, reasoning, and reading tests as well as the personality questionnaire are relevant to this study. At the beginning of each test day, students completed four original PISA 2015 CPS tasks individually over approximately two hours on MacbookPro laptops that were randomly assigned to students (i.e., students drew laptop numbers). In the PISA 2015 CPS tasks, students were required to solve virtual problem scenarios in collaboration with a minimum of one and a maximum of three computer-simulated agents. Students’ CPS performance was saved locally in the form of log files (i.e., files that contain users’ computer actions). After the PISA 2015 tasks, the paper-based performance tests and questionnaires were completed. To avoid cognitive fatigue in students over time during long test sessions [ 51 ], regular breaks were held in between performance tests and questionnaires.
5.3. Statistical Approach
We conducted latent regression analysis using structural equation modeling (SEM) in Mplus Version 7.0 [ 52 ] to test the association between the individual Big Five personality traits (i.e., openness to experience, neuroticism, conscientiousness, extraversion, and agreeableness) on CPS (H1 and H2; Model A), also when controlling for reasoning and reading (H3; Model B). Both models included missing data by design, as some students completed particular PISA 2015 CPS tasks in a reformatted version for the purpose of another study. Because this study was designed to work with original PISA 2015 CPS tasks, these students’ values were replaced with missing values. In SEM, we chose the maximum likelihood estimator for robust standard errors and fit statistics against normality violations (MLR) for our model due to the nature of our continuous variables. We applied the “type is complex” command in MPlus7, for which a minimum of 20 classes is required, to include the hierarchical structure of our nested data (i.e., students nested in 32 different classes) in Models A and B and adjust standard errors. Model fit was evaluated according to standard fit indices and cut-off values, namely the comparative fit index (CFI, cut-off CFI > .95 for good fit), Tucker–Lewis index (TLI, cut-off TLI > .95 for good fit), root-mean-square-error-of-approximation (RMSEA, cut-off RMSEA < .05 for good fit), and standardized-root-mean-square-residual (SRMR, cut-off SRMR < .05 for good fit). In a final step, we controlled for reasoning and reading competency, assessed using the IST-Screening and PISA 2009 reading tasks, to identify whether the association between personality and the Big Five is distinct (H3). For this, we used a technique of using residuals to control for common variance between CPS and reading and reasoning, respectively [ 53 ]. Hereby, we regressed CPS on reasoning and reading performance, and subsequently included only the residual of CPS as a criterion for the Big Five personality traits (Model B).
6.1. Measurement Model and Descriptive Statistics
The CPS measurement model with four indicators (the four CPS tasks) exhibited tenable model fit ( χ 2 = 80.92, df = 4, p > .05; CFI = 1.00, TLI = 1.00, RMSEA = .000, SRMR = .014, N = 483). Table 2 provides details on the manifest and latent correlations, means, and standard deviations for the measures in this study.
Manifest (above the diagonal) and latent (below the diagonal) correlations for the Big Five personality traits of openness to experience ( O ), neuroticism ( N ), conscientiousness ( C ), extraversion ( E ), agreeableness ( A ), collaborative problem solving ( CPS ), reading performance ( Read ), and reasoning ( Reas ), as well as McDonald’s Omega values ( ω ).
Note. The Big Five personality traits (O/N/C/E/A), reading performance (Read), and reasoning (Reas) were manifest variables and CPS was a latent variable. Total N = 483. M = mean. SD = standard deviation. * p < .05. ** p < .01.
6.2. H1 and H2 (Relation between Personality and CPS)
To test the association between personality and CPS performance, we included the Big Five personality traits of openness to experience, neuroticism, conscientiousness, extraversion, and agreeableness as predictors, and CPS performance as criterion in the first model (Model A). The Big Five personality traits were modeled as manifest sum scores, whereas CPS was modeled as a latent factor with four indicators. Model fit was tenable (Model A: χ 2 = 20.926, df = 17, p > .05, CFI = .980, TLI = .970, RMSEA = .022, SRMR = .038, N = 483). As presented in Figure 2 , we found associations between the Big Five personality traits and CPS performance. Hereby, the Big Five traits of openness to experience ( ß = .30, SE = .06, p < .01) and agreeableness ( ß = .14, SE = .06, p < .05) were positively associated with CPS performance. As expected in H1, students with higher levels of openness to experience and agreeableness achieved higher performance scores than students with lower levels of openness to experience and agreeableness. Conscientiousness ( ß = .04, SE = .07, p > .05) and extraversion ( ß = −.02, SE = .06, p > .05) were not significantly associated with CPS. In contrast to our expectation in H2, neuroticism ( ß = .08, SE = .05, p > .05) exhibited a slightly positive but non-significant relation to CPS. The results for H1 confirmed our expectations to the extent that the two Big Five personality traits openness to experience and agreeableness were positive predictors of CPS performance.

Structural equation model (Model A) presenting the associations between the self-reported Big Five personality traits of openness to experience (O), neuroticism (N), conscientiousness (C), extraversion (E), agreeableness (A), and CPS. Significant standardized parameter estimates are significant at the ** p < .01 or * p < .05 level and presented as solid black arrows. Non-significant standardized parameter estimates are presented as dotted arrows.
6.3. H3 (Relation between Personality and CPS Controlling for Reasoning and Reading)
In a next step, we controlled for reasoning and reading to identify whether the association between personality and CPS is distinct and therefore control for reasoning and reading performance in CPS. Model fit was tenable (Model B: χ 2 = 36.346, df = 23, p > .05, CFI = .951, TLI = .927, RMSEA = .035, SRMR = .038, N = 483). Equivalent to Model A, the Big Five traits of openness to experience ( ß = .29, SE = .05, p < .01) and agreeableness ( ß = .12, SE = .06, p < .05) positively predicted CPS performance. Similarly to Model A, the traits of conscientiousness ( ß = .08, SE = .07, p > .05) and extraversion ( ß = −.00, SE = .06, p > .05) exhibited non-significant associations with CPS. In contrast, neuroticism ( ß = .13, SE = .04, p < .01) was a significant positive predictor for CPS (see Figure 3 ).

Structural equation model (Model B) presenting the associations between the self-reported Big Five personality traits of openness to experience (O), neuroticism (N), conscientiousness (C), extraversion (E), agreeableness (A), and CPS, controlling for reasoning (Reas) and reading (Read). CPSres represents the disturbance term for CPS. Correlations were allowed between all manifest variables. Significant standardized parameter estimates are significant at the ** p < .01 or * p < .05 level.
7. Discussion
The aim of the current study was to investigate whether and to what extent personality can predict CPS. For this, the study applied SEM to test the associations of the Big Five personality traits, that is, openness to experience, neuroticism, conscientiousness, extraversion, and agreeableness, with CPS. As expected, SEM identified positive associations between the Big Five personality traits of openness to experience and agreeableness and CPS performance. These results remained mostly stable when controlling for reasoning and reading performance.
7.1. Openness to Experience and Agreeableness Predict CPS beyond Reasoning and Reading
In our analyses, the Big Five trait of openness to experience remained the strongest predictor of CPS, as expected from the academic literature showing a link between openness to experience and cognitive ability as well as social collaboration. We assume that higher levels of openness to experience in students induced stronger engagement with the cognitive problem solving tasks and increased information exchange with the computer agents in the PISA 2015 CPS tasks [ 9 , 33 ]. This might explain why students with higher levels of openness to experience achieved higher CPS performance. These results are in line with the PPIK model [ 11 ], which stipulates a positive relation between openness to experience and intelligence [ 43 ] due to stronger intellectual curiosity, interest, and engagement in cognitively stimulating tasks, which support the development of general cognitive ability [ 9 , 33 ].
In addition to openness to experience, agreeableness also predicted higher CPS performance in students. It is plausible that higher levels of agreeableness induced more cooperation, conflict resolution, and communication with the computer agents, all of which are a relevant part of the PISA 2015’s understanding of CPS. That is, considering that the computer agents in PISA 2015 CPS tasks deliberately create disagreements in order to test how students communicate in such situations and resolve the problem [ 14 ], agreeable students seem to have been able to resolve these situations more often, which in turn led to higher CPS performance. In addition, PISA 2015 weighted collaboration actions higher than problem solving actions in its scoring methodology, which may have further supported the role of agreeableness in CPS performance. These results on openness to experience and agreeableness remained stable when controlling for reasoning and reading. The correlations between reasoning and reading and CPS were relatively strong (see Table 2 ), and controlling for the variance of reasoning and reading in CPS ensured that the associations between personality and CPS were distinct. Also, controlling for reasoning in CPS extracted aspects of reasoning-based problem solving and emphasized the social collaboration aspects of the conjoint PISA 2015 CPS construct CPS. As openness to experience and agreeableness remained stable predictors for CPS, we can say that these predictors are essential for social interaction in CPS environments.
Further, our findings do not support the negative association between neuroticism and cognitive ability and social collaboration (e.g., [ 10 ]). Neuroticism showed a weak positive association with CPS, which was significant when controlling for reasoning and reading performance. Obviously, the social collaboration in the CPS tasks was artificial as all collaboration partners were agents, which was openly disclosed to the participants. It therefore seems plausible that social anxiety or the fear of being evaluated by the collaborators would not limit participants’ performance. The positive association between neuroticism and CPS still remains surprising. It is possible that, once the fear of being evaluated was removed, students with higher neuroticism actually benefitted from their greater attention to the social interaction. This remains purely speculative, though, and needs to be corroborated in future studies.
The correlations between openness and the other dimensions of personality were considerably lower than to be expected based on previous meta-analyses [ 54 ]. This may be due to the relatively low average age of our sample as other studies also reported small to zero correlations between openness and other dimensions of personality in samples of children and young adults [ 55 , 56 ].
Overall, our results did not contradict the PPIK theory to the extent that personality dispositions act as determinates for success in particular task domains, and that cognitive ability cannot be fully understood without integrating personality differences. In our case, openness to experience acted as a determinate for success in CPS performance even though it was not significantly related to reasoning. Going a step further, investment theories, such as the PPIK theory, argue that patterns of personality, interests, and cognitive ability become increasingly consistent with age as interests steer individuals’ attention to life experiences (for an alternative view, refer to [ 9 ]). In addition, intra-individual differences in cognitive ability and non-ability trait determinants develop mostly during the school years and stabilize at the end of high school [ 57 ]. Therefore, our results should be generalizable to adults, as the participants in our study were at the end of compulsory education (age M = 15.80). Finally, looking at personality at the facet level, rather than the domain level, might lead to stronger and even more interesting findings [ 58 ].
7.2. Limitations
To the best of our knowledge, this study remains the only study on the role of personality in CPS performance. As this study entails limitations, future empirical studies that address these should be conducted to establish knowledge regarding the relatively new construct of CPS. First, this study assessed a pre-specified sample of adolescents who were of the same age as the PISA samples. Despite our assumption that our findings can be generalized to adults on the basis of the PPIK theory, further studies should test this using adult samples. Furthermore, we employed the PISA 2015 understanding of CPS as a conjoint construct encompassing social collaboration and cognitive problem solving skills. The overall correlations found between CPS and personality were rather low, though. As personality and cognitive ability combined could not explain all the variance in CPS, the chosen definition of CPS may not be adequate. Defining and employing CPS as a non-conjoint construct may allow the role of personality within each specific component to be identified (see also [ 9 ]). Moreover, reading was assessed with only one PISA 2009 task, which showed an unacceptably low internal consistency. The effect sizes for reading are therefore likely to be underestimated by our models. Future studies should either use the complete PISA 2009 reading scale in assessing reading, or use a different empirically established assessment measure for reading.
7.3. Conclusions and Future Outlook
Despite the increasing recognition of CPS solving as an important 21st century skill by governmental and educational leaders, particularly for computer-based environments, scientific research on CPS has been scarce, lagging far behind the political and educational relevance of CPS. There is scant empirical evidence on how CPS relates to other constructs, its antecedents, or how it can be generally predicted. This study identified whether, and which of the Big Five personality traits predict CPS in PISA 2015 CPS tasks. We found that openness to experience and agreeableness were positive predictors for CPS performance, even after controlling for reasoning and reading performance. In other words, students who reported higher levels of openness to experience and agreeableness achieved higher CPS scores assessed using the PISA 2015 computer-based approach. These results contribute important information for the development of educational assessments and educational interventions for CPS. For example, intervention strategies for students with low levels of openness to experience or agreeableness can be developed to adequately prepare students for realistic future environments, including computer-based environments. In addition to this study’s theoretical and practical contribution to CPS research, it also provides the first practical indications of students’ PISA 2015 CPS performance results that have been published in a special report by [ 6 ] just recently.
Acknowledgments
We thank Nick Schweitzer and Tomas Kamarauskas for their contributions to the implementation of this study and data collection.
Author Contributions
All authors contributed substantially in all aspects of the manuscript.
This research was funded by the Organisation for Economic Cooperation and Development (OECD) and the Fonds National de la Recherche Luxembourg (ATTRACT “ASKI21”) awarded to Samuel Greiff.
Conflicts of Interest
The authors declare no conflict of interest.
Universities Have a Computer-Science Problem
The case for teaching coders to speak French

Listen to this article
Produced by ElevenLabs and News Over Audio (NOA) using AI narration.
Updated at 5:37 p.m. ET on March 22, 2024
Last year, 18 percent of Stanford University seniors graduated with a degree in computer science, more than double the proportion of just a decade earlier. Over the same period at MIT, that rate went up from 23 percent to 42 percent . These increases are common everywhere: The average number of undergraduate CS majors at universities in the U.S. and Canada tripled in the decade after 2005, and it keeps growing . Students’ interest in CS is intellectual—culture moves through computation these days—but it is also professional. Young people hope to access the wealth, power, and influence of the technology sector.
That ambition has created both enormous administrative strain and a competition for prestige. At Washington University in St. Louis, where I serve on the faculty of the Computer Science & Engineering department, each semester brings another set of waitlists for enrollment in CS classes. On many campuses, students may choose to study computer science at any of several different academic outposts, strewn throughout various departments. At MIT, for example, they might get a degree in “Urban Studies and Planning With Computer Science” from the School of Architecture, or one in “Mathematics With Computer Science” from the School of Science, or they might choose from among four CS-related fields within the School of Engineering. This seepage of computing throughout the university has helped address students’ booming interest, but it also serves to bolster their demand.
Another approach has gained in popularity. Universities are consolidating the formal study of CS into a new administrative structure: the college of computing. MIT opened one in 2019. Cornell set one up in 2020. And just last year, UC Berkeley announced that its own would be that university’s first new college in more than half a century. The importance of this trend—its significance for the practice of education, and also of technology—must not be overlooked. Universities are conservative institutions, steeped in tradition. When they elevate computing to the status of a college, with departments and a budget, they are declaring it a higher-order domain of knowledge and practice, akin to law or engineering. That decision will inform a fundamental question: whether computing ought to be seen as a superfield that lords over all others, or just a servant of other domains, subordinated to their interests and control. This is, by no happenstance, also the basic question about computing in our society writ large.
When I was an undergraduate at the University of Southern California in the 1990s, students interested in computer science could choose between two different majors: one offered by the College of Letters, Arts and Sciences, and one from the School of Engineering. The two degrees were similar, but many students picked the latter because it didn’t require three semesters’ worth of study of a (human) language, such as French. I chose the former, because I like French.
An American university is organized like this, into divisions that are sometimes called colleges , and sometimes schools . These typically enjoy a good deal of independence to define their courses of study and requirements as well as research practices for their constituent disciplines. Included in this purview: whether a CS student really needs to learn French.
The positioning of computer science at USC was not uncommon at the time. The first academic departments of CS had arisen in the early 1960s, and they typically evolved in one of two ways: as an offshoot of electrical engineering (where transistors got their start), housed in a college of engineering; or as an offshoot of mathematics (where formal logic lived), housed in a college of the arts and sciences. At some universities, including USC, CS found its way into both places at once.
The contexts in which CS matured had an impact on its nature, values, and aspirations. Engineering schools are traditionally the venue for a family of professional disciplines, regulated with licensure requirements for practice. Civil engineers, mechanical engineers, nuclear engineers, and others are tasked to build infrastructure that humankind relies on, and they are expected to solve problems. The liberal-arts field of mathematics, by contrast, is concerned with theory and abstraction. The relationship between the theoretical computer scientists in mathematics and the applied ones in engineers is a little like the relationship between biologists and doctors, or physicists and bridge builders. Keeping applied and pure versions of a discipline separate allows each to focus on its expertise, but limits the degree to which one can learn from the other.
Read: Programmers, stop calling yourself engineers
By the time I arrived at USC, some universities had already started down a different path. In 1988, Carnegie Mellon University created what it says was one of the first dedicated schools of computer science. Georgia Institute of Technology followed two years later. “Computing was going to be a big deal,” says Charles Isbell, a former dean of Georgia Tech’s college of computing and now the provost at the University of Wisconsin-Madison. Emancipating the field from its prior home within the college of engineering gave it room to grow, he told me. Within a decade, Georgia Tech had used this structure to establish new research and teaching efforts in computer graphics, human-computer interaction, and robotics. (I spent 17 years on the faculty there, working for Isbell and his predecessors, and teaching computational media.)
Kavita Bala, Cornell University’s dean of computing, told me that the autonomy and scale of a college allows her to avoid jockeying for influence and resources. MIT’s computing dean, Daniel Huttenlocher, says that the speed at which computing evolves justifies the new structure.
But the computing industry isn’t just fast-moving. It’s also reckless. Technology tycoons say they need space for growth, and warn that too much oversight will stifle innovation. Yet we might all be better off, in certain ways, if their ambitions were held back even just a little. Instead of operating with a deep understanding or respect for law, policy, justice, health, or cohesion, tech firms tend to do whatever they want . Facebook sought growth at all costs, even if its take on connecting people tore society apart . If colleges of computing serve to isolate young, future tech professionals from any classrooms where they might imbibe another school’s culture and values—engineering’s studied prudence, for example, or the humanities’ focus on deliberation—this tendency might only worsen.
Read: The moral failure of computer scientists
When I raised this concern with Isbell, he said that the same reasoning could apply to any influential discipline, including medicine and business. He’s probably right, but that’s cold comfort. The mere fact that universities allow some other powerful fiefdoms to exist doesn’t make computing’s centralization less concerning. Isbell admitted that setting up colleges of computing “absolutely runs the risk” of empowering a generation of professionals who may already be disengaged from consequences to train the next one in their image. Inside a computing college, there may be fewer critics around who can slow down bad ideas. Disengagement might redouble. But he said that dedicated colleges could also have the opposite effect. A traditional CS department in a school of engineering would be populated entirely by computer scientists, while the faculty for a college of computing like the one he led at Georgia Tech might also house lawyers, ethnographers, psychologists, and even philosophers like me. Huttenlocher repeatedly emphasized that the role of the computing college is to foster collaboration between CS and other disciplines across the university. Bala told me that her college was established not to teach CS on its own but to incorporate policy, law, sociology, and other fields into its practice. “I think there are no downsides,” she said.
Mark Guzdial is a former faculty member in Georgia Tech’s computing college, and he now teaches computer science in the University of Michigan’s College of Engineering. At Michigan, CS wasn’t always housed in engineering—Guzdial says it started out inside the philosophy department, as part of the College of Literature, Science and the Arts. Now that college “wants it back,” as one administrator told Guzdial. Having been asked to start a program that teaches computing to liberal-arts students, Guzdial has a new perspective on these administrative structures. He learned that Michigan’s Computer Science and Engineering program and its faculty are “despised” by their counterparts in the humanities and social sciences. “They’re seen as arrogant, narrowly focused on machines rather than people, and unwilling to meet other programs’ needs,” he told me. “I had faculty refuse to talk to me because I was from CSE.”
In other words, there may be downsides just to placing CS within an engineering school, let alone making it an independent college. Left entirely to themselves, computer scientists can forget that computers are supposed to be tools that help people. Georgia Tech’s College of Computing worked “because the culture was always outward-looking. We sought to use computing to solve others’ problems,” Guzdial said. But that may have been a momentary success. Now, at Michigan, he is trying to rebuild computing education from scratch, for students in fields such as French and sociology. He wants them to understand it as a means of self-expression or achieving justice—and not just a way of making software, or money.
Early in my undergraduate career, I decided to abandon CS as a major. Even as an undergraduate, I already had a side job in what would become the internet industry, and computer science, as an academic field, felt theoretical and unnecessary. Reasoning that I could easily get a job as a computer professional no matter what it said on my degree, I decided to study other things while I had the chance.
I have a strong memory of processing the paperwork to drop my computer-science major in college, in favor of philosophy. I walked down a quiet, blue-tiled hallway of the engineering building. All the faculty doors were closed, although the click-click of mechanical keyboards could be heard behind many of them. I knocked on my adviser’s door; she opened it, silently signed my paperwork without inviting me in, and closed the door again. The keyboard tapping resumed.
The whole experience was a product of its time, when computer science was a field composed of oddball characters, working by themselves, and largely disconnected from what was happening in the world at large. Almost 30 years later, their projects have turned into the infrastructure of our daily lives. Want to find a job? That’s LinkedIn. Keep in touch? Gmail, or Instagram. Get news? A website like this one, we hope, but perhaps TikTok. My university uses a software service sold by a tech company to run its courses. Some things have been made easier with computing. Others have been changed to serve another end, like scaling up an online business.
Read: So much for ‘learn to code’
The struggle to figure out the best organizational structure for computing education is, in a way, a microcosm of the struggle under way in the computing sector at large. For decades, computers were tools used to accomplish tasks better and more efficiently. Then computing became the way we work and live. It became our culture, and we began doing what computers made possible, rather than using computers to solve problems defined outside their purview. Tech moguls became famous, wealthy, and powerful. So did CS academics (relatively speaking). The success of the latter—in terms of rising student enrollments, research output, and fundraising dollars—both sustains and justifies their growing influence on campus.
If computing colleges have erred, it may be in failing to exert their power with even greater zeal. For all their talk of growth and expansion within academia, the computing deans’ ambitions seem remarkably modest. Martial Hebert, the dean of Carnegie Mellon’s computing school, almost sounded like he was talking about the liberal arts when he told me that CS is “a rich tapestry of disciplines” that “goes far beyond computers and coding.” But the seven departments in his school correspond to the traditional, core aspects of computing plus computational biology. They do not include history, for example, or finance. Bala and Isbell talked about incorporating law, policy, and psychology into their programs of study, but only in the form of hiring individual professors into more traditional CS divisions. None of the deans I spoke with aspires to launch, say, a department of art within their college of computing, or one of politics, sociology, or film. Their vision does not reflect the idea that computing can or should be a superordinate realm of scholarship, on the order of the arts or engineering. Rather, they are proceeding as though it were a technical school for producing a certain variety of very well-paid professionals. A computing college deserving of the name wouldn’t just provide deeper coursework in CS and its closely adjacent fields; it would expand and reinvent other, seemingly remote disciplines for the age of computation.
Near the end of our conversation, Isbell mentioned the engineering fallacy, which he summarized like this: Someone asks you to solve a problem, and you solve it without asking if it’s a problem worth solving. I used to think computing education might be stuck in a nesting-doll version of the engineer’s fallacy, in which CS departments have been asked to train more software engineers without considering whether more software engineers are really what the world needs. Now I worry that they have a bigger problem to address: how to make computer people care about everything else as much as they care about computers.
This article originally mischaracterized the views of MIT’s computing dean, Daniel Huttenlocher. He did not say that computer science would be held back in an arts-and-science or engineering context, or that it needs to be independent.
Help | Advanced Search
Computer Science > Computer Vision and Pattern Recognition
Title: mcnet: a crowd denstity estimation network based on integrating multiscale attention module.
Abstract: Aiming at the metro video surveillance system has not been able to effectively solve the metro crowd density estimation problem, a Metro Crowd density estimation Network (called MCNet) is proposed to automatically classify crowd density level of passengers. Firstly, an Integrating Multi-scale Attention (IMA) module is proposed to enhance the ability of the plain classifiers to extract semantic crowd texture features to accommodate to the characteristics of the crowd texture feature. The innovation of the IMA module is to fuse the dilation convolution, multiscale feature extraction and attention mechanism to obtain multi-scale crowd feature activation from a larger receptive field with lower computational cost, and to strengthen the crowds activation state of convolutional features in top layers. Secondly, a novel lightweight crowd texture feature extraction network is proposed, which can directly process video frames and automatically extract texture features for crowd density estimation, while its faster image processing speed and fewer network parameters make it flexible to be deployed on embedded platforms with limited hardware resources. Finally, this paper integrates IMA module and the lightweight crowd texture feature extraction network to construct the MCNet, and validate the feasibility of this network on image classification dataset: Cifar10 and four crowd density datasets: PETS2009, Mall, QUT and SH_METRO to validate the MCNet whether can be a suitable solution for crowd density estimation in metro video surveillance where there are image processing challenges such as high density, high occlusion, perspective distortion and limited hardware resources.
Submission history
Access paper:.
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
Follow Polygon online:
- Follow Polygon on Facebook
- Follow Polygon on Youtube
- Follow Polygon on Instagram
Site search
- What to Watch
- What to Play
- PlayStation
- All Entertainment
- Dragon’s Dogma 2
- FF7 Rebirth
- Zelda: Tears of the Kingdom
- Baldur’s Gate 3
- Buyer’s Guides
- Galaxy Brains
- All Podcasts
Filed under:
- Entertainment
The 3-body problem is real, and it’s really unsolvable
Oh god don’t make me explain math
Share this story
- Share this on Facebook
- Share this on Reddit
- Share All sharing options
Share All sharing options for: The 3-body problem is real, and it’s really unsolvable
/cdn.vox-cdn.com/uploads/chorus_image/image/73224177/3_Body_Problem_n_S1_E4_00_26_53_00RC.jpg_3_Body_Problem_n_S1_E4_00_26_53_00RC.0.jpg "computer based problem solving")
Everybody seems to be talking about 3 Body Problem , the new Netflix series based on Cixin Liu’s Remembrance of Earth’s Past book trilogy . Fewer people are talking about the two series’ namesake: The unsolvable physics problem of the same name.
This makes sense, because it’s confusing . In physics, the three-body problem attempts to find a way to predict the movements of three objects whose gravity interacts with each of the others — like three stars that are close together in space. Sounds simple enough, right? Yet I myself recently pulled up the Wikipedia article on the three-body problem and closed the tab in the same manner that a person might stagger away from a bright light. Apparently the Earth, sun, and moon are a three-body system? Are you telling me we don’t know how the moon moves ? Scientists have published multiple solutions for the three-body problem? Are you telling me Cixin Liu’s books are out of date?
All I’d wanted to know was why the problem was considered unsolvable, and now memories of my one semester of high school physics were swimming before my eyes like so many glowing doom numbers. However, despite my pains, I have readied several ways that we non-physicists can be confident that the three-body problem is, in fact, unsolvable.
Reason 1: This is a special definition of ‘unsolvable’
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/25343152/3BP_103_Unit_03306RC.jpg_3BP_103_Unit_03306RC.jpg "computer based problem solving")
The three-body problem is extra confusing, because scientists are seemingly constantly finding new solutions to the three-body problem! They just don’t mean a one-solution-for-all solution. Such a formula does exist for a two-body system, and apparently Isaac Newton figured it out in 1687 . But systems with more than two bodies are, according to physicists, too chaotic (i.e., not in the sense of a child’s messy bedroom, but in the sense of “chaos theory”) to be corralled by a single solution.
When physicists say they have a new solution to the three-body problem, they mean that they’ve found a specific solution for three-body systems that have certain theoretical parameters. Don’t ask me to explain those parameters, because they’re all things like “the three masses are collinear at each instant” or “a zero angular momentum solution with three equal masses moving around a figure-eight shape.” But basically: By narrowing the focus of the problem to certain arrangements of three-body systems, physicists have been able to derive formulas that predict the movements of some of them, like in our solar system. The mass of the Earth and the sun create a “ restricted three-body problem ,” where a less-big body (in this case, the moon) moves under the influence of two massive ones (the Earth and the sun).
What physicists mean when they say the three-body problem has no solution is simply that there isn’t a one-formula-fits-all solution to every way that the gravity of three objects might cause those objects to move — which is exactly what Three-Body Problem bases its whole premise on.
Reason 2: 3 Body Problem picked an unsolved three-body system on purpose
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/25325944/3_Body_Problem_n_S1_E3_00_34_33_04RC.jpg_3_Body_Problem_n_S1_E3_00_34_33_04RC.jpg "computer based problem solving")
Henri Poincaré’s research into a general solution to the three-body problem formed the basis of what would become known as chaos theory (you might know it from its co-starring role in Jurassic Park ). And 3 Body Problem itself isn’t about any old three-body system. It’s specifically about an extremely chaotic three-body system, the exact kind of arrangement of bodies that Poincaré was focused on when he showed that the problem is “unsolvable.”
[ Ed. note: The rest of this section includes some spoilers for 3 Body Problem .]
In both Liu’s books and Netflix’s 3 Body Problem , humanity faces an invasion by aliens (called Trisolarans in the English translation of the books, and San-Ti in the TV series) whose home solar system features three suns in a chaotic three-body relationship. It is a world where, unlike ours, the heavens are fundamentally unpredictable. Periods of icy cold give way to searing heat that give way to swings in gravity that turn into temporary reprieves that can never be trusted. The unpredictable nature of the San-Ti environment is the source of every detail of their physicality, their philosophy, and their desire to claim Earth for their own.
In other words, 3 Body Problem ’s three-body problem is unsolvable because Liu wanted to write a story with an unsolvable three-body system, so he chose one of the three-body systems for which we have not discovered a solution, and might never.
Reason 3: Scientists are still working on the three-body problem
Perhaps the best reason I can give you to believe that the three-body problem is real, and is really unsolvable, is that some scientists published a whole set of new solutions for specific three-body systems very recently .
If physicists are still working on the three-body problem, we can safely assume that it has not been solved. Scientists, after all, are the real experts. And I am definitely not.
The next level of puzzles.
Take a break from your day by playing a puzzle or two! We’ve got SpellTower, Typeshift, crosswords, and more.
Sign up for the newsletter Patch Notes
A weekly roundup of the best things from Polygon
Just one more thing!
Please check your email to find a confirmation email, and follow the steps to confirm your humanity.
Oops. Something went wrong. Please enter a valid email and try again.
Loading comments...

All the House of the Dragon season 2 news we’ve heard so far

All the Gen V season 2 news we’ve heard so far

I didn’t like Sex and the City, and then I watched it

Honkai: Star Rail codes for April 2024

Pokémon Go Ditto disguises list for April 2024

What time does Modern Warfare 3 season 3 release?
IMAGES
VIDEO
COMMENTS
Computer-Based Problem Solving Process is a work intended to offer a systematic treatment to the theory and practice of designing, implementing, and using software tools during the problem solving process. This method is obtained by enabling computer systems to be more Intuitive with human logic rather than machine logic. Instead of software ...
Computer based problem solving is a systematic process of designing, implementing and using programming tools during the problem solving stage. This method enables the computer system to be more intuitive with human logic than machine logic. Final outcome of this process is software tools which is dedicated to solve the problem under consideration.
Computational thinking is a problem-solving process in which the last step is expressing the solution so that it can be executed on a computer. However, before we are able to write a program to implement an algorithm, we must understand what the computer is capable of doing -- in particular, how it executes instructions and how it uses data.
The problem solving cycle is a systematic approach to analyzing and solving problems, involving various stages such as problem identification, analysis, algorithm design, implementation, and evaluation. Understanding the importance of this cycle is essential for any computer scientist or programmer.
Computer science is similar to mathematics in that both are used as a means of defining and solving some problem. In fact, computer-based applications often use mathematical models as a basis for the manner in which they solve the problem at hand. In mathematics, a solution is often expressed in terms of formulas and equations. In
Computational Thinking allows us to take complex problems, understand what the problem is, and develop solutions. We can present these solutions in a way that both computers and people can understand. The course includes an introduction to computational thinking and a broad definition of each concept, a series of real-world cases that ...
Problem solving, in the simplest terms, is the process of identifying a problem, analyzing it, and finding the most effective solution to overcome it. For software engineers, this process is deeply embedded in their daily workflow. It could be something as simple as figuring out why a piece of code isn't working as expected, or something as ...
Whether you're exploring computer science for the first time or looking to deepen your understanding, this course will allow you to develop the problem-solving techniques you need to think like a computer scientist. Follow librarians, cooks, and mayors to see how computer science problem solving techniques affect their daily lives.
Problem solving with computers has, in consequence, become more demanding; instead of focusing on the problem when conceptualizing strategies to solve them, users are side-tracked by the pursuit of even more programming tools (as available).Computer-Based Problem Solving Process is a work intended to offer a systematic treatment to the theory ...
Take a guided, problem-solving based approach to learning Computer Science. These compilations provide unique perspectives and applications you won't find anywhere else. Computer Science Fundamentals
Problem solving with computers has, in consequence, become more demanding; instead of focusing on the problem when conceptualizing strategies to solve them, users are side-tracked by the pursuit of even more programming tools (as available).Computer-Based Problem Solving Process is a work intended to offer a systematic treatment to the theory ...
Complex Problem Solving (CPS) skills are essential to successfully deal with environments that change dynamically and involve a large number of interconnected and partially unknown causal influences. The increasing importance of such skills in the 21st century requires appropriate assessment and intervention methods, which in turn rely on adequate item construction, delivery, and scoring. The ...
For example, the problem solving assessment of PISA 2012, which is computer-based, used simulated real-life problem situations, such as a malfunctioning electronic device, to analyze students' reasoning skills, problem-solving ability, and problem-solving strategies. The computer-based assessment of problem solving not only ascertains whether ...
6. Discovery & Action Dialogue (DAD) One of the best approaches is to create a safe space for a group to share and discover practices and behaviors that can help them find their own solutions. With DAD, you can help a group choose which problems they wish to solve and which approaches they will take to do so.
The exclusion criteria include: a) "collaborative problem solving skills" is not investigated by the research; (b) the article is a conceptual or theoretical work, or an analysis of CPS behaviors or processes, or a review of existing studies; (c) no information on assessment is reported; and (d) computer-based technologies are not used in ...
determine the effect of Computer Based Problem Solving on High Level Thinking Skills (HOTS) of prospective teachers. The study was conducted in the 5th semester of the 2018/2019 academic year. This is a quasi-experiment with pre-test and post-test control group design consist. In the process of learning, the experimental group used computer ...
Contributors describe the most recent results and the most advanced methodological approaches relating to the application of the computer for encouraging knowledge construction, stimulating higher-order thinking and problem solving, and creating powerfullearning environments for pursuing those objectives. The computer applications relate to a ...
Computer-Based Problem Solving is a combination of problem-based learning and computer-assisted learning. The method facilitates students to use computer programs as cognitive tools to solve problems.
Successful computer-based assessments for learning greatly rely on an effective learner modeling approach to analyze learner data and evaluate learner behaviors. In addition to explicit learning performance (i.e., product data), the process data logged by computer-based assessments provide a treasure trove of information about how learners solve assessment questions. Unfortunately, how to make ...
Computer-based assessment. Problem solving. 1. Introduction. Advances in educational technology may enable the development of a more integrated conception of the array of assessment instruments tapping students' deep understanding while meeting the needs for public information and accountability-focused results.
Comparing Computer-Based Programs' Impact on Problem Solving Ability and Motivation . Hannah Doster, Josh Cuevas . Article Info Abstract Article History Received: 01 January 2021 ... Problem solving Computer-assisted instruction . Introduction. In elementary schools around the world, students are learning foundational mathematics concepts ...
This study focuses on computer-based formative assessment for supporting problem solving and reasoning in mathematics. To be able to assist students who find themselves in difficulties, the software suggested descriptions - diagnoses - of the encountered difficulty the students could choose from. Thereafter, the software provided ...
2. Computer-Based Assessment of CPS in PISA 2015. In PISA 2015, CPS is defined as a skill "(…) to effectively engage in a process whereby two or more agents attempt to solve a problem by sharing the understanding and effort required to come to a solution and pooling their knowledge, skills and efforts to reach that solution" [].To assess CPS on the fine-grained level of specific aspects ...
Produced by ElevenLabs and News Over Audio (NOA) using AI narration. Updated at 5:37 p.m. ET on March 22, 2024. Last year, 18 percent of Stanford University seniors graduated with a degree in ...
View PDF Abstract: Aiming at the metro video surveillance system has not been able to effectively solve the metro crowd density estimation problem, a Metro Crowd density estimation Network (called MCNet) is proposed to automatically classify crowd density level of passengers. Firstly, an Integrating Multi-scale Attention (IMA) module is proposed to enhance the ability of the plain classifiers ...
In other words, 3 Body Problem 's three-body problem is unsolvable because Liu wanted to write a story with an unsolvable three-body system, so he chose one of the three-body systems for which ...